Вспомним как хранятся наши строки. Версия строки должна помещаться на одну страницу 8кб (размер по умолчанию, влияние этого размера на производительность будет рассмотрено далее в книге). Если данные в строке превышают этот размер, то:
- можно сжать часть атрибутов
- или часть вынести в отдельную TOAST-таблицу
- или сжать и вынести одновременно
- также длинные строки (jsonb, varchar, etc) также выносятся в TOAST-таблицу
Давайте разбираться, что это такое.
Особенности TOAST-таблицы (The Oversized Attribute Storage Technique):
- поддержана собственным индексом
- читается только при обращении к «длинному» атрибуту
- собственная версионность (если при обновлении toast часть не меняется, то и не будет создана новая версия toast части)
- работает прозрачно для приложения
- стоит задуматься, когда пишем SELECT * — вроде 1 значение из TOAST прочитать, а подтягиваем всю страницу оттуда
- обновление тоста влечет bloating (раздутие) данных – увидим на практике
Для тестов создадим табличку и посмотрим OID TOAST сегмента – уникальный сквозной идентификатор объектов в Постгресе:
CREATE TABLE toast_test (id SERIAL, value TEXT);
SELECT relname, reltoastrelid FROM pg_class WHERE relname = ‘toast_test’;

Используя полученный OID посмотрим имя скрытой таблицы с TOAST сегментом реальной таблицы:
SELECT relname FROM pg_class WHERE oid = 16393;

И посмотрим структуру TOAST таблицы (OID отличается от имени, формируемого по OID родительской таблицы):
\d pg_toast.pg_toast_16389
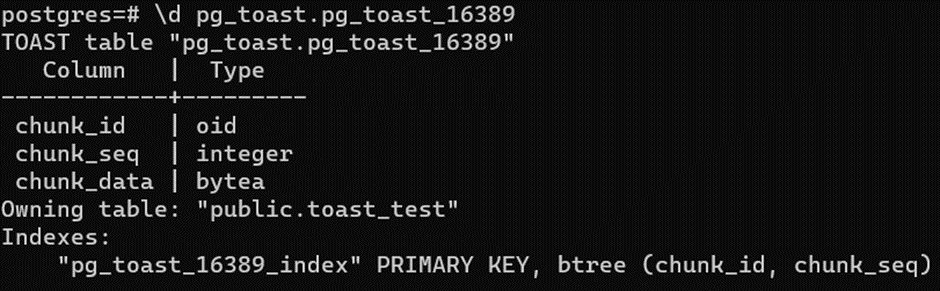
Видим 3 поля:
- chunk_id: ссылка на TOAST
- chunk_seq: номер чанка (куска данных)
- chunk_data: реальные сжатые данные
Также обнаруживаем встроенный индекс по полям chunk_id и chunk_seq. На структуру таблицы или индекса мы повлиять никак не можем, только если сделать REINDEX (будем далее в книге обсуждать).
Посмотрим на текущие размеры данных и TOAST:
SELECT
n.nspname || ‘.’ || c.relname AS table_name,
pg_size_pretty(pg_total_relation_size(c.oid)) AS total_size,
pg_size_pretty(pg_total_relation_size(c.reltoastrelid)) AS toast_size
FROM pg_class c
JOIN pg_namespace n
ON c.relnamespace = n.oid
WHERE
relname = ‘toast_test’;
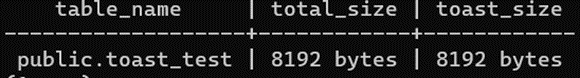
Ожидаемо, пустая таблица содержит по минимальному сегменту данных по размеру сегмента кластера по умолчанию. Как изменять и как влияет на производительность изучаем на курсе.
Добавим небольшое значение и посмотрим на содержимое TOAST таблицы:
INSERT INTO toast_test (value) VALUES (‘small value’);
SELECT * FROM pg_toast.pg_toast_16389;
И не видим там данных – что полностью ожидаемо, строчка замечательно помещается в сегмент с данными.
Теперь добавим строчку размером 4097 пробелов и посмотрим на содержимое TOAST:
INSERT INTO toast_test (value) VALUES (repeat(‘ ‘, 4097));
SELECT * FROM pg_toast.pg_toast_16389;

И не видим там данных – что довольно ожидаемо, строчка в 4 КБ помещается в сегмент 8 КБ с данными.
Теперь добавим строчку размером 400 тысячами пробелов и посмотрим на содержимое TOAST – количество таких сегментов:
INSERT INTO toast_test (value) VALUES (repeat(‘s’, 400097));
SELECT count(*) FROM pg_toast.pg_toast_16389;

И видим 3 сегмента! Посмотрим на размеры содержимого:
SELECT chunk_id, chunk_seq, length(chunk_data) FROM pg_toast.pg_toast_16389;

Наблюдаем автоматическое сжатие TEXT и довольно неплохо 400 КБ в 4,5 КБ.
Реализуем функцию генерации случайных строк – сжать будет уже значительно сложнее, чем одинаковые символы. На вход будет принимать 2 параметра – длину генерируемой строки и из каких символов она должна состоять:
CREATE OR REPLACE FUNCTION generate_random_string(
length INTEGER,
characters TEXT default ‘0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz’
) RETURNS TEXT AS
$$
DECLARE
result TEXT := »;
BEGIN
IF length < 1 then
RAISE EXCEPTION ‘Invalid length’;
END IF;
FOR __ IN 1..length LOOP
result := result || substr(characters, floor(random() * length(characters))::int + 1, 1);
end loop;
RETURN result;
END;
$$ LANGUAGE plpgsql;
И, используя эту функцию, вставим 10 КБ строчку:
INSERT INTO toast_test (value) VALUES (generate_random_string(1024 * 10));
И посмотрим на размер сгенерированного TOAST:
SELECT chunk_id, COUNT(*) as chunks, pg_size_pretty(sum(octet_length(chunk_data)::bigint))
FROM pg_toast.pg_toast_16389 GROUP BY 1 ORDER BY 1;

Видим, что случайная строка разъехалась по сегментам, но сжатие не помогло – на случайно сгенерированных данных оно практически не работает.
Очистим таблицу:
TRUNCATE toast_test;

Обратите внимание, транкейт вернул место, в отличии от DELETE.
По умолчанию Постгрес использует LZ comperssion в качестве метода сжатия. Конечно, это поведение можно изменить.
Продолжение этой статьи про хранение jsonb в PostgreSQL скоро будет опубликована
Добавить комментарий