Статья основана на материалах открытого вебинара “Troubleshooting PostgreSQL Indexes”. Запись занятия доступна в youtube, rutube и VK Видео.
Презентация доступна по ссылке.
На лекции разобрали принципы работы индексов, особенности массовой вставки данных в PostgreSQL. Детально изучили, когда индексы не работают. Рассмотрели тонкости построения секционированных индексов и кластерный индекс.
Проблематика
Основные проблемы индексов:
- После создания они не используются
- Замедление вставки
- Не использование при массовой вставке
- Утечка памяти
- Падение скорости запросов
В статье будут рассмотрены индексы Btree ( в PostgreSQL реализация Btree+), так как они составляют 99% всего использования индексов. Они работают не только на сравнение (диапазон), но и на сортировку.
Подробнее о всех видах индексов в моей статье.
Действия над индексами
Рассмотрим поиск числа 38 на дереве Btree+. От корня до искомого листа доходим за четыре сравнения.
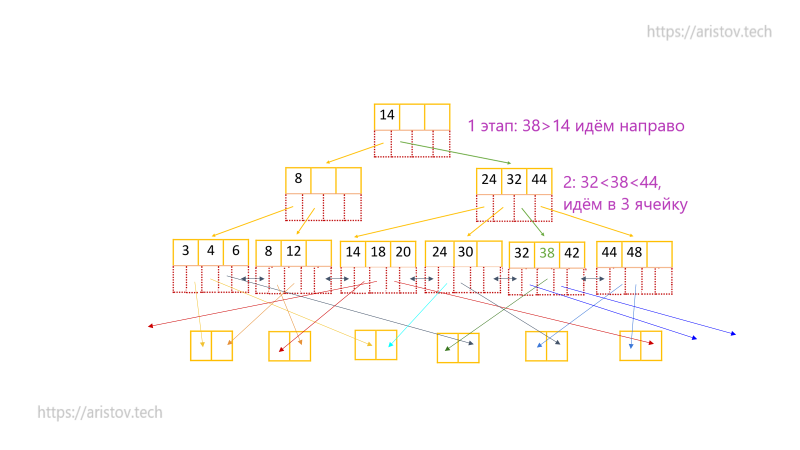
Итого — стандартное сбалансированное дерево, в корне сравниваем числа и уходим направо. Таким итерационным сравнением быстро находим искомое чисто уже на уровне листьев.
Рассмотрим поиск по неравенству <38.
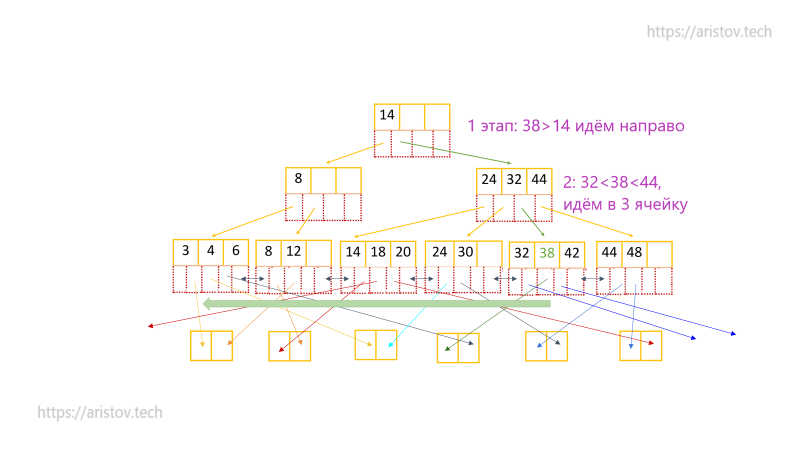
Здесь пример более интересный, так как из-за особенностей архитектуры на нижнем уровне — уровне листьев, все данные отсортированы, мы можем просто переместиться по горизонтали и получить отсортированный массив нужного диапазона!
При этом в отличии от Btree простого дерева, где для нахождения соседних листьев, необходимо подняться на уровень выше, в PostgreSQL используется улучшенный Btree+ алгоритм, который на уровне листьев содержит ссылки и на предыдущий и последующий лист.
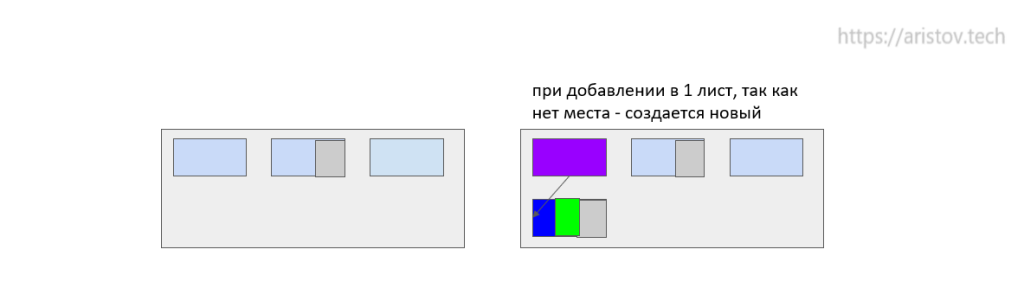
Пример добавления значения в Btree+. При создании индексов заполняется только 90% мест, 10% остаются свободны. Это сделано во избежание излишней перебалансировки. При добавлении значения 20, оно занимает свободное пространство. А при добавлении 13 создается новая ячейка, ссылка и осуществляется перебалансировка.
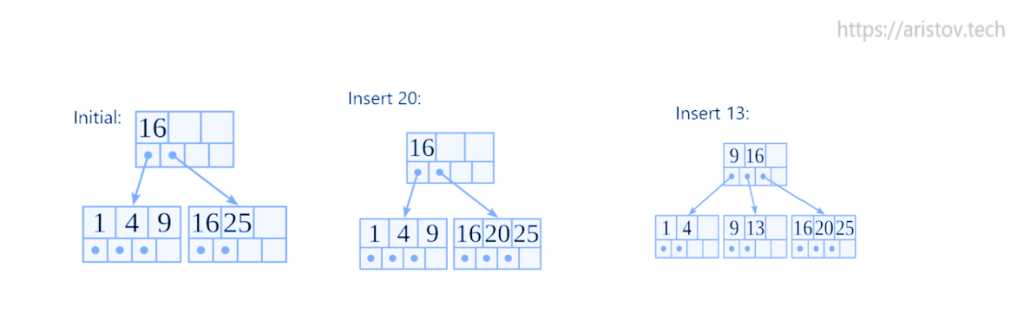
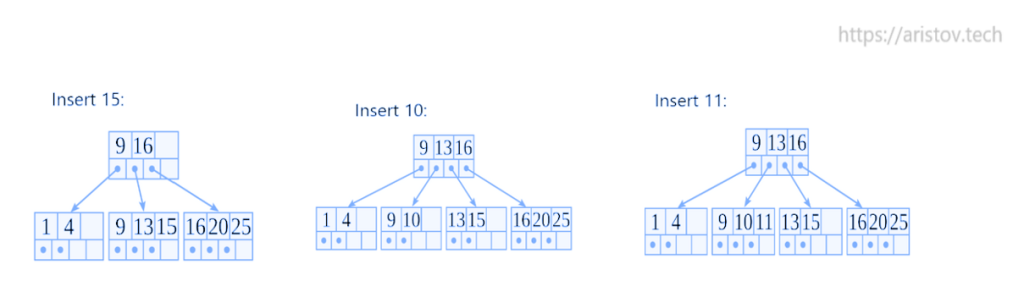
При рассматриваемых размерах дерева перебалансировка не затратна, но в реальной ситуации на больших деревьях, она затратна по ресурсам.
Физически процесс происходит так: при попытке добавить ячейку в первый, уже занятый лист, добавляется ссылка на следующий лист, туда помещаются данные.
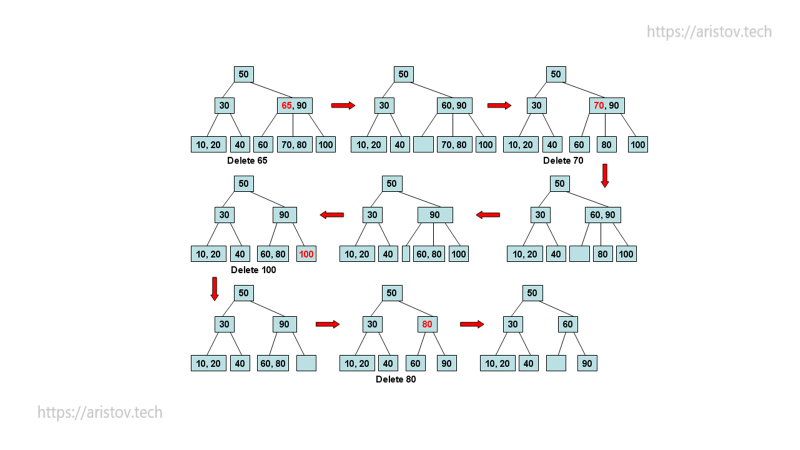
Удаление значений происходит не всегда тривиальным путем. При удалении значения 65 его место занимает значение 60. Далее происходит перебалансировка. При удалении 70 образуется пустая ячейка, снова происходит перебалансировка.
Типы индексов
- Простой индекс
- Уникальный индекс
- Составной индекс
- Покрывающий индекс (появился в 11 версии)
- Функциональный индекс (можно использовать свою функцию, ее тип должен быть IMMUTABLE)
- Частичный индекс
Особенность уникального индекса
Уникальный индекс обязательно должен быть объявлен как NOT NULL, иначе можно будет добавлять сколько угодно NULL значений, потому что в PostgreSQL NULL <> NULL
Создадим таблицу fk1002_2 с уникальным CONSTRAINT, который не объявлен как NOT NULL. CONSTRAINT уникальности и уникальный индекс реализуются оба через уникальный индекс.
CREATE TABLE fk1002_2(
id integer,
CONSTRAINT fk1002_2_unique UNIQUE (id)
);Теперь добавляем значения и видим, что можно добавить одинаковые NULL строки:
INSERT INTO fk1002_2 VALUES
(10),
(20),
(NULL),
(NULL);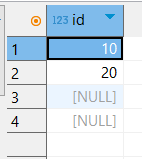
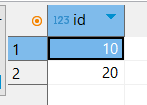
Очистим таблицу, создадим её заново без NULL значений.
DROP TABLE IF EXISTS fk1002_2;CREATE TABLE fk1002_2(
id integer,
CONSTRAINT fk1002_2_unique UNIQUE (id)
);
INSERT INTO fk1002_2 VALUES
(10),
(20);
Создадим вторую таблицу, в которой внешний ключ ссылается на первичный ключ исходной таблицы.
CREATE TABLE fk1002_2_fk(
fk1002_2_id integer,
CONSTRAINT fk1002_2_fk_fk1002_2 FOREIGN KEY (fk1002_2_id) REFERENCES fk1002_2(id)
);Теперь добавляем значения во внешний ключ:
INSERT INTO fk1002_2_fk VALUES
(10),
(20),
(NULL),
(NULL);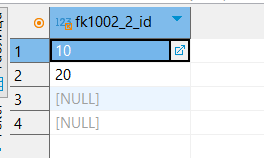
Внешний ключ работает так, что его значение обязательно должно присутствовать в родительской таблице. В данном случае ошибки не возникает, хотя значения некорректны, так как поле не объявлено NOT NULL.
Очистим обе таблицы и создадим их заново.
DROP TABLE IF EXISTS fk1002_2_fk;
DROP TABLE IF EXISTS fk1002_2;Таблица fk1002_2 с составным ключом (id, value):
CREATE TABLE fk1002_2(
id integer NOT NULL,
value varchar(10),
CONSTRAINT fk1002_2_unique UNIQUE (id, value)
);Таблица fk1002_2_fk, у которой внешний ключ ссылается на составное значение в первой таблице:
CREATE TABLE fk1002_2_fk(
fk1002_2_id integer NOT NULL,
fk1002_2_value varchar(10),
CONSTRAINT fk1002_2_fk_fk1002_2 FOREIGN KEY (fk1002_2_id, fk1002_2_value) REFERENCES fk1002_2(id, value)
);Вставляем первичные ключи:
INSERT INTO fk1002_2 (id, value) VALUES
(10, NULL);
INSERT INTO fk1002_2 (id, value) VALUES
(20, '20');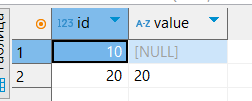
Вставляем внешние ключи:
INSERT INTO fk1002_2_fk (fk1002_2_id, fk1002_2_value) VALUES
(20, '20');
INSERT INTO fk1002_2_fk (fk1002_2_id, fk1002_2_value) VALUES
(30, NULL);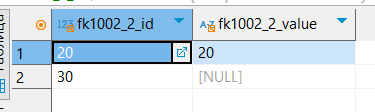
Во внешний ключ мы добавили значение 30, не существующее в родительской таблице, ошибок не возникло.
Во избежание таких ситуаций, всегда объявляйте уникальный индекс NOT NULL!
Особенность уникального CONSTRAINT
Что такое CONSTRAINT читайте в моей статье.
Создание уникального индекса аналогично объявлению уникального CONSTRAINT за одним отличием:
DEFERRABLE
NOT DEFERRABLE (default)Этот параметр определяет, может ли ограничение быть отложенным. Неоткладываемое ограничение будет проверяться немедленно после каждой команды.
Проверка откладываемых ограничений может быть отложена до завершения транзакции (обычно с помощью команды SET CONSTRAINTS).
В настоящее время этот параметр принимают только ограничения UNIQUE, PRIMARY KEY, EXCLUDE и REFERENCES (внешний ключ).
Откладываемые ограничения не могут применяться в качестве решающих при конфликте в операторе.
INSERT с предложением ON CONFLICT DO UPDATE.
Еще одна особенность ограничений при выборе DEFERRABLE — поведение по умолчанию:
INITIALLY IMMEDIATE (default)
INITIALLY DEFERREDОграничение с характеристикой INITIALLY IMMEDIATE проверяется после каждого оператора, позволяет включить в транзакции режим проверки в конце.
Ограничение INITIALLY DEFERRED, напротив, позволяет отключить режим проверки в конце транзакции в каждой транзакции.
Deferrable Constraints in PostgreSQL | Christian Emmer
Особенность GIN индекса
У GIN-индекса есть параметр хранения fastupdate, который можно указать при создании индекса или изменить позже:
CREATE INDEX ON ts USING gin(doc_tsv)
with (fastupdate = true);При включенном параметре изменения будут накапливаться в виде отдельного неупорядоченного списка (в отдельных связанных страницах). Когда этот список становится достаточно большим, либо при выполнении процесса очистки, все накопленные изменения одномоментно вносятся в индекс. Что считать «достаточно большим» списком, определяется конфигурационным параметром gin_pending_list_limit или одноименным параметром хранения самого индекса.
Недостатки:
- замедляется поиск (за счет того, что кроме дерева приходится просматривать еще и неупорядоченный список)
- очередное изменение может внезапно занять много времени, если неупорядоченный список переполнился
Больше индексов — лучше?
Во многих статьях предлагается создавать индексы на все поля для ускорения работы запросов.
Однако:
- Размер индексов может превысить размер самой таблицы и при этом значительно
- Индексы желательно держать в памяти для скорости работы, а не на диске
- Скорость вставки/обновления/удаления обратно пропорциональна количеству индексов и по итогу может на порядок упасть
Большое количество индексов может быть эффективно при наличии, например, только OLAP нагрузки.
Случаи, когда индексы в PostgreSQL могут не работать
Берем небольшую таблицу на ~200 млн. записей Чикагское такси в BigQuery (публичный датасет).
Посчитаем, сколько всего данных в наборе:
SELECT count(*)
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`;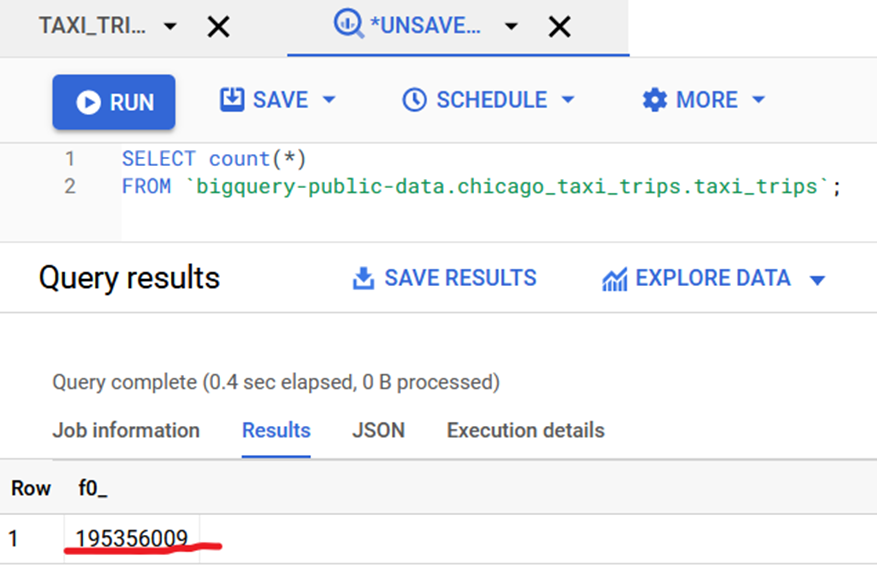
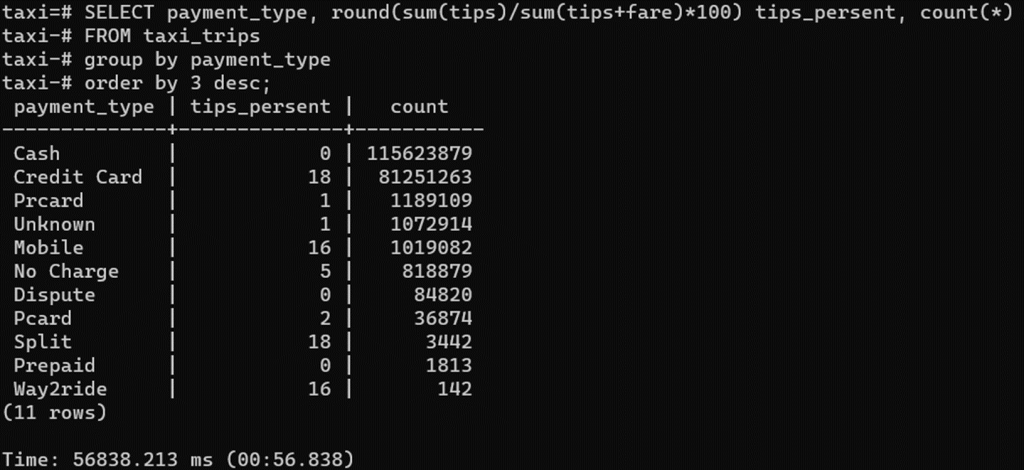
Попробуем посчитать агрегирующий отчёт — сумма чаевых по типам чаевых. Нужно перебрать все записи и выбрать нужные данные, затрачивается при этом всего 0.9 секунды:
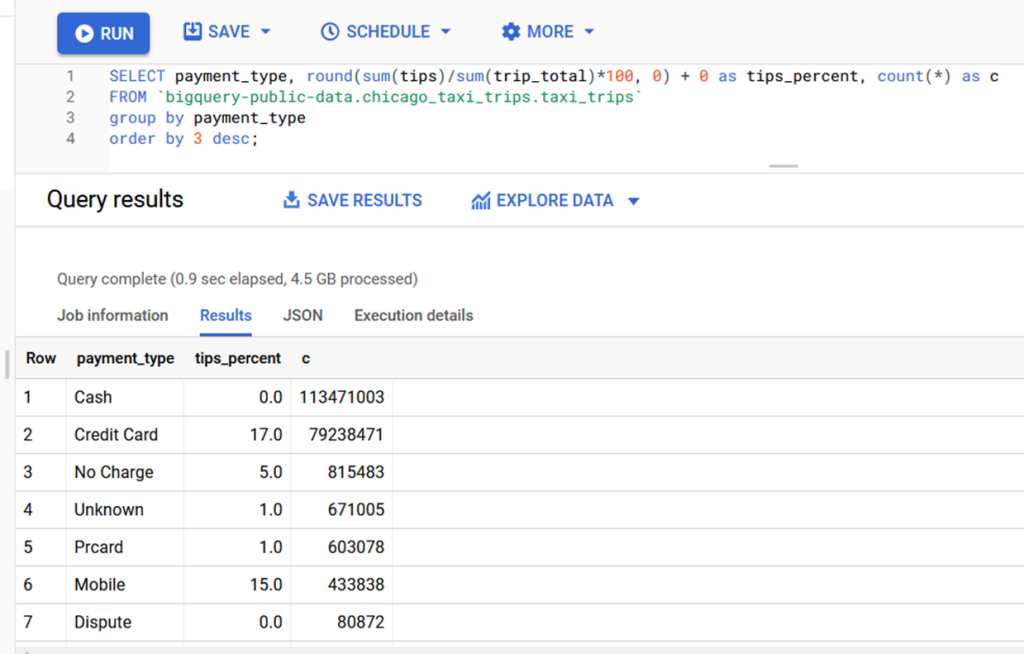
Теперь посчитаем аналогичные запросы в нашем PostgreSQL.
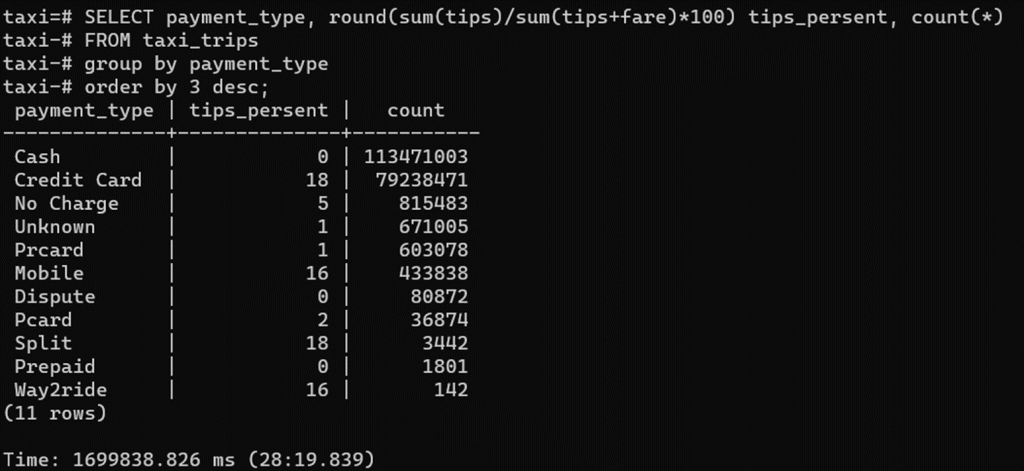
Этот же отчет считается 30 МИНУТ.
Индексы по отдельным полям как и тюнинг PostgreSQL нам не помогут, мы просто упремся в дисковую подсистему.
Решением проблемы может стать составной индекс.
CREATE INDEX idx_taxi
ON taxi_trips(payment_type, tips, fare);Время создания:
Time: 1370972.471 ms (22:50.972)Также с 11 версии PostgreSQL можно использовать покрывающий индекс:
CREATE INDEX idx_taxi2
ON taxi_trips(payment_type) include (tips, fare);Время создания:
Time: 932280.011 ms (15:32.280)Отличие в том, что у составного индекса будет составлено бинарное дерево по payment_type, далее в каждом листе ещё дерево по tips и, аналогично, ещё одно по fare. Это дороже по памяти и времени, чем покрывающий индекс. У него, в свою очередь, создается только дерево по payment_type, а остальные два поля просто лежат рядом в индексе. Нет никакой сортировки.
Рассмотрим план запроса:
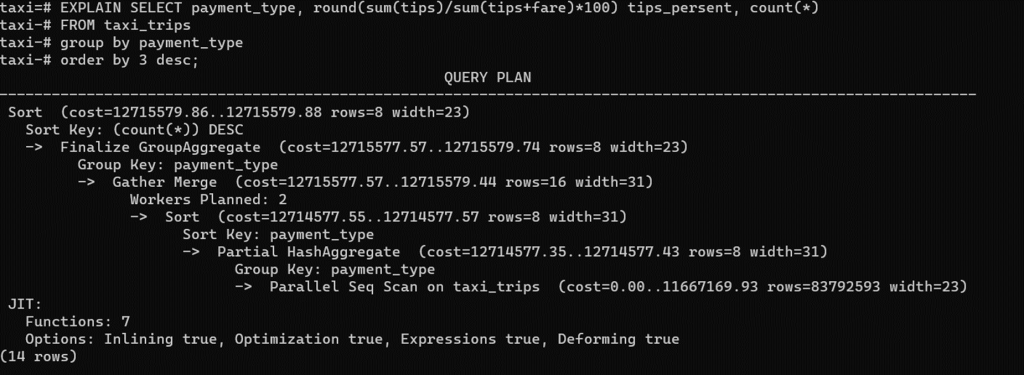
Видим, что используется Seq Scan, хоть индексы уже созданы.
Соберем статистику:
ANALYZE taxi_trips;
Time: 3057.809 ms (00:03.058)Далее отключим Seq Scan:

Теперь запрос выполняется на индексах, однако сложность значительно выросла, как и время выполнения.
Отключение JIT и другие варианты не помогают.
Ответ в документации:
After adding or deleting a large number of rows, it might be a good idea to issue a VACUUM ANALYZE command for the affected table. This will update the system catalogs with the results of all recent changes, and allow the PostgreSQL query planner to make better choices in planning queries.
То есть после массовой загрузки данных нужно провести VACUUM ANALYZE, которых создаст карту видимости для данных.
После этого запрос выполняется через Parallel index Scan:
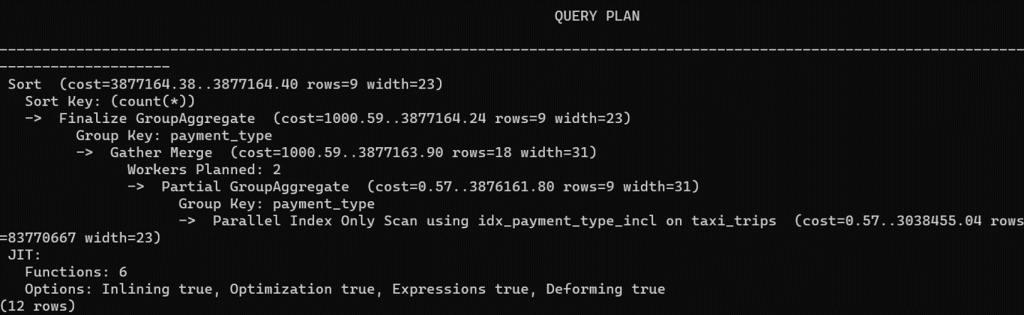
Время выполнения сократилось до 1 минуты:
Потренироваться можно по ссылке.
Так что для нашего варианта можно:
- использовать cstore_fdw
- предагрегаты (для подсчета статистики)
- мат. представления
- триггеры
- clickhouse
Также индексы могут не работать:
- слишком мало данных в таблице (например, справочник) и PostgreSQL быстрее извлечь все данные в память, чем бегать туда сюда
- используется функциональный индекс, но не совпадает количество или тип аргументов у функции
- используется составной индекс, но поиск (сортировка) ведется только по второму и дальнейшим ключам. Есть исключение, когда индекс намного меньших размеров, чем общее количество данных.
- используется покрывающий индекс при наличии предыдущих ключей в запросе при сортировке второго и дальнейших полей
- несоответствие кодировок
- индекс НЕвалидный (сломался или недостроился)
- по этому полю/полям уже есть аналогичный индекс
На что стоит обратить внимание
Не применяйте частичные индексы в качестве замены секционированию!
Возможно создание множества неперекрывающихся частичных индексов, например:
CREATE INDEX mytable_cat_1 ON mytable (data) WHERE category = 1;
CREATE INDEX mytable_cat_2 ON mytable (data) WHERE category = 2;
CREATE INDEX mytable_cat_3 ON mytable (data) WHERE category = 3;
…
CREATE INDEX mytable_cat_N ON mytable (data) WHERE category = N;Так делать не следует, так как придется поддерживать актуальность n индексов. Следует использовать один составной индекс:
CREATE INDEX mytable_cat_data ON mytable (category, data);Кластерный индекс
Классический пример реализации в MSSQL:

Кластерный индекс может быть только один на таблицу, в соответствие с ним данные расположены на диске. В результате кластеризации таблицы её содержимое физически переупорядочивается в зависимости от индекса. Смысл в том, что корень сразу дает понять, на какой странице диска находятся данные. Преимущество этого индекса — более быстрый доступ.
В PostgreSQL кластерный индекс не работает. Кластеризация является одноразовой операцией из-за работы механизма MVCC: последующие изменения в таблице нарушают порядок кластеризации. Также процесс требует эксклюзивной блокировки, а значит update/insert/delete в это время работать не будут.
При индексации используйте конкурентный вариант операции. Иначе построение/перестройка индекса требует эксклюзивной блокировки
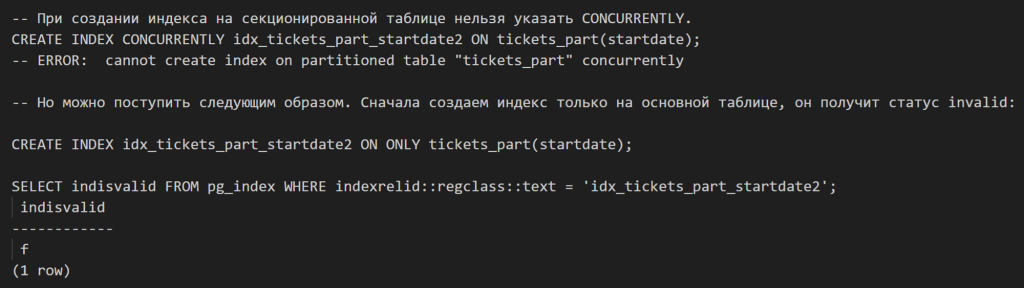
Создался невалидный индекс, так как в нем ничего нет.
Создаем отдельные индексы конкурентно на каждую партицию:

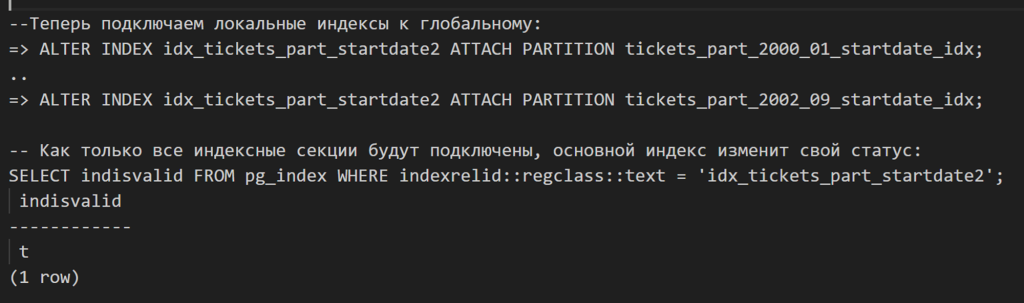
Reindex
При UPDATE создается не только новая версия строки, но и индекса. VACUUM в таком случае не поможет, он не уменьшает размер индекса.
Рассмотрим статистику до и после двух UPDATE:
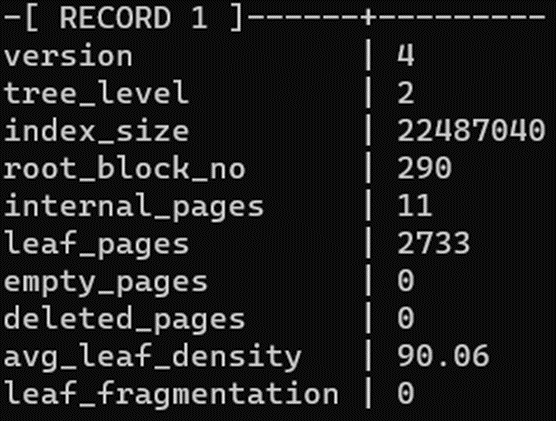
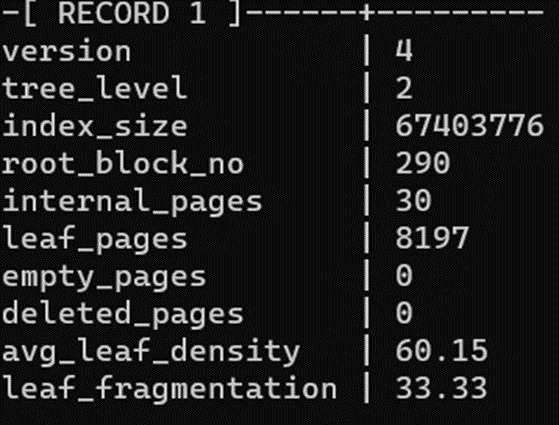
Для сжатия индексов можно использовать конкурентный reindex.
Обязательно смотрим состав индексов и перестраиваем:
- при большой фрагментарности листьев индекса
- при низкой средней плотности
- при большом количестве пустых или удаленных листьев
Обязательно мониторим использование индексов:
- ненужные удаляем
- отсутствующие добавляем (seqscan)
- если таблица маленькая — seqscan быстрее
- если большая селективность/низкая кардинальность (например, мужской и женский пол) — смысла нет
На время создания индекса влияет параметр maintenance_work_mem.
Запускайте обслуживание индексов в момент наименьшей нагрузки
- Не забывайте про CONCURRENTLY:
- Без него требуется эксклюзивная блокировка
- Есть смысл периодического CLUSTER — тяжело добиться
- дорогая реализация аналога кластерного индекса — можно сделать покрывающий индекс по нужному полю, который включает в себя остальные поля
- можно сделать несколько таких индексов
TOAST сегменты имеют свой индекс, который также увеличивается по размерам и не поддается чистке при помощи VACUUM.
Обслуживание GIN индекса
В отличии от Btree индексов, из GIN-индекса элементы никогда не удаляются.
Считается, что значения, содержащие элементы, могут пропадать, появляться, изменяться, но набор элементов, из которых они состоят — статичен. Такое решение существенно упрощает алгоритмы, обеспечивающие параллельную работу с индексом нескольких процессов.
Но в целом рекомендуется REINDEX INDEX CONCURRENTLY в моменты наименьшей нагрузки.
GIN индекс используется для текстового поиска:
- замена ILIKE — index on lower(text)
- to_tsvector — полнотекстовый (GIN index) — при этом делаем функциональный индекс, а НЕ ДОБАВЛЯЕМ поле
- ищем имена с опечатками в PostgreSQL — trigrams
Индексы и внешние ключи
Достоинства:
- Целостность данных
Индексы на внешние ключи обеспечивают целостность данных, контролируя, что значения в столбце ссылающегося ключа существуют в связанной таблице. Это предотвращает нарушение ссылочной целостности.
- Ускорение JOIN-операций
Индексы на внешние ключи улучшают производительность операций объединения (JOIN) между таблицами, так как PostgreSQL может использовать индексы для эффективного объединения данных.
- Улучшенная оптимизация запросов
Оптимизатор запросов может использовать индексы на внешние ключи для выбора оптимальных планов выполнения запросов, что может сократить время выполнения запросов.
- Улучшение производительности DELETE и UPDATE
Индексы на внешние ключи могут ускорить операции удаления и обновления записей, так как они помогают быстро определить, какие записи должны быть удалены или обновлены.
Недостатки:
- Затраты на обслуживание
Индексы требуют дополнительного пространства на диске и добавляют небольшие накладные расходы на обслуживание вставок, обновлений и удалений данных. Это может повлиять на производительность в некоторых сценариях.
- Обновление индексов при изменении данных
Индексы на внешние ключи должны обновляться при изменении данных в связанных таблицах. Это может повлечь за собой небольшие накладные расходы на производительность при выполнении больших операций обновления или удаления данных.
- Выбор правильных индексов
Неверный выбор индексов на внешние ключи или их избыточное создание может привести к излишнему использованию ресурсов и ухудшению производительности.
Рекомендации и материалы
В 90% случаев стоит строить индекс, но лучше все тестировать на реальных кейсах
Дополнительный материал:
Postgres и индексы на внешних ключах и первичных ключах
Индексы на поля с foreign key / PostgreSQL / Sql.ru
В PostgreSQL 17 всё неоднозначно — индексы стали работать быстрее и индексы FK больше не помогают.
Для оценки эффективности выполнения и сора статистики:
- pg_stat_io
- pg_statio_all_tables
- pg_statio_all_indexes
- pg_store_plans
- pg_stat_all_tables
- pg_stat_all_indexes
- pg_stat_kcache
- pg_wait_sampling
- pg_buffercache
- pgstattuple
- pg_stat_archiever
HypoPG
Не всегда мы можем со 100% вероятностью предсказать, поможет ли нам добавление индекса. Физически проверять гипотезу может быть дорого по времени и памяти. Для этого создан инструмент виртуальных индексов.
Checklist
- используем индексы исходя из запросов
- убираем неиспользуемые индексы
- добавляем новые по потребности
- помним про HypoPG
- учитываем особенности массовой вставки данных
- используем индексы на внешние ключи исходя из анализа запросов
- не забываем обслуживать индексы
Этот и другие открытые уроки доступны по ссылке на странице проекта.
Добавить комментарий