Краткое содержание Ютуб ролика (небольшой отрывок первой лекции курса по Оптимизации PostgreSQL) про особенности генерации UUID
UUID замечательный инструмент для генерации уникальных значений искусственного первичного ключа в PostgreSQL, но он имеет и ряд недостатков.
Сравним генерацию 10 миллионов строк UUID четвертой версии + рандомный текст с аналогичным классическим подходом serial. Потом создадим индексы по этим двум полям и сделаем вакуум аналайз. И сейчас мы увидим интересные сайд-эффекты.
Генерируем 10 миллионов строк за 30 секунд. Посмотрим на размеры.
Делаем Explain по первому варианту (id просто serial). Explain Analyze 540 миллисекунд.
Теперь делаем Count ID по UUID и получаем время в три раза больше.
Кроме того, что уиды больше размером, так как они занимают больше места, сам индекс больше. Вторая проблематика связана с походом по индексам и по данным. То есть, когда мы делаем seqscan или indexscan, все равно используются VisibilityMap – проверяется видимость данной версии снимка MVCC.
То есть ID у нас расположены по очереди, по возрастанию. Соответственно, они по возрастанию, то есть у нас на каждую запись идет 2 бита в этой карте. Определять, есть ли данные на диске или нет.
И, соответственно, механизм в PostgreSQL оптимизирован для последовательного сканирования. Если данные по порядку расположены, то у нас, соответственно, они закэшированы.
UUID у нас случайным образом генерируются. То есть мы каждый раз попадаем, для проверки каждой строчки, в разный файл VisibilityMap. И он то один дергает с диска, то другой. Данных у нас много. И между ними переключается, и оптимизация у нас этого не срабатывает.
Также индекс с UUID будет ненамного больше — создаваться 28 секунд против 22 у serial. Связано это с особенностью работы функции генерации рандомного значения. Она использует системный вызов в Linux. И, соответственно, тот не сильно быстрый и обращается к генератору. Поэтому есть задержка, пока генератор выдал значение. То есть мы упираемся в вызов функции при генерации значений. Да, казалось бы, там доли-доли миллисекунды, но, когда умножается на 10 миллионов итераций, в целом вот такой overhead. 6 секунд, сколько получается? Ну, почти 30 процентов. Функция random на большом объеме.
Эта генерация, обратите внимание, работает для четвертой версия UUID. Должен добавить седьмую версию UUID. Она будет расположена на диске как раз последовательно, как айдишка. И, соответственно, вот эта проблема, по крайней мере, с каунтом уйдет при обращении.
Вот, интересно про седьмую версию. Патч был внесен на модерацию в 16 версию PostgreSQL, но не был принят. Возможно добавят в 17 версию.
Также стоит обратить на огромное время подсчета count – так как он проходит по всем записям в индексе или вообще по диску для точного подсчета.
В зависимости от вашей бизнес задачи можно использовать оценочное количество, основанное на содержащихся в статистике данных. Здесь важно пересобрать статистику вовремя. И также понимать, что count из статистики лишь приблизителен, но в целом довольно точен. Из плюсов – он практически мгновенен на больших объемах.
SELECT reltuples::BIGINT AS estimate
FROM pg_class
WHERE oid = 'book.tickets'::regclass;
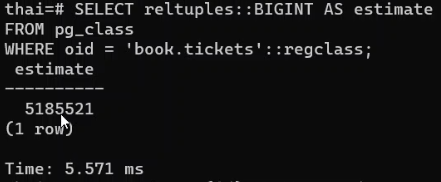
Если использовать классический count:
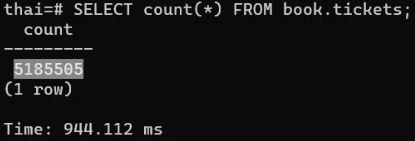
Разница по количеству записей минимальна, а вот по скорости на 2 порядка!!!
Также более подробно можно прочитать в статьях:
Добавить комментарий