Статья основана на материалах открытого вебинара, прошедшего 28.08. Запись занятия доступна как в ютуб версии, рутуб версии и VK Видео.
PostgreSQL
Достоинства и недостатки
Достоинства:
- ACID — соответствие принципам ACID (атомарность, консистентность, долговечность, изоляция), всё оборачивается в транзакции
- Огромное комьюнити
- Легковесность
- Открытость
- Бесплатность
- Хорошая производительность OLTP (большое количество маленьких запросов)
- Постоянный выход новых версий — убираются баги, добавляются фичи
Недостатки:
- Производительность ниже конкурентов
- Высокий порог вхождения из-за особенностей архитектуры, без знаний архитектуры возникают проблемы на проектах. Также собственная система MVCC отличается от других СУБД
- Хороший тюнинг и решение основных тонких мест требует огромной квалификации
- Плохая производительность OLAP
- Ужасно масштабируется — нет кластеров из коробки
- Проблемы с коннектингом
- Настройка отказоустойчивости имеет очень высокий порог входа
Следующей важной проблемой PostgreSQL является механизм подключений пользователей.
Рассмотрим график падения производительности при большом количестве подключений:
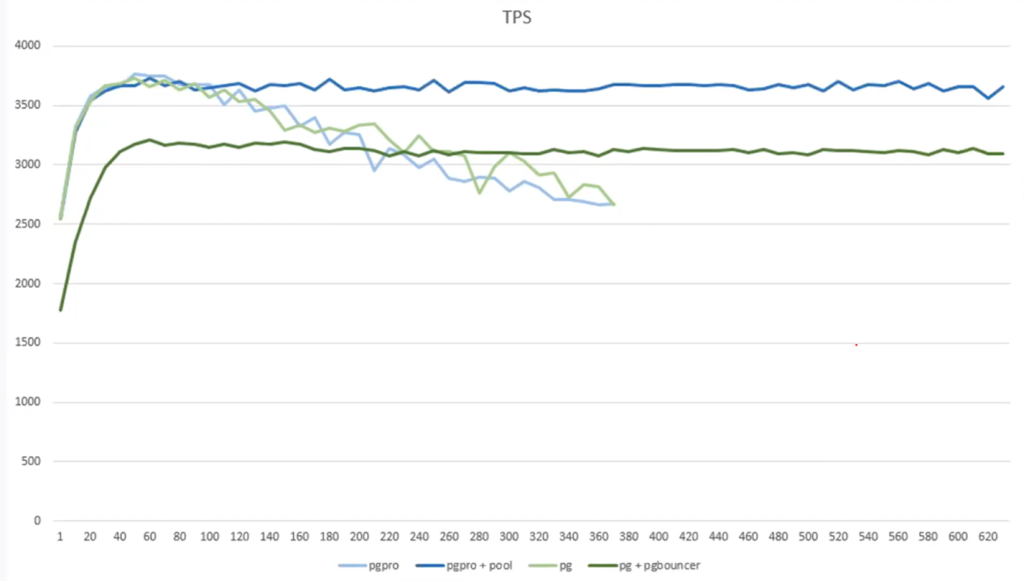
По умолчанию допустимое количество соединений — 100. Без подключения пула соединений после 500-600 соединений производительность падает катастрофически (в зависимости от мощности инстанса).
Балансировка нагрузки
Кроме пула соединений нам необходим еще и какой-либо прокси сервер для направления пишущей нагрузки на primary сервер, а читающей на stand by сервера. Также неплохо было бы при смене лидера автоматически перенаправлять трафик в новой обстановке. Классически используется решение — HAProxy.
После этого нужно определиться с моделью подключения — каждый вариант имеет свои преимущества и недостатки.
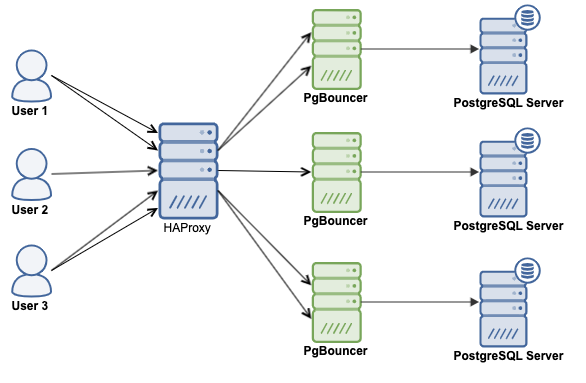
Первый — пользователи отправляют запросы на HAProxy, а он уже перенаправляет на PGBouncer:
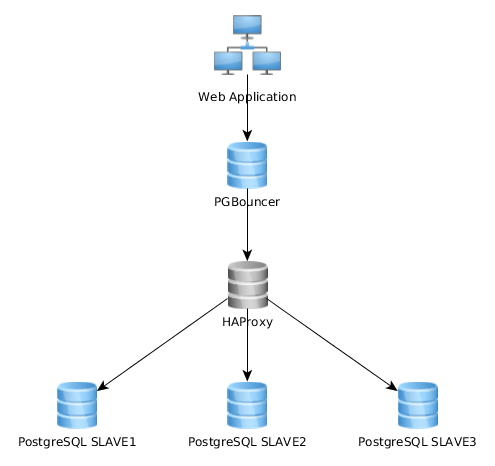
Второй вариант — пользователь сначала идет в PGBouncer, а уже потом в HAProxy:
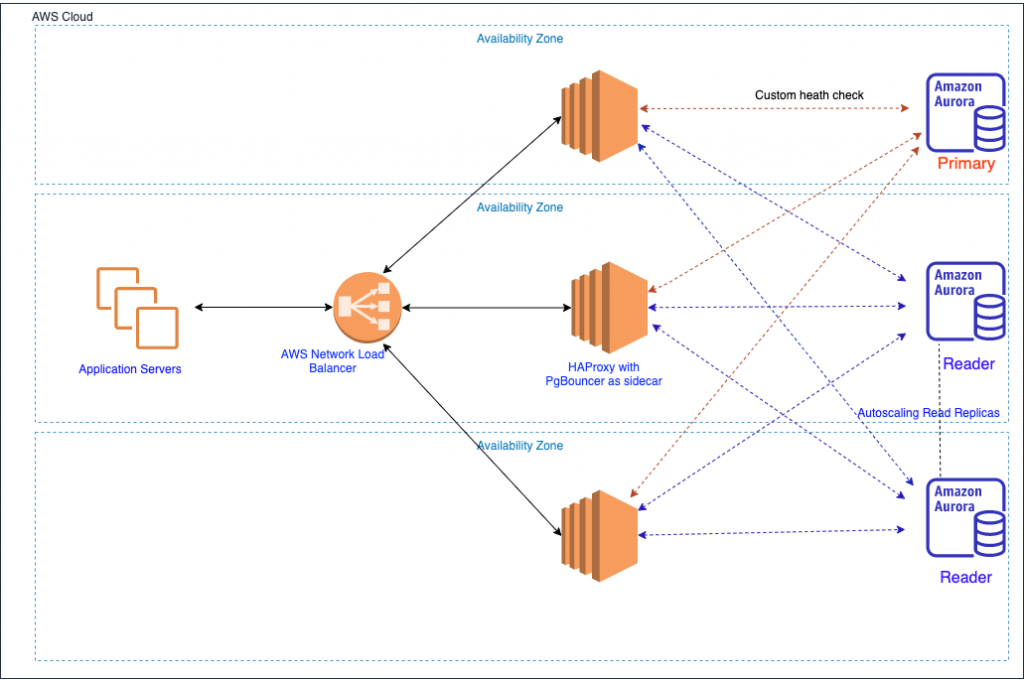
Вариант балансировки, реализованный в AMAZON — PGBouncer и HAProxy используются в виде sidecar к виртуальным машинам на PostgreSQL:
Следующим моментом для настройки является выбор модели репликации для горизонтального масштабирования.
Физическая репликация
В PostgreSQL существует 5 уровней синхронного commit, которые реализуются через трансляцию журнальных файлов (WAL файл содержит информацию обо всех изменениях в БД).
Транзакция вносит какие-то изменения, сначала они попадают в WAL, могут из буфера перекладываться на диск или транслироваться на удаленные реплики (там могут применяться или также записываться на диск).
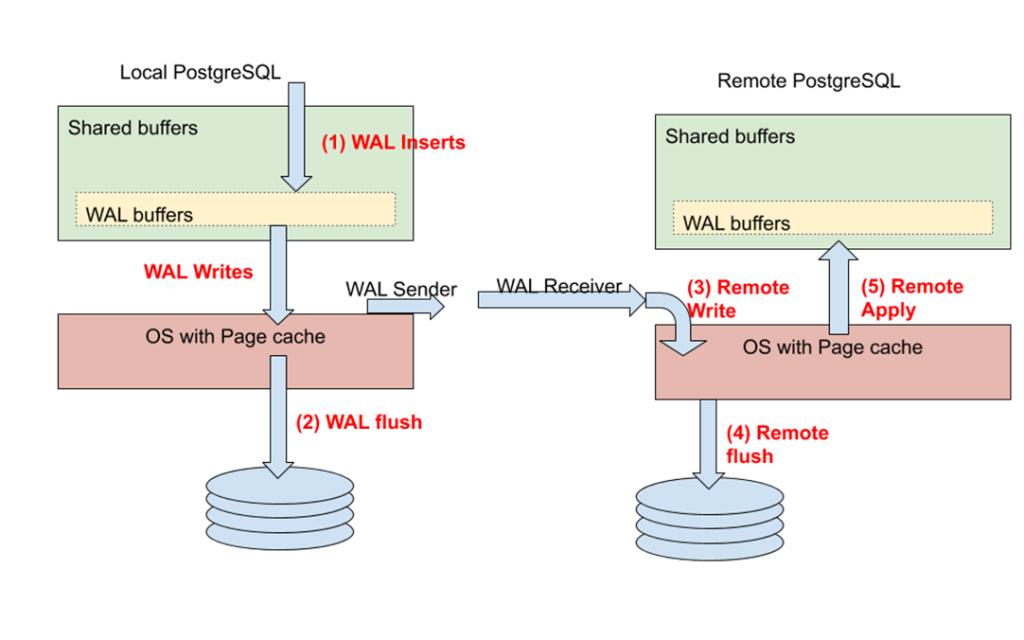
Особенности синхронной репликации:
При выключенном синхронном commit изменения записываются только на диск
При режиме local все изменения сначала фиксируются в WAL и после рестарта незафиксированные записи можно достать из журнала и записать в файлы данных (все данные консистентны — реализация durability в терминах ACID).
rewote_write — режим подтверждения получения WAL файлов репликой
on — запись WAL файлов на диск
remote_apply — самый тяжеловесный режим, после записи WAL на диск, изменения применяются к данным. Производительность может упасть в несколько раз по сравнению с асинхронным режимом
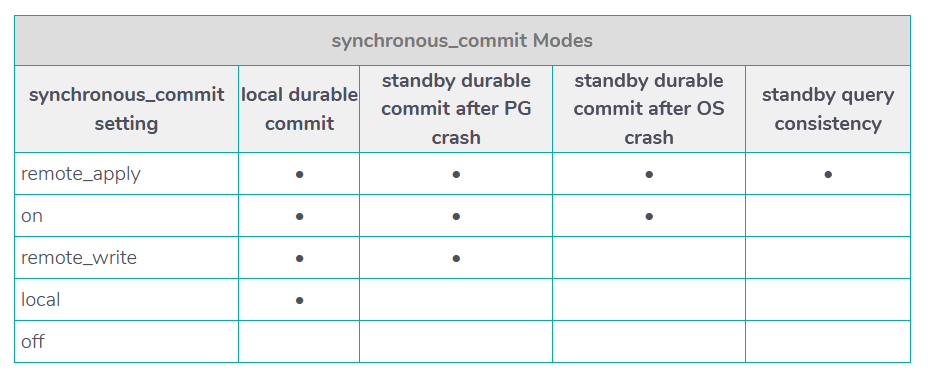
Можно устанавливать разные режимы синхронности на разные транзакции для повышения скорости. Например, самые важные транзакции применять с максимальным уровнем синхронности, а основной трафик — в асинхронном режиме.
Схема после балансировки:
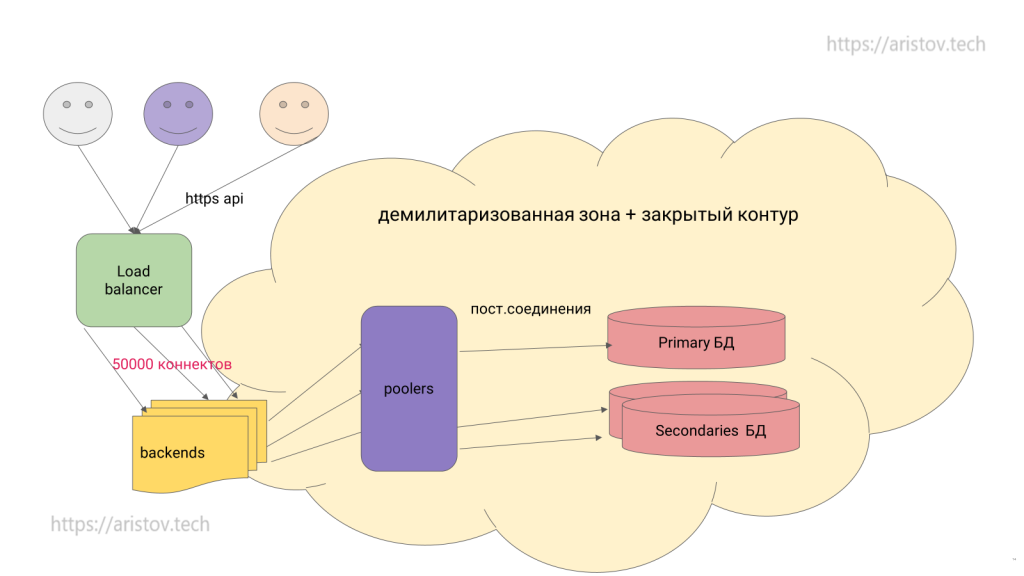
В этой схеме нет HA (кто будет переключать primary во время аварии) — это проблема.
Patroni
Patroni — классическое решение для автоматического переключения мастера при падении. Плюс здесь есть отказоустойчивое хранилище метаданных в etcd, сразу присутствует HAProxy.
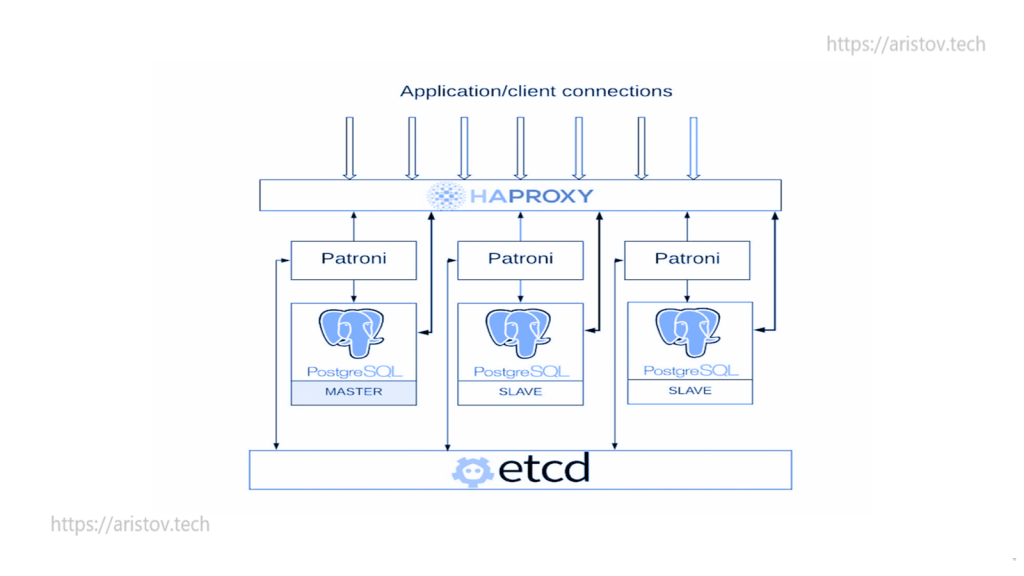
В эту схему можно добавить PGBouncer, keepalived как единая точка входа и 2 HAPROXY для устранения единой точки отказа.
OLAP
PostgreSQL плохо работает с аналитической нагрузкой.
Для ускорения можно использовать:
- Промежуточные агрегаты (влечет избыточность)
- Материализованные представления
- Хранимые процедуры
- Если не нужен срочный ответ — message broker для накопления данных и их ночная обработка
- Готовые OLAP решения (Pentaho, GreenPlum, ArenaData, ClickHouse, Citus)
- fdw — подключение к другим базам
- cstore
- pgmemcache
- timescaledb
Решение всегда принимает архитектор.
CRDB — CocroachDB
Основатели Google Spanner создали свой продукт. Является NewSQL решением, сочетающем в себе лучшие стороны SQL и NoSQL решений.
Под капотом является NoSQL решением, но можно подключаться как по современному протоколу, так и по протоколу PostgreSQL (например, из psql).
Преимущества:
- Легко масштабируется
- Есть геотеги — можем распределять нагрузку по всему миру
- Есть коммьюнити версия
- Существует режим мульти-мастера
- Есть транзакции
- Поддержка принципов ACID
- Мульти-региональность
- Мульти-клаудность
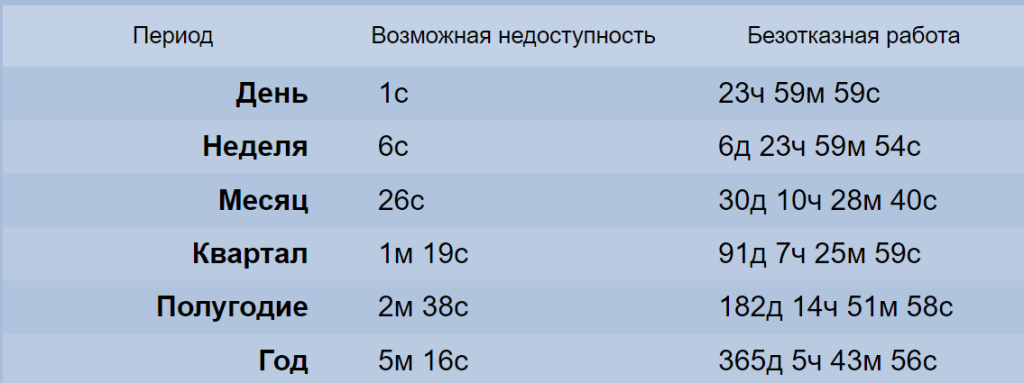
- SLA 99,999% отказоустойчивости
Полезные ссылки:
- Цены
- Архитектура — протокол PostgreSQL, под капотом KV
- Обработка параллельных транзакций — в т.ч.пишущих
- Сравнение с другими продуктами
Можно назвать CocroachDB современным PostgreSQL на максималках с большим количеством фичей из коробки. В России используется редко.
MongoDB
Достоинства и недостатки
Достоинства:
Кроссплатформенность: СУБД разработана на языке программирования С++, поэтому с легкостью интегрируется под любую операционную систему (Windows, Linux, MacOS и др.)
Формат данных: MongoDB использует собственный формат хранения информации — Binary JavaScript Object Notation (BSON), который построен на основе языка JavaScript
Вместо таблиц MongoDB использует коллекции. Они содержат слабоструктурированные документы и не имеют общей структуры
Документ: если реляционные БД используют строки, то MongoDB — документы, которые хранят значения и ключи
Индексация: технология применяется к любому полю в документе на усмотрение пользователя
Репликация: система хранения информации в СУБД представлена узлами. Существует один главный и множество вторичных. Данные реплицируются между точками. Если один первичный узел выходит из строя, то вторичный становится главным.
Шардирование: распределение их частей по различным узлам кластера. Благодаря тому, что каждый узел кластера может принимать запросы, обеспечивается балансировка нагрузки.
Map Reduce framework — ускорение при работе с данными на шардированных кластерах. Каждая нода отдельно обрабатываем запрос, потом данные объединяются
Для сохранения данных большого размера MongoDB использует собственную технологию хранения файлов GridFS, состоящую из двух коллекций. В первой (files) содержатся имена файлов и метаданные по ним. Вторая (chunks) сохраняет сегменты информации, размер которых не превышает 256 Кб.
Недостатки:
Тяжело работать с большими базами данных, так как требуется шардирование (тяжело реализуется, несмотря на встроенность)
Медленно работает при большом количестве шардов при неудачном выборе ключа шардирования и непопадании в него запросов
Не гарантируется время жизни ключей при использовании технологии TTL (удаляются не сразу)
Sharding
Недостатки шардирования:
С шардированием обязательно будет усложняться код — во многие места придется передавать ключ шардирования. Это не всегда удобно, не всегда возможно. Некоторые запросы пойдут либо broadcast, либо multicast, что тоже не добавляет масштабируемости. Подходите к выбору ключа по которому пойдет шардирование аккуратнее.
В шардированных коллекциях может сломаться операция count — начинает возвращать число больше, чем в действительности — может соврать по размеру мигрируемых чанков. Причина лежит в процессе балансировки, когда документы переливаются с одного шарда на другой. Когда документы перелились на соседний шард, а на исходном еще не удалились — count их все равно посчитает.
Значительный рост потребляемых ресурсов — для минимальной отказоустойчивой работы необходимо 11 инсталяций Монго.
Шардированный кластер гораздо тяжелее в администрировании — процедура снятия бэкапа становится радикально сложнее, так как в бесплатной версии его нет из коробки. Необходимо большая автоматизация работы для снятия консистентного бэкапа.
Шардинг коллекции невозможен, если:
- Требуется обновление полей, входящих в ключ шардирования
- На коллекции есть несколько уникальных ключей
- Под результат запроса findAndModify попадают данные на разных шардах
Несбалансированная нагрузка по шардам, если:
- Слабая селективность ключа шардирования
- Запросы без значений ключа шардирования
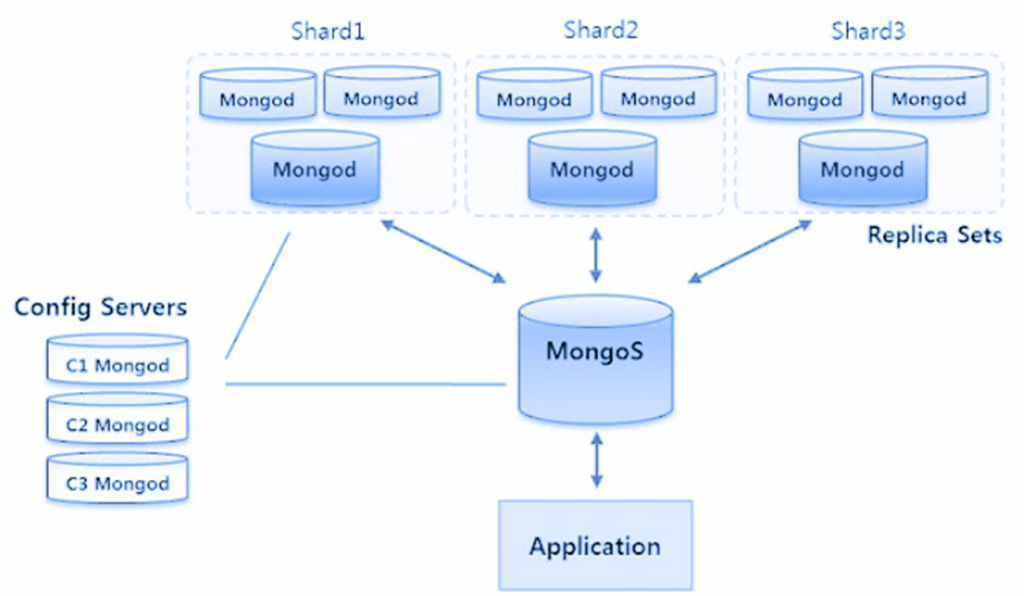
Классическая схема шардирования — приложение ходит в MongoS (монго сервер), который знает, где какие данные расположены, отправляет запрос на нужный шард.
Использование
Примеры использования MongoDB:
- хранение и регистрация событий
- системы управления документами и контентом
- электронная коммерция
- игры
- данные мониторинга, датчиков
- мобильные приложения
- хранилище оперативных данных веб-страниц (например, хранение комментариев, рейтингов, профилей пользователей, сеансы пользователей)
Оптимизация работы
Утечки информации:
- https://securitydiscovery.com/800-million-emails-leaked-online-by-email-verification-service/
- https://www.opennet.ru/opennews/art.shtml?num=49259
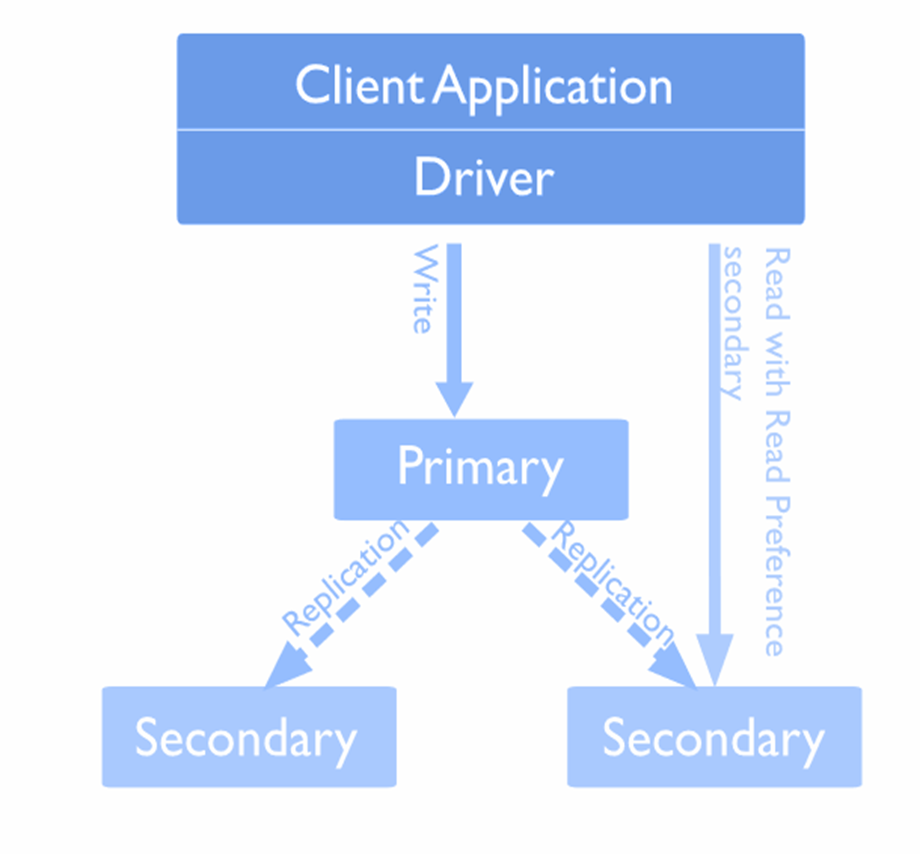
Можно привязываться к инстасам по геотегам, можно указывать, откуда читать данные:
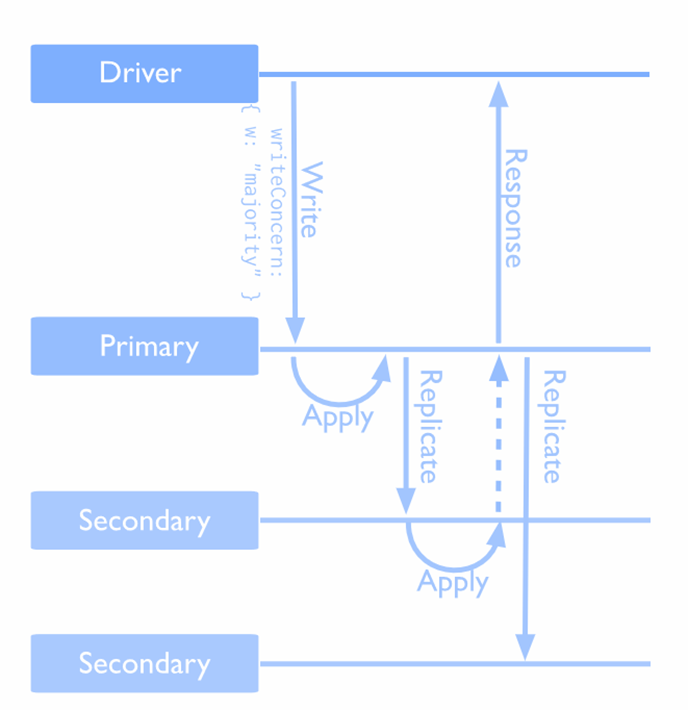
Можно настроить уровень консистентности — при отправке данных на все ноды, ждем подтверждения от 1 ноды, от 2 или большинства. Можно отключить подтверждение.
Можно комбинировать чтение/запись:
- подтверждение записи большинством голосов и журналирование {w:majority, j:true} — максимальная консистентность на чтение, максимальная отказоустойчивость, минимальная скорость
- отключаем подтверждение записи большинством голосов {w:1, j:true} — меньше консистентность, выше скорость
- отключаем журналирование {w:1, j:false} — еще ускоряемся, возникает вопрос отказоустойчивости
- отключаем любые проверки {w:0, j:false} — максимальная скорость, можем потерять несколько транзакций при краше
Доп.ссылки на изучение:
Write Concern — MongoDB Manual
ClickHouse
ClickHouse нужен, когда:
- Данных очень много – скорость их обработки штатными средствами не устраивает
- Нужно получать агрегированную информацию по этим данным
- Нужны оперативные и исторические данные – действительно Online
- Данные нужны на диске
Полезные ссылки
Достоинства и недостатки
Достоинства:
- Очень быстрые OLAP запросы (до х1000+ по сравнению с PostgreSQL) за счет колоночного хранения
- Данные хранятся на диске
- Сжатие из коробки в среднем до 3-7 раз
- SQL
- Кластеризация/репликация из коробки
Недостатки:
- Нет транзакций
- Очень медленное изменение данных — update это DDL операция !!! (alter table)
- Медленные одиночные Insert и Select — добавление одной записи занимает столько же времени, сколько целая пачка записей
- Не предназначен для OLTP
Архитектура ClickHouse
ClickHouse имеет столбцовую архитектуру — в строке хранится все значения данного поля (транспонированный вид классического хранения)
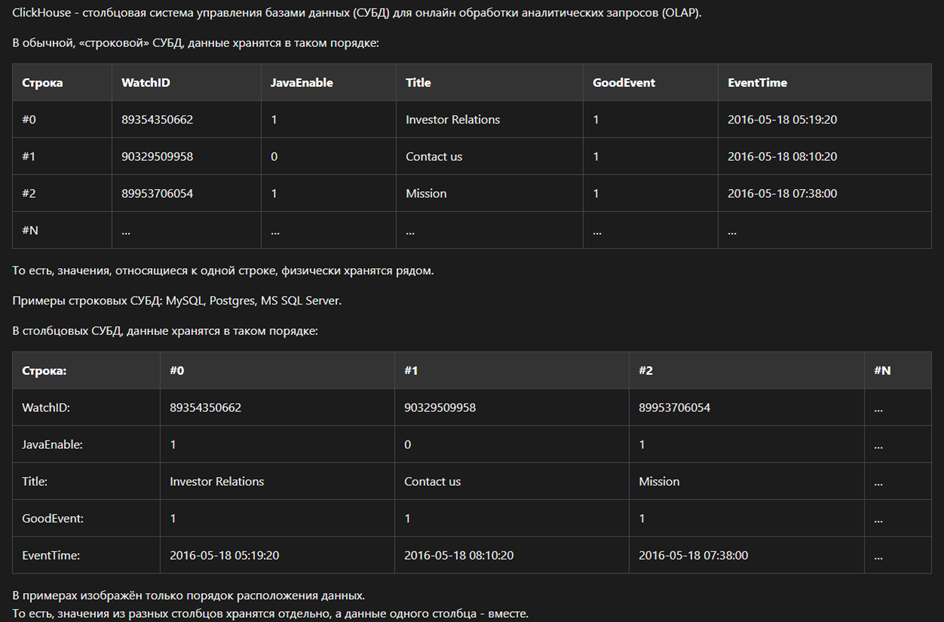
При такой архитектуре в одной строке (отдельные файлы) хранятся только однотипные данные, поэтому они очень хорошо сжимаются. Блоки с данными имеют меньшие размеры и быстрее считываются с диска. Также мы всегда знаем какие данные в каком диапазоне хранятся в файлах. Однако при таком виде хранения вставка одиночных записей очень медленные.
ClickHouse для логов
В современном мире очень часто логи собираются не только для поиска по ним источников проблем.
Для поиска ClickHouse подходит плохо – это не замена grep, awk, cut, tail (в основном расследование инцидентов)
По логам (особенно nginx) собираются метрики.
ClickHouse для метрик по логам позволяет узнать:
- Сколько было ошибок
- Сколько пользователей не аутентифицировалось
- Сколько потеряно пользователей из за падения сервиса
- Какой процент деградации производительности
- И т.д.
Схема хранения логов компании Uber:
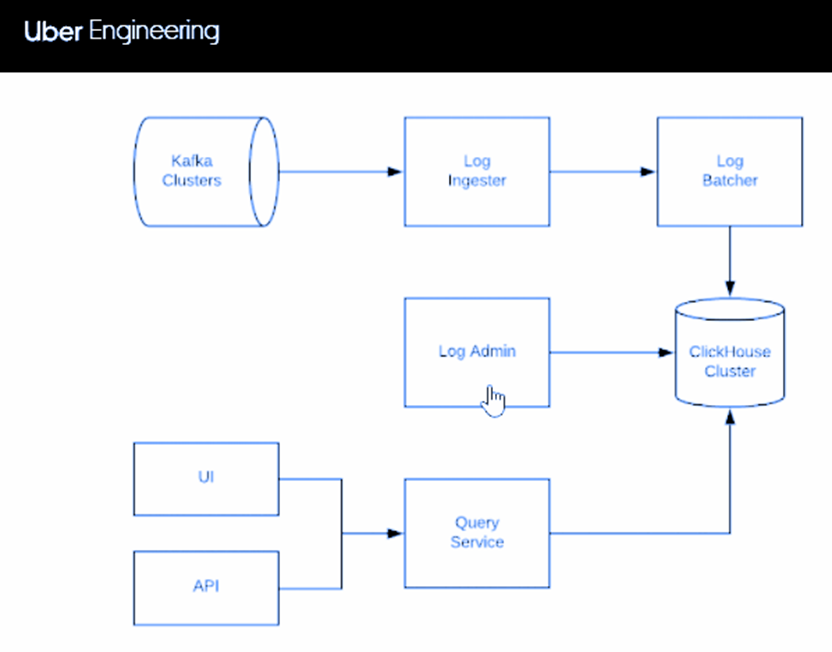
Хранение 20 Тб логов в ClickHouse
Вставка данных
Как упоминалось выше, в ClickHouse добавлять записи лучше пачками, а не по одной. Чем реже это делается, тем лучше. Этого можно достичь с помощью Kafka, которая раз в какое-то время заливает накопленные записи в БД (массовая вставка).
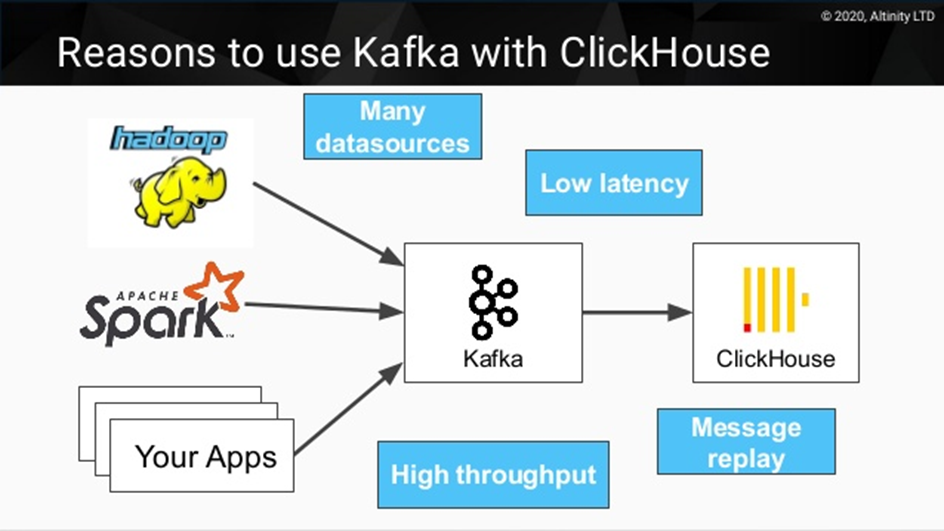
Ещё варианты для вставки данных пачками:
- kittenhouse
- clickhouse-bulk
- buffer table — ваш кастомный вариант сбора и последующей массовой вставки в ClickHouse
Другие столбцовые СУБД

Elasticsearch
Elasticsearch предназначен для полнотекстового поиска — ELK стек.
Elasticsearch используется при редкой записи/обновлении и активном чтении (поисковые индексы), активной записи и редком чтении (сбор логов и метрик)
Поиск в Elastic состоит происходит согласно условиям выборки в двух контекстах — Filter и Query. Filter — отвечает на вопрос “подходит ли документ под условия поиска”. Query — “насколько хорошо документ подходит под условия поиска” — ранжирует документы по релевантности
Поддерживает сложные агрегации с поминутной разбивкой и подсчетом кол-ва документов или вычислением максимального значения поля на заданном диапазоне
Преимущества:
- Кластеризация
- Отказоустойчивость
Недостатки:
- Геотеги работают плохо
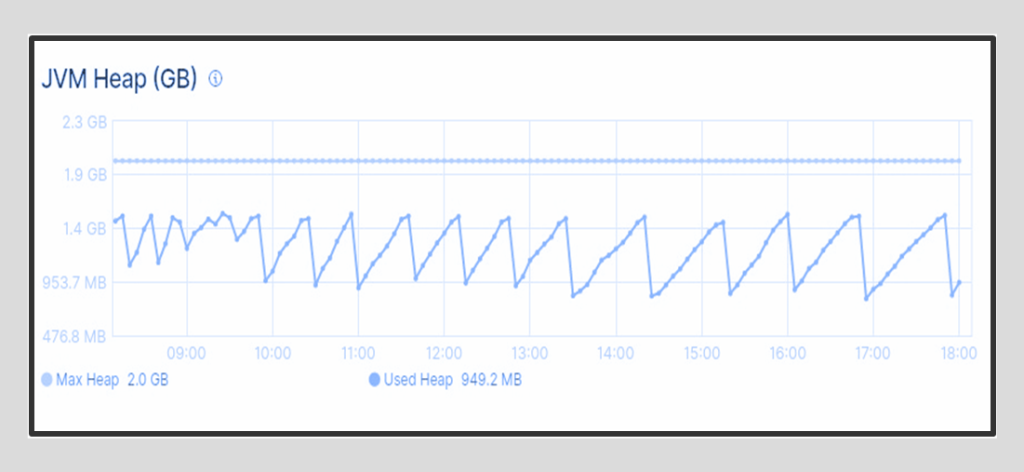
- Требует очень много памяти — реализован на Java с её известными проблемами
- Для экономии памяти нужно много шардов
Мониторинг памяти:
Альтернативы Elasticsearch:
Opensearch
OpenSearch — поисковая и аналитическая система с открытым исходным кодом в облаке | Yandex Cloud
Opensearch — продвинутый аналог Elasticsearch
Преимущества:
- функциональность машинного обучения
- быстрый поиск по векторам с помощью k‑NN (k‑Nearest Neighbor)
- управление безопасностью, индексами
- поиск и обнаружение аномалий
- поддержка SQL
- генерация уведомлений
- диагностика производительности кластера
- шифрование трафика
- разграничение доступа на основе ролей (RBAC)
- аутентификация через SAML и другие внешние источники авторизации
- реализация единой точки входа (SSO)
- ведение детального лога для аудита
Manticore Search
История создания
2001 — Старт разработки Sphinx (SQL Phrase Index).
2004 — Первая версия Solr
2010 — Sphinx является популярным полнотекстовым движком, его используют Хабрахабр, Викимапия и другие. Первый выпуск Elasticsearch
2017 — Код новой версии Sphinx 3 становится закрытым. Ключевые сотрудники Sphinx создают форк под названием Manticore Search, так как развитие приостановилось — Elasticsearch давно обогнал Sphinx
Возможности
- Полнотекстовый, фасетный и гео поиск
- Можно использовать без полнотекстового поиска
- Построчное и колоночное хранение данных
- MPP архитектура и распараллеливания запросов
- Синтаксис SQL (клиент mysql), SQL over HTTP, JSON over HTTP
- Декларативное и императивное управление схемой
- Изолированные транзакции для атомарных изменений
- Ведение двоичного журнала для безопасной записи
- Репликация (galera cluster) и балансировка нагрузки из коробки
- Percolate индексы (обратный поиск)
- Кеширование в RAM и малое потребление памяти
Применение
- Полнотекстовой поиск, например, электронная библиотека
- Фасетный поиск — интернет-магазин
- Геопространственный поиск — карты
- Онлайн обработка аналитических запросов (OLAP)
- Автозаполнение — фильтрация потока данных
Сравнение ClickHouse, Manticore Search, Elasticsearch
ClickHouse 22.7.5.13 vs Elasticsearch 7.17.6 vs Manticore Search 5.0.2.
Hacker News Curated Comments Dataset, 1 165 439 rows.
- Размер индекса ClickHouse = 454.555 MB
- Размер индекса Elasticsearch = 911.613 MB
- Размер индекса Manticore Search = 1037.85 MB
Аналитические запросы и полнотекстовой поиск

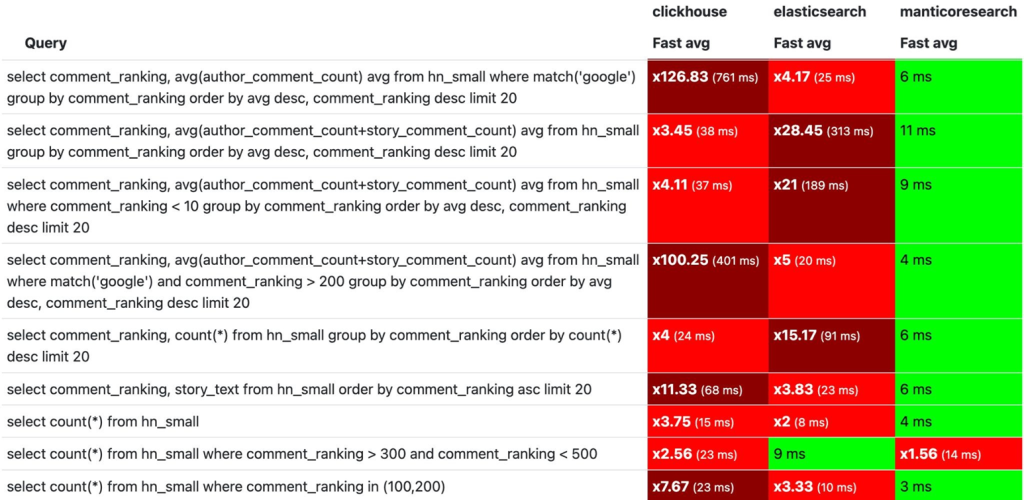
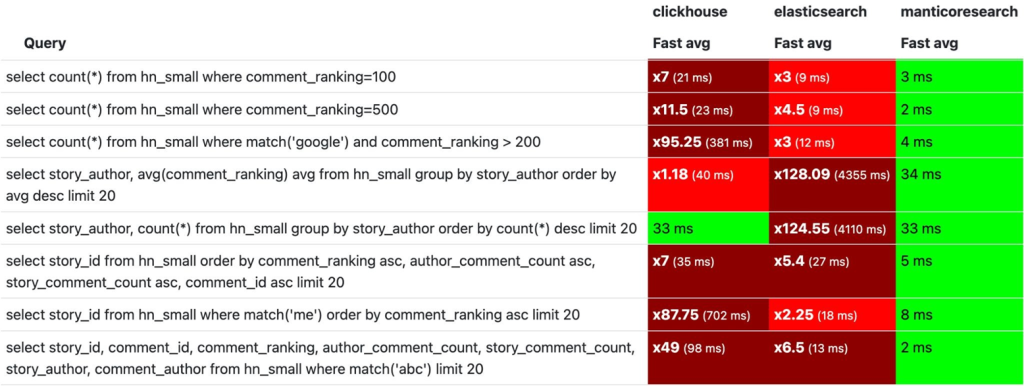
Практически во всех запросах у Manticore Search видим константное время.
Сравнение всех продуктов
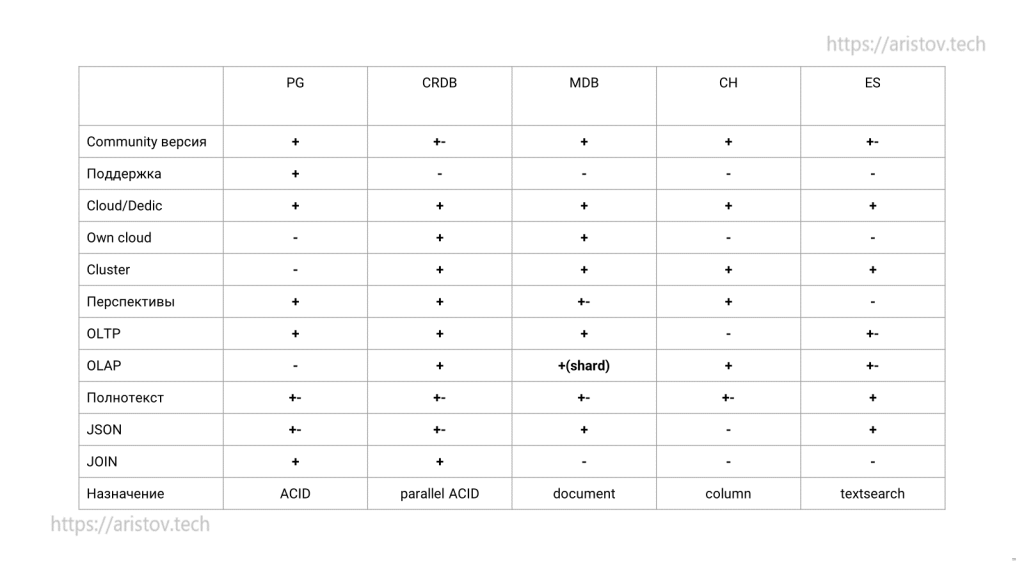
Полезное
Если нужно сравнить функционал и скорость разных СУБД:
Используем реплику ClickHouse для OLAP PostgreSQL
Если нужно переливать постоянно — CDC, например Debezium
Материалы к статье доступны на гитхаб.
Добавить комментарий