Статья основана на двенадцатом видео из 31 темы курса SQL 2.0 — PL/pgSQL в PostgreSQL от Аристова Евгения, который является логическим продолжением курса SQL c 0. Ссылки на видео на платформах RUTUBE и VK video.
В данной статье подробно разбираются составные типы данных и их ограничения, вычисляемые поля и их минусы.
В прошлой статье мы разобрали категории изменчивости функции, такие как IMMUTABLE, STABLE и VOLATILE.
Презентация и исходники доступны по ссылке.
Составные типы данных
Несмотря на то, что базовых типов 300+, довольно часто необходимо создавать свои типы данных — чем то похоже на объекты и наследование как в ООП.
Например создадим тип валюта:
CREATE TYPE currency AS (
amount numeric,
code text
);
И используем его уже в другой таблице с транзакциями:
CREATE TABLE transactions(
account_id integer,
debit currency,
credit currency,
date_entered date DEFAULT current_date
);Добавление данных при использовании составных типов
Значения составного типа можно формировать в трёх вариантах:
либо в виде строки, внутри которой в скобках перечислены значения
INSERT INTO transactions VALUES(1, NULL, '(7000.00,"RUR")');либо с помощью табличного конструктора ROW:
INSERT INTO transactions VALUES(2, ROW(350.00,'RUR'), NULL);если составной тип содержит более одного поля, то слово ROW можно опустить:
INSERT INTO transactions VALUES(3, (20.00,'RUR'), NULL);SELECT * FROM transactions;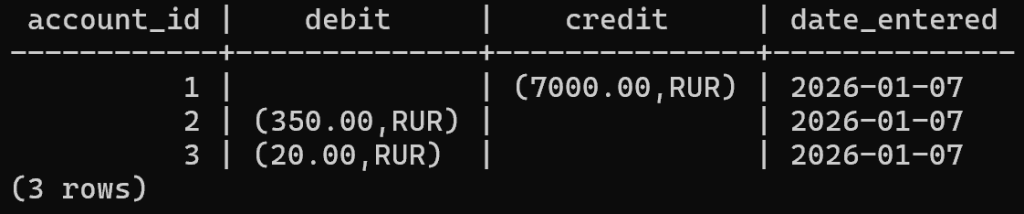
Доступ ко вложенным объектам осуществляется как обычно — через точку:
CREATE FUNCTION multiply(factor numeric, cur currency) RETURNS currency AS $$
SELECT ROW(factor * cur.amount, cur.code)::currency;
$$ IMMUTABLE LANGUAGE SQL;SELECT account_id, multiply(2,debit), multiply(2,credit), date_entered FROM transactions;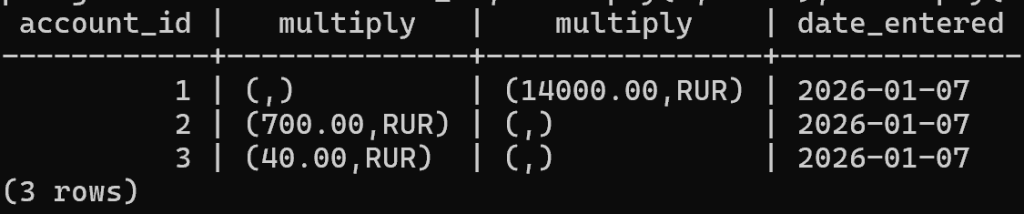
Ограничения
- добавлять/удалять поля через alter type add/remove field, что может накладывать ограничения на модификацию существующих данных
- Ограниченная поддержка индексов
- Сложности с миграциями
- Не все клиентские библиотеки хорошо поддерживают
Составные типы отлично подходят для сложных структур данных, где нужна строгая типизация и логическая группировка полей!
Виртуальные колонки
С недавних пор у нас появилась возможность создавать и использовать генерируемые колонки — GENERATED ALWAYS. Кроме дополнительных вычислений минусом является необходимость их хранить рядом с данными.
Если это нам не подходит, то на помощь приходит механизм виртуальных колонок, где на вход мы подаём всю строку и на основании неё генерируем нужное нам значение на лету.
Например Фамилия И.О. на основании ФИО.
Так бы нам пришлось каждый раз повторять формулу — а в данном случае мы просто указываем имя дополнительного поля по имени функции:
CREATE FUNCTION textcurrency(cur currency) RETURNS text AS $$
SELECT cur.amount || cur.code;
$$ IMMUTABLE LANGUAGE SQL;
SELECT t.*, textcurrency(t.debit) as debit, textcurrency(t.credit) as credit FROM transactions t;
Усложним ситуацию, и передадим внутрь функции всю строку таблицы:
CREATE FUNCTION textcurrency(tr transactions) RETURNS text AS $$
SELECT tr.account_id || tr.date_entered::text;
$$ IMMUTABLE LANGUAGE SQL;
SELECT t.*, textcurrency(t.*) FROM transactions t;

Синтаксисом допускается обращение к функции как к столбцу таблицы без явного указания (и наоборот, к столбцу как к функции).
SELECT t.*, t.textcurrency FROM transactions t;

И получили полную виртуальную колонку — вычисляется каждый раз при вызове функции!
Почему 2 функции имеют одинаковое имя и при этом работают одновременно, мы разберём в 16 теме.
Виртуальные колонки. Минусы
Необходимо вычислять такую колонку каждый раз при обращении, что может быть дорого.
Больше примеров доступно на гитхабе и в видео.
В следующей статье мы разберём использование операторов.
Добавить комментарий