Статья основана на 26 видео из 30 тем курса SQL c 0 от Аристова Евгения. Ссылки на видео на платформах RUTUBE и VK видео.
Общие сведения
Что такое индекс? Самый простой пример — оглавление книги.

Благодаря индексам можно получить ускоренный доступ к необходимой информации всего за несколько итераций (вместо полного перебора). В случае с книгой — мы ищем необходимую тему в оглавлении, а не листаем все страницы подряд.
Индекс сильно ускоряет поиск. Чем больше данных, тем быстрее работает индекс в сравнении с классическим перебором.
Плюсы индексов:
- Позволяют обеспечить уникальность (в PostgreSQL уникальность обеспечивается только через индекс)
- Ускоряют выборку в операциях SELECT
- При выборке данных только индексного поля, данные из таблицы не используются (индекс содержит ссылку на физические данные на диске, но если необходим только индекс, то эти данные не затрагиваются, что ускоряет работу)
- Увеличивает скорость сортировки по индексному полю
Минусы индексов:
- Индексы требуют дополнительного места
- Необходимо перестраивать индексы при операциях UPDATE, DELETE, INSERT (операция затратна по времени)
- При большом количестве индексов оптимизатору сложно выбрать какой использовать
Важно: большое количество индексов — плохая идея:
- Размер индексов может значительно превысить размер самой таблицы
- Скорость вставки/обновления/удаления обратно пропорциональна количеству индексов и по итогу может на порядок упасть
Синтаксис
Синтаксис создания индекса:
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ]
[ [ IF NOT EXISTS ] имя ] ON имятаблицы
[ USING метод ] (
{ имястолбца | ( выражение ) }
[ COLLATE правилосортировки ] [ классоператоров ]
[ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, …]
)
[ INCLUDE ( имя столбца [,…]) ] для Btree и Gist
[ WITH ( параметрхранения = значение [, … ] ) ]
[ TABLESPACE таблпространство ]
[ WHERE предикат ]UNIQUE - уникальный индекс
CONCURRENTLY - конкурентная постройка индекса, не влияющий на другие операции работы с таблицей (не требует эксклюзивной блокировки, использует параллельное исполнение)
IF NOT EXISTS - проверка на существование индекса
имя - имя индекса (может быть надо самим PostgreSQL, но хорошая практика - именовать самостоятельно, например с префиксом idx_*)
TABLESPACE - табличное пространство, где будет храниться индексВиды индексов
Виды индексов в PostgreSQL:
- Btree
- Hash
- GiST
- SP-GiST
- GIN
- BRIN
Несмотря на большое количество разных индексов в PostgreSQL, Битри (Btree) или сбалансированное дерево используется в 99% случаев. Также он будет использован по умолчанию, если не указать тип индекса.
Btree
Применим для любого типа, который можно отсортировать в чётко определённом линейном порядке.
Умеет работать с большим количеством операцией — с операторами сравнения >, <, =, >=, <=, BETWEEN и IN, условиями пустоты IS NULL и IS NOT NULL.
Данный индекс простой и оптимизированный, работает быстро — сложность O(log n) (Вычислительная сложность)
Btree строит дерево по отсортированному массиву (каждый уровень отсортирован). Именно благодаря сортировке работают все операторы сравнения.
Рассмотрим поиск по неравенству <=38. Спускаемся по этапам вниз (больше 14 идем вправо, от 32 до 44 идем в 3 лист) и получаем все данные (по зеленой стрелке) в отсортированном виде. Если бы нужно было просто равенство — то сразу бы нашли искомую ячейку.
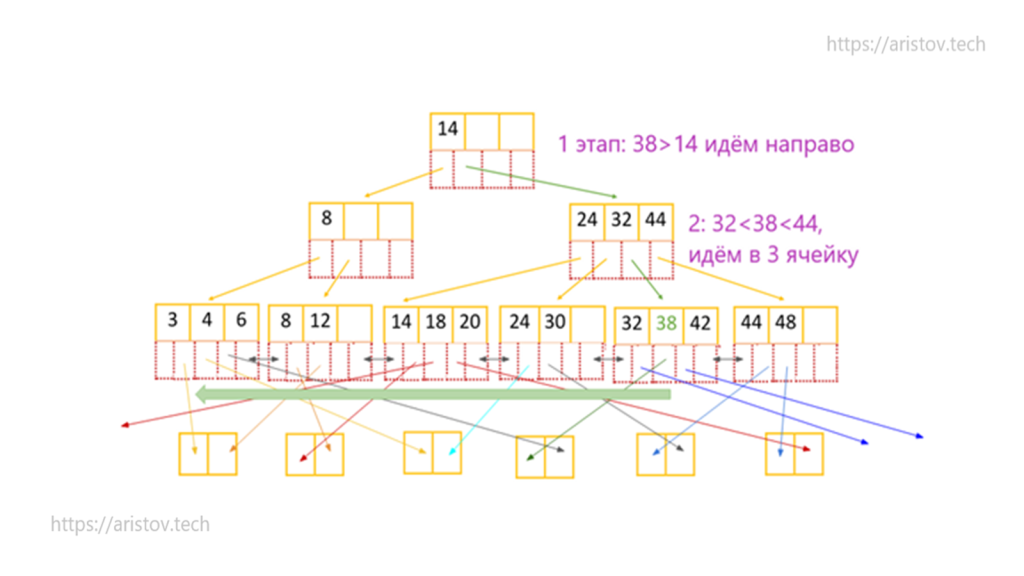
На нижнем уровне (на листьях) для каждого конкретного значения хранится ссылка на физические данные на диске.
На самом деле у нас под капотом используется Btree+ (или B+tree дерево). В отличие от Btree, есть связь между листьями, что удобно использовать для операций сравнения.
Начиная с 13 версии Postgresql появилась дедупликация, благодаря которой Btree может весить меньше.
Минусы:
- Если при очередном добавлении/изменении/удалении значения требуется перебалансировка дерева, то это занимает много времени. Именно поэтому изначально плотность заполнения 90% (имеются пустые ячейки)
- Необходимо обслуживать индексы (они постоянно растут в объеме, аналогично с обычными данными)
- Работает хорошо только с простыми типами данных (числа, даты, денежные)
- Работает со строками, только если ищем по шаблону (like) с начала строки (%АБВ).
Хэш-индекс (hash)
В теории работает быстрее Btree.
Работает только с условием равенства (=). В условиях IS NULL и IS NOT NULL не используется.
Hash индекс построен на корзинах (bucket), в которых после операции хэширования хранятся данные. Корзины одинаково заполнены — данные по ним распределены равномерно.
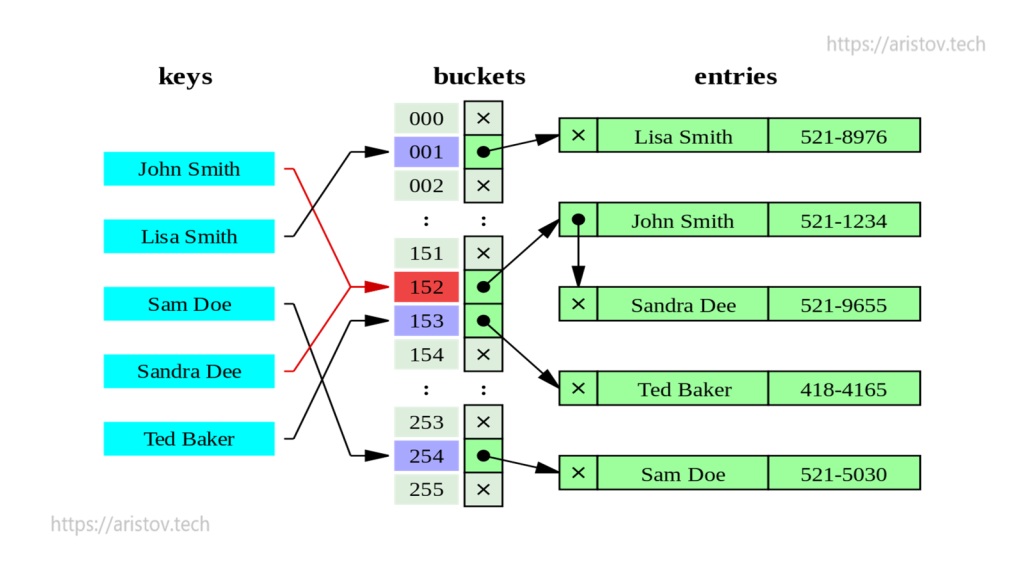
Так как при хэшировании разные данные могут давать одинаковый результат, при поиске происходит спуск в корзину и перебор всех значений в ней.
Сложность поиска гораздо ниже, чем у Btree. По сути, он происходит за одну операцию. Однако использовать этот индекс можно только для равенства.
GIN
GIN (Generalized Inverted Index) — обобщённый инвертированный индекс.
Применяется к составным типам, работа с которыми осуществляется с помощью ключей: массивы, jsonb.
Предназначен для случаев, когда индексируемые значения являются составными, а запросы ищут значения элементов в этих составных объектах.
GiST
GiST (Generalized Search Tree) — обобщённое поисковое дерево.
Базовый шаблон, на основе которого могут реализовываться произвольные схемы индексации.
Для построения использует один из нескольких алгоритмов, наиболее подходящих под тип индексируемого поля, поэтому набор операторов зависит от типа поля.
Применяется для специфических типов данных: геометрия, сетевые адреса, диапазоны.
Для построения вектора слов используются функции tsvector или tsquery.
Самый распространённый вариант использования индексов GIN & GiST — полнотекстовый поиск по аналогии с Google/Yandex. Они сравнимы с алфавитным указателем.

SP-GiST
SP-GiST (Space-Partitioned GiST) — GiST с разбиением пространства.
Метод поддерживает деревья поиска с разбиением, что позволяет работать с различными сложными несбалансированными структурами данных (деревья квадрантов, k-мерные и префиксные деревья).
Как и GiST, SP-GiST позволяет разрабатывать дополнительные типы данных с соответствующими методами доступа.
BRIN
BRIN (block range index) — блоковый индекс.
Добавлен с 11 версии.
Постранично раскладывает данные по времени. Подробнее об устройстве BRIN.
В отличие от остальных индексов, BRIN используется не для того, чтобы быстро найти нужные строки, а для того, чтобы избежать просмотра заведомо ненужных. Это неточный индекс — он не содержит TID-ов табличных строк.
Нужен для больших объемов, где физическое расположение коррелирует со значением.
Используется в таблицах логирования, GPS трекинга, IoT.
Типы индексов
Помимо видов индексов существуют ещё и типы (в каком виде строится индекс)
Типы индексов:
- Простой индекс
- Уникальный индекс
- Составной индекс (по нескольким полям сразу — строится дерево по первому полю, а в каждом листе находится дерево по второму полю)
- Покрывающий индекс (на нижнем уровне содержит не только ссылку на данные, но и сами данные)
- Функциональный индекс (можно использовать свою функцию, ее тип должен быть IMMUTABLE)
- Частичный индекс (используется для поиска по небольшому диапазону данных).
Explain
EXPLAIN показывает план запроса для его оценки.
Синтаксис:
EXPLAIN [ ( параметр [, …] ) ] оператор
Параметры:
ANALYZE [ boolean ]
VERBOSE [ boolean ]
COSTS [ boolean ]
SETTINGS [ boolean ]
BUFFERS [ boolean ]
WAL [ boolean ]
TIMING [ boolean ]
SUMMARY [ boolean ]
FORMAT { TEXT | XML | JSON | YAML }При EXPLAIN строится только план запроса, но если указать ANALYZE, то запрос ещё и выполняется (ANALYZE выводит время выполнения).
Обратите внимание, что EXPLAIN считает только приблизительную стоимость запроса в условных единицах, которая часто может не совпадать с реальной.
Подробнее об этапах выполнения запроса.
Сервис для визуального построения запроса.
Полезные статьи:
- EXPLAIN сложных операций
- Как реляционная СУБД делает JOIN?
- Queries in PostgreSQL. Sort and merge
- История Merge
- Queries in PostgreSQL. Hashing
- Using EXPLAIN
- Query Planning
- Как повлиять на планировщик
Практика
Рассмотрим функцию для генерации данных generate_series.
Для этого создадим таблицу:
CREATE TABLE testindex (
a int,
b int
);И вставим в неё значения:
INSERT INTO testindex
SELECT i, i*2
FROM generate_series(1,100000) s(i);Выведем первые 10 строк:
SELECT * FROM testindex LIMIT 10;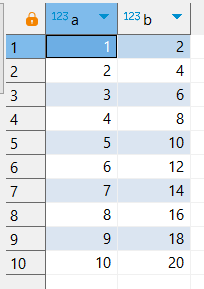
Создадим таблицу с данными:
CREATE TABLE test AS
SELECT generate_series AS id
, generate_series::text || (random() * 10)::text AS col2
, (array[‘Da’, ‘Net’, ‘Ne znayu’])[floor(random() * 3 + 1)] AS is_okay
FROM generate_series(1, 20000);
Таблица содержит 20000 строк такого вида:
Выполним поиск по таблице:
SELECT *
FROM test
WHERE id = 1;
C помощью EXPLAIN посмотрим, как выполняется запрос:
EXPLAIN
SELECT *
FROM test
WHERE id = 1;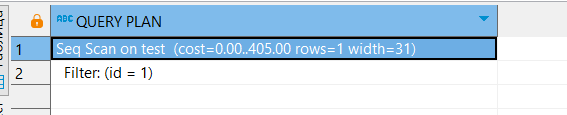
Видим, что было произведено последовательное сканирование.
Теперь создадим индекс для поля id:
CREATE INDEX idx_test_id
ON test(id);И выполним запрос заново:
EXPLAIN
SELECT *
FROM test
WHERE id = 1;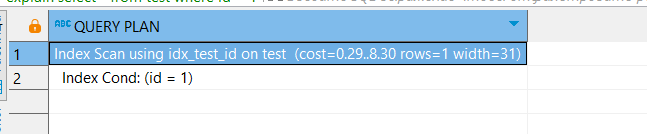
Теперь сканирование происходит по индексу, что позволяет ускорить операцию в разы.
Сделаем наш индекс уникальным:
ALTER TABLE test
ADD CONSTRAINT uk_test_id UNIQUE(id);Добавление ограничения уникальности на уже существующий индекс — то же самое, что и создания уникального индекса:
CREATE UNIQUE INDEX idx_test_id
ON test(id);Напоминаю, что NULL!=NULL, поэтому можно добавить две строки с id равным NULL:
INSERT INTO test VALUES
(null, 12, 'First');
INSERT INTO test VALUES
(null, 12, 'SEcond');Сделаем выборку:
SELECT *
FROM test
WHERE id IS NULL;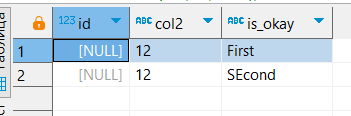
Чтобы индекс был действительно уникальным, нужно добавлять ограничение NOT NULL (таким образом получится PRIMARY KEY).
Создадим таблицу заново с составным индексом:
CREATE TABLE test AS
SELECT generate_series AS id
, generate_series::text || (random() * 10)::text AS col2
, (array['Apple', 'Banana', 'Pinaapple'])[floor(random() * 3 + 1)] AS fruit
FROM generate_series(1, 100000);
CREATE INDEX idx_test_id_is_okay
ON test(id, fruit);
При выборке по двум полям происходит индексное сканирование:
EXPLAIN
SELECT *
FROM test
WHERE id = 1 AND fruit = 'Banana';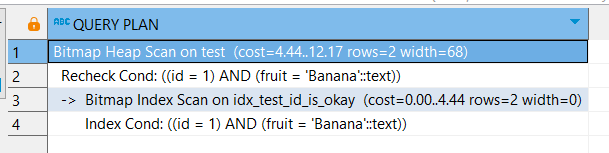
Мы спускаемся до листа дерева, построенного по первому полю, а затем внутри листа спускаемся по внутреннему дереву (для второго поля).
Аналогично индексное сканирование будет применено при поиске только по первому полю:
EXPLAIN
SELECT *
FROM test
WHERE id = 1;
А при поиске только по второму будет использовано обычное сканирование, так как отдельного дерева только на второе поля у нас нет:
EXPLAIN ANALYZE
SELECT *
FROM test
WHERE fruit = 'Banana';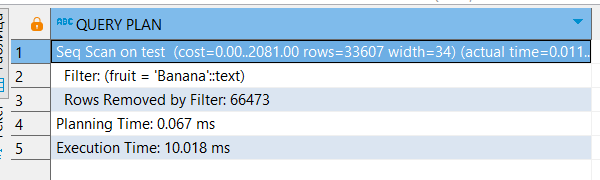
Можно принудительно отключить последовательное сканирование:
SET enable_seqscan=off;Теперь выполним тот же запрос:
EXPLAIN ANALYZE
SELECT *
FROM test
WHERE fruit = 'Banana';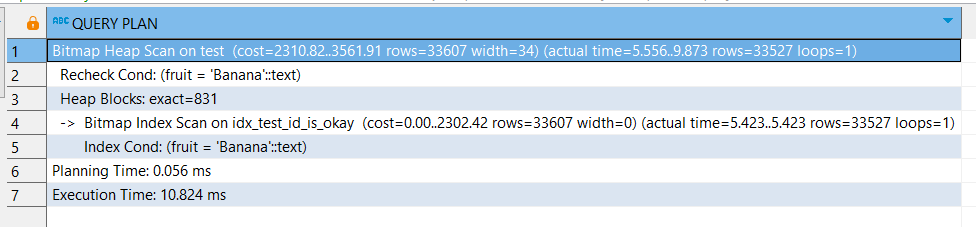
Сканирование по индексам заняло столько же времени, но больше условных единиц (поэтому PostgreSQL и выбирал последовательное сканирование).
Ещё можно настроить параметр random_page_cost, чтобы PostgreSQL корректнее оценивал стоимость обращения к диску за данными и реже использовал последовательное сканирование:
SET random_page_cost=1.1;
Индексное сканирование также используется при сортировке, но только если она осуществляется по двум полям в одинаковом направлении.
Оба по возрастанию:
EXPLAIN
SELECT *
FROM test
ORDER BY id, fruit;
Оба по убыванию:
EXPLAIN
SELECT *
FROM test
ORDER BY id DESC, fruit DESC;
В разные стороны (обычное сканирование):
EXPLAIN
SELECT *
FROM test
ORDER BY id, fruit DESC;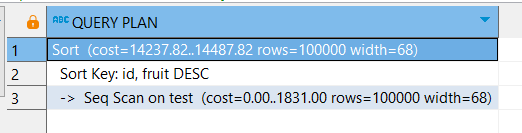
Пересоздадим индекс. Теперь это будет покрывающий индекс:
CREATE INDEX idx_test_id_is_okay
ON test(id) INCLUDE (fruit);
Покрывающий индекс хранится в неотсортированном виде рядом со значением, поэтому он не используется при сортировке:
EXPLAIN
SELECT *
FROM test
ORDER BY id DESC, fruit DESC;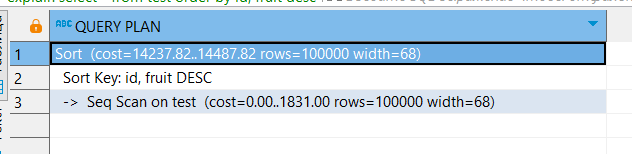
Но он используется при отборе по значению:
EXPLAIN
SELECT *
FROM test
WHERE id = 1 AND fruit = 'Banana';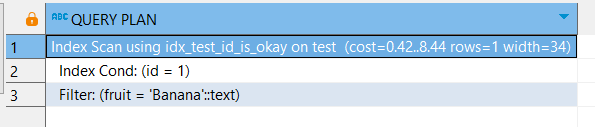
Создадим таблицу заново с функциональным индексом:
CREATE TABLE test AS
SELECT generate_series AS id
, generate_series::text || (random() * 10)::text AS col2
, (array['BaNaNa', 'Mushroom', 'Coconut'])[floor(random() * 3 + 1)] AS fruit
FROM generate_series(1, 50000);
CREATE INDEX idx_test_id_is_okay
ON test(lower(fruit));Теперь проведем поиск:
EXPLAIN
SELECT *
FROM test
WHERE lower(fruit) = 'banana';
Обратите внимание, что для использования индексного сканирования при функциональном индексе, функция в запросе обязательно должна совпадать с функцией в самом индексе.
Запрос без функции выполняется через последовательное сканирование:
EXPLAIN
SELECT *
FROM test
WHERE fruit = 'banana';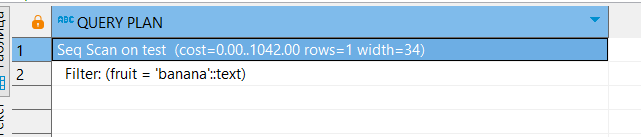
И такой запрос ничего не найдет, так как исходные строки хранятся без изменений в другом регистре:
Пересоздадим таблицу с частичным индексом:
CREATE TABLE test AS
SELECT generate_series AS id
, generate_series::text || (random() * 10)::text AS col2
, (array['Oops', 'Bad', 'False'])[floor(random() * 3 + 1)] AS bad
FROM generate_series(1, 500000);
CREATE INDEX idx_test_id_100
ON test(id) WHERE id < 100;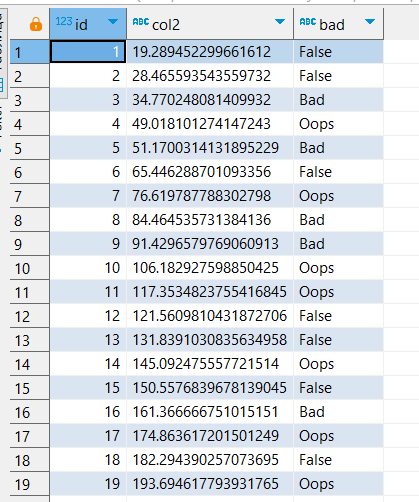
Такой индекс может быть нужен, если хранятся данные о клиентах. Первые 100 человек — постоянные клиенты, а остальные — одноразовые покупатели, на которых нет смысла создавать индекс.
Если искать не по индексному полю, то увидим обычное последовательное сканирование:
EXPLAIN
SELECT *
FROM test
WHERE bad = 'Oops;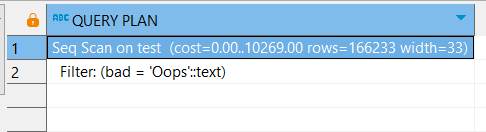
Аналогично со значениям извне диапазона:
EXPLAIN ANALYZE
SELECT *
FROM test
WHERE id = 100;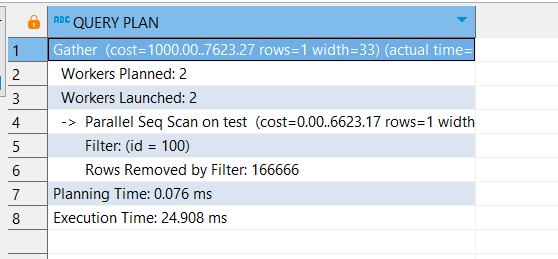
При поиске по id из диапазона используются индексы:
EXPLAIN ANALYZE
SELECT *
FROM test
WHERE id = 99;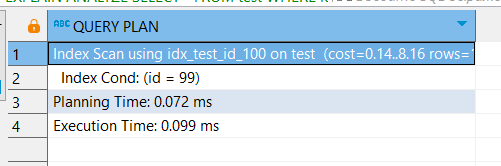
Такой запрос гораздо быстрее предыдущего.
Презентация к статье здесь.
27 из 30 тем будет скоро доступна. Если вы хотите быстрее получить доступ – присоединяйтесь к онлайн группе, ссылка доступна в описании курса.
Добавить комментарий