Холиварный вопрос — что же лучше?
На самом деле ответ лежит намного глубже. Давайте исследовать.
Зальем мою БД по Тайским перевозкам на ~6 млн записей. Загрузим её в наш инстанс PostgreSQL командой:
wget https://storage.googleapis.com/thaibus/thai_small.tar.gz && tar -xf thai_small.tar.gz && psql < thai.sql
Получили БД объемом 600 Мб — посмотреть можно используя команду \l+ в psql, она нам как раз покажет объем загруженных данных:

Чтобы ответить на вопрос из заголовка, давайте посмотрим планы наших запросов:
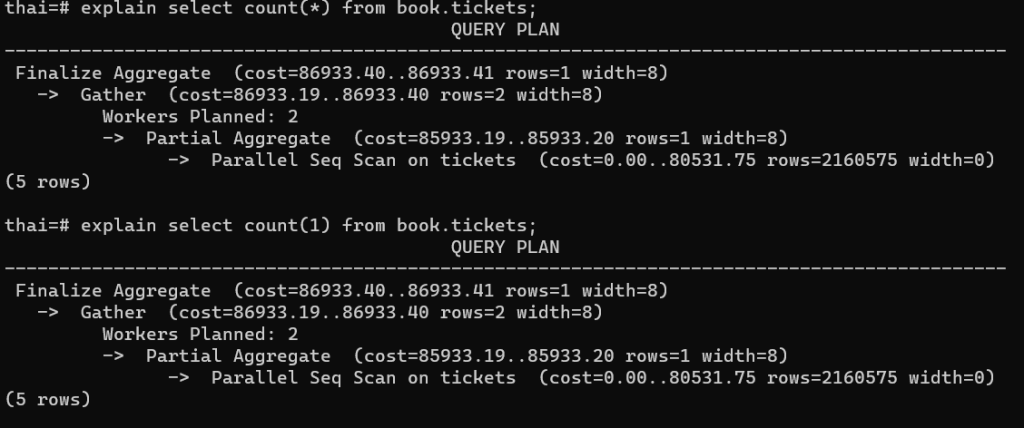
И видим абсолютно идентичные планы, даже с одинаковым количеством «попугаев» в cost(это не шутка, а профессиональный сленг, так как хоть цифры и красивые, но они не связаны напрямую со временем исполнения — нельзя сказать, что 1 млн cost=1 секунды исполнения, можно сравнивать только между собой и примерно представлять во что обойдется запрос).
Вроде закрыли вопрос, но пытливый ум должен зацепиться за строчку — Parallel Seq Scan — получается мы последовательно просматриваем ВСЮ таблицу на диске, чтобы посчитать количество строк… Ну как то не оптимально.. Может у нас нет индекса? Давайте посмотрим:

А вот и индекс, при этом его размер в 4+ раза меньше файла с данными. Так почему же PostgreSQL выбирает последовательное сканирование, а не сканирование индекса?
Чтобы ответить на этот вопрос, давайте сначала почистим таблицу и посчитаем статистику, может быть из-за нее происходит данное поведение:
vacuum analyze book.tickets;
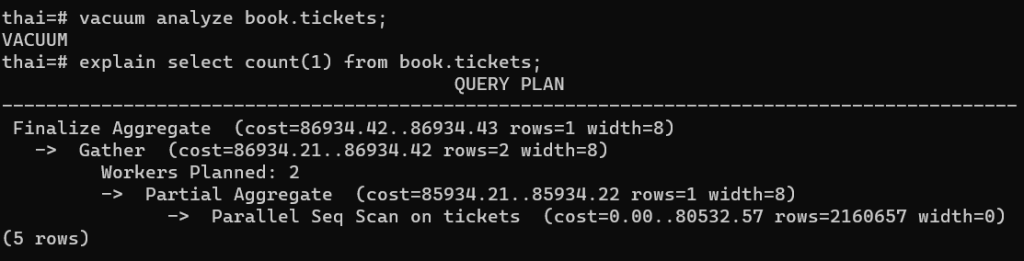
Ничего не изменилось…
А ответ на этот вопрос довольно интересен и это параметр random_page_cost.
Задаёт приблизительную стоимость чтения одной произвольной страницы с диска. Значение по умолчанию равно 4.0. У твердотельных накопителей лучше выбрать меньшее значение random_page_cost — оптимально 1.1
То есть, переводя на русский, PostgreSQL думает, что будет очень дорого найти запись в индексе и сходить проверить её наличие на диске в файле видимости данных для разных снимков данных VM.
Давайте установим этот параметр в 1, так как у меня на ВМ ssd диск и проверим план запроса:

И, наконец, мы видим Parralel Index Only Scan и значительно меньшее количество попугаев!!!
Вы думаете на этом все? Нет, осталось обсудить еще 2 важных момента.
Первое — разницу count(index) и count(field_without_index).
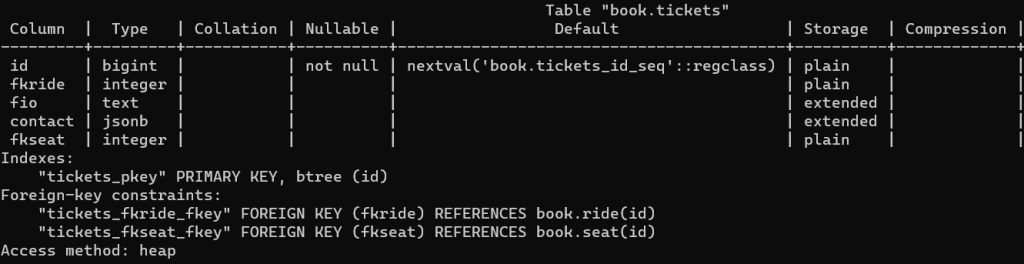
Давайте посмотрим эту разницу. Сначала посмотрим структуру таблицы \d+ book.tickets:
А теперь сравним count(id) и count(fio):
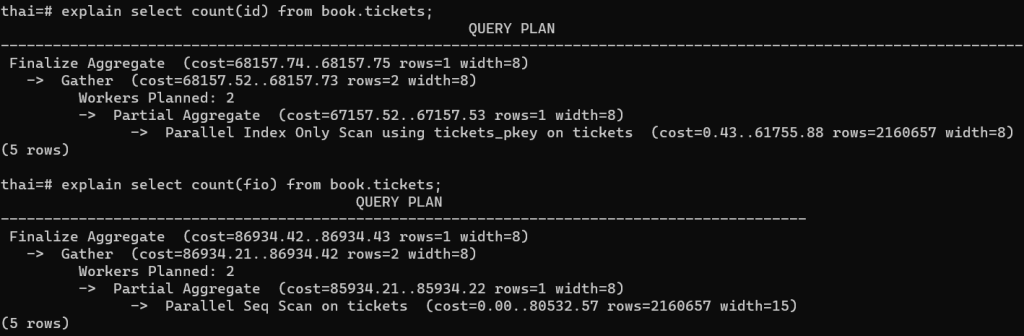
И видим ожидаемое решение PostgreSQL при поиске количества записей для поля без индекса использовать полное сканирование. Это связано с еще одной неочевидной вещью — значение поля FIO может быть NULL и тогда это поле не будет посчитано в итоговом запросе!!!
Если мы попытаемся добавить ограничение NOT NULL на поле FIO то получим ожидаемую ошибку:

Попытаемся избавиться от NULL полей, поменяем структуру БД, объявив поле FIO NOT NULL и тогда ведь PostgreSQL будет первичный индекс использовать? зачем ему seq scan?
UPDATE book.tickets SET fio = ‘no’ WHERE fio is NULL;
ALTER TABLE book.tickets ALTER COLUMN fio SET NOT NULL;
EXPLAIN SELECT count(fio) FROM book.tickets;
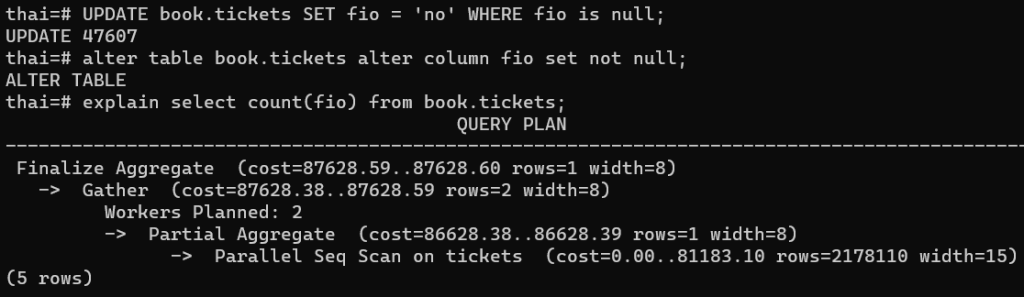
И видим, что план провалился — SEQ SCAN.
Вывод: аккуратнее используем выражение внутри COUNT, есть нюансы.
Есть конечно и более быстрый вариант получить количество строк — достать значение из статистики по таблицам — но значение может быть неточным:
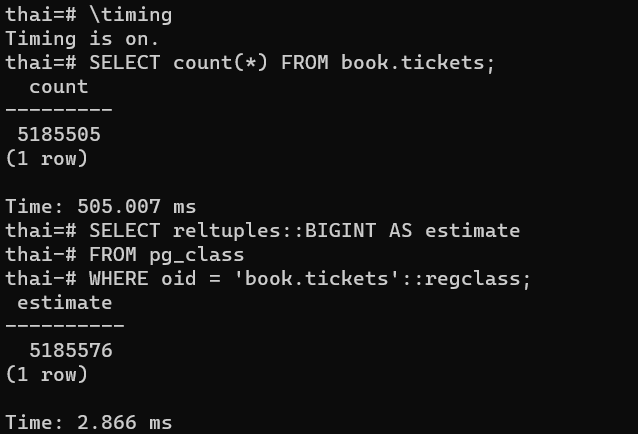
Разница по времени выполнения и полученным значениям очевидна.
Второй нюанс работы с COUNT связан с использованием UUID — но это материал для следующей статьи.
Добавить комментарий