Табличное пространство это:
- отдельный каталог с точки зрения файловой системы
- лучше делать отдельную файловую систему
- одно табличное пространство может использоваться несколькими базами данных
- каждой базе данных можно назначить как табличное пространство по умолчанию, так и в каждом конкретном случае указывать в каком табличном пространстве будет расположен конкретный объект внутри базы данных
По умолчанию есть два табличных пространства. Давайте на них посмотрим:
SELECT * FROM pg_tablespace;
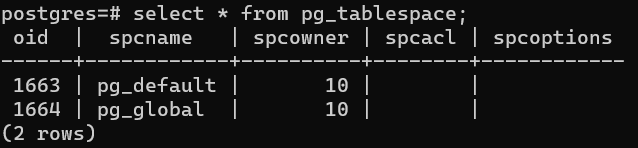
Новые табличные пространства по умолчанию создаются в каталоге $PGDATA\pg_tblspc. Также можем создать свой каталог и создать своё табличное пространство, указав путь к нашему каталогу. Попробуем на практике.
Создадим каталог из-под суперпользователя линукс root, для этого выйдем из-под пользователя postgres и зайдём под пользователем root. Поменяем его владельца на пользователя линукс postgres:
exit
sudo su
sudo mkdir /home/postgres
sudo chown postgres /home/postgres
Переключимся на пользователя линукс postgres и в новом месте создадим каталог для нашего табличного пространства:
sudo su postgres
cd /home/postgres
mkdir tmptblspc
Теперь в утилите psql создадим само табличное пространство, где укажем путь ко вновь созданному каталогу:
psql
CREATE TABLESPACE ts location ‘/home/postgres/tmptblspc’;
Посмотрим на список табличных пространств:
\db
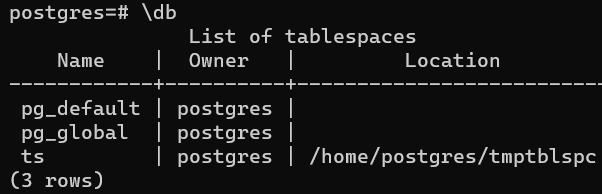
Создадим базу данных с настройкой нового табличного пространства по умолчанию:
CREATE DATABASE app TABLESPACE ts;
Подключимся к созданной БД:
\c app
Чтобы посмотреть дефолтный tablespace, выполним:
\l+
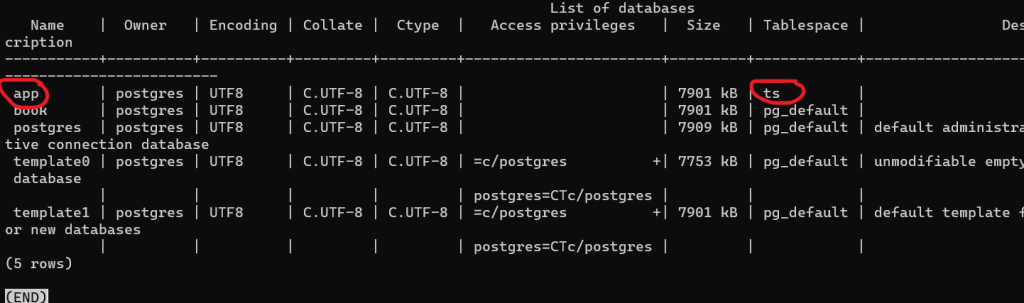
Чтобы выйти из полноэкранного режима, нужно нажать кнопку q.
Без конкретного указания табличного пространства при создании таблицы она автоматически будет расположена в tablespace ts. Конечно, можно точно указать, где конкретно хранить таблицу.
Вернёмся немного к теории, а именно как хранятся таблицы физически с учётом табличных пространств (ТП) и баз данных:
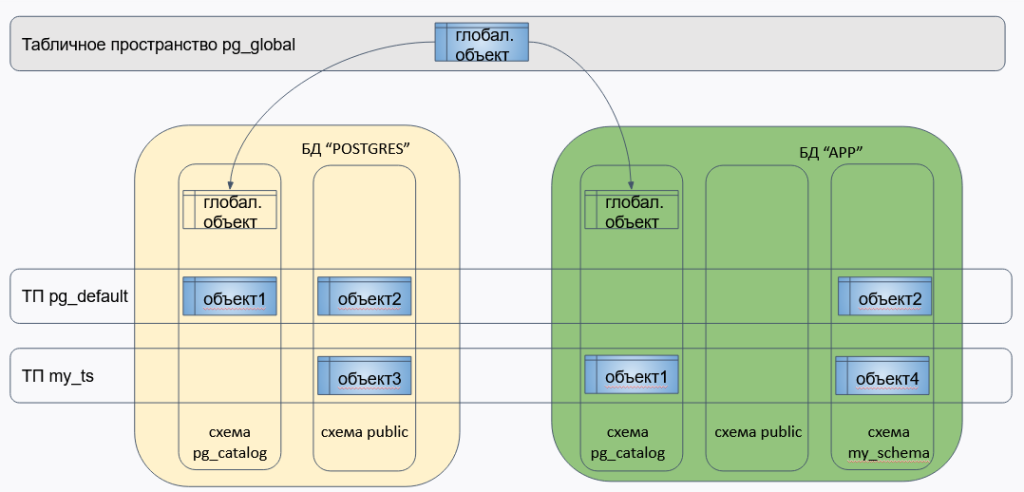
Видим, что объект может принадлежать только к одному табличному пространству (pg_default или другое), одной базе данных (app или postgres) и одной схеме (у каждой БД свой набор схем, про них будем говорить в теме про логическое устройство Постгреса). И только глобальные/системные объекты хранятся отдельно в табличном пространстве pg_global и присутствуют логически в каждой БД. При этом, одному объекту в базе данных может соответствовать от одного и более файлов в зависимости от типа объекта и его размера.
Конечно, можно перемещать объект между табличными пространствами, но нужно понимать, что это будет физическое перемещение файлов между каталогами, и на это время доступа к объекту не будет.
Также внутри каталога с табличным пространством расположены каталоги с базами данных. При этом используются также OID, только уже для БД. Полный пусть к объекту выглядит следующим образом:

Перечислю варианты оптимизации производительности с использованием табличных пространств:
- самые часто используемые данные на самые быстрые носители
- редко используемые архивы на медленные
- распараллелить нагрузку по разным рейд массивам
- локальный ssd диск для материальных представлений
Теперь рассмотрим, как физически хранятся сами таблицы.
Внутри каталога с БД уже расположены непосредственно файлы объектов. Для каждой таблицы создаётся до трёх файлов (если размер сегмента больше 1 Гб, то будут созданы аналогичные файлы с добавлением номера сегмента .1 .2 и т.д.):
- файл с данными — OID таблицы
- файл со свободными блоками — OID_fsm (free space map)
- отмечает свободное пространство в страницах после очистки
- используется при вставке новых версий строк
- существует для всех объектов
- файл с таблицей видимости — OID_vm (visibility map)
- отмечает страницы, на которых все версии строк видны во всех снимках
- используется для оптимизации работы процесса очистки и ускорения индексного доступа
- существует только для таблиц
- иными словами, это страницы, которые давно не изменялись и успели полностью очиститься от неактуальных версий
Схематично можно представить себе это так:
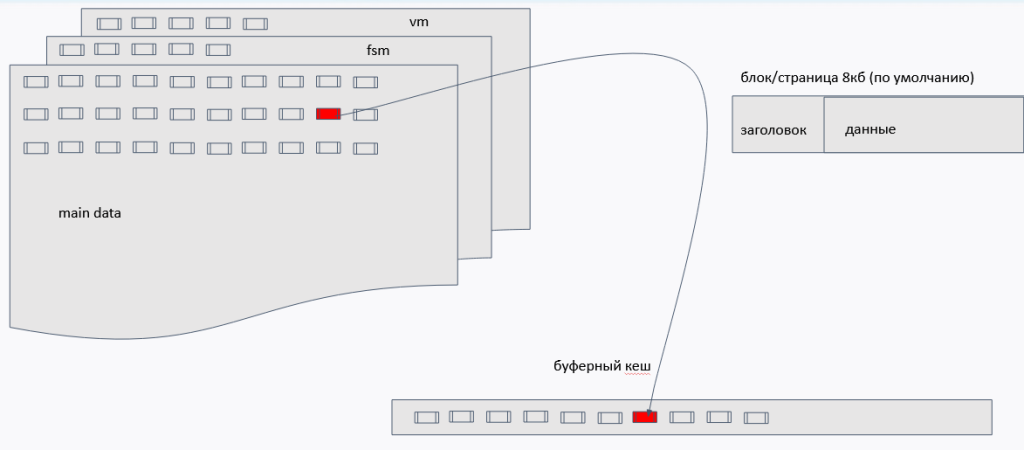
Обратим внимание, что работа с данными идёт не побайтно, а блоками/страницами по 8 Кб (размер задаётся при инициализации кластера, обычно никто не меняет). Нужные данные извлекаются из файла и загружаются в буферный кэш постранично (более подробно, как в Постгресе организована работа со слоями и кэшем, будем разбирать в следующих темах).
Добавить комментарий