Статья основана на 13 видео из 30 тем курса SQL c 0 от Аристова Евгения. Ссылки на видео на платформах RUTUBE и VK видео.
Типы данных
В PostgreSQL довольно много типов данных.
Просмотреть их и их количество можно в документации или командами:
SELECT typname, typlen, typtype FROM pg_type;SELECT count(typtype) FROM pg_type;Значения типов разбиты по группам typtype:
- b — базовый тип (base)
- c — составной (composite)
- d — для домена (domain)
- e — перечисляемый (enum)
- p — псевдотип (pseudo-type)
- r — диапазон (range)
Просмотрим, например, все базовые типы:
SELECT typname, typlen, typtype FROM pg_type WHERE typtype='b';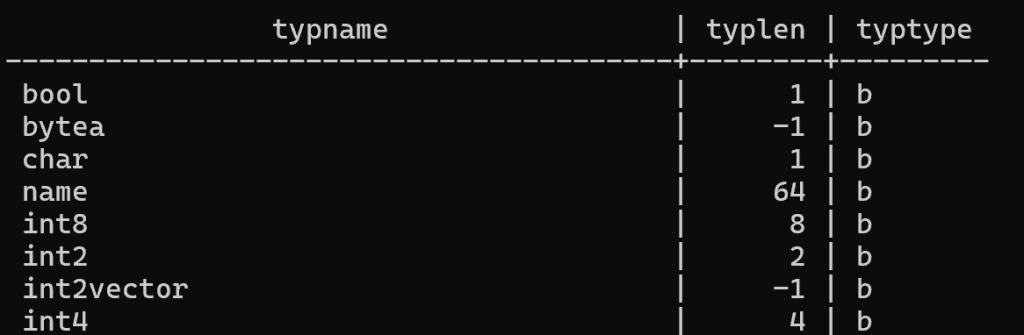
Всего 300+ типов. Рассмотрим основные.
Базовые типы данных
В основном используются всего 6 типов данных:
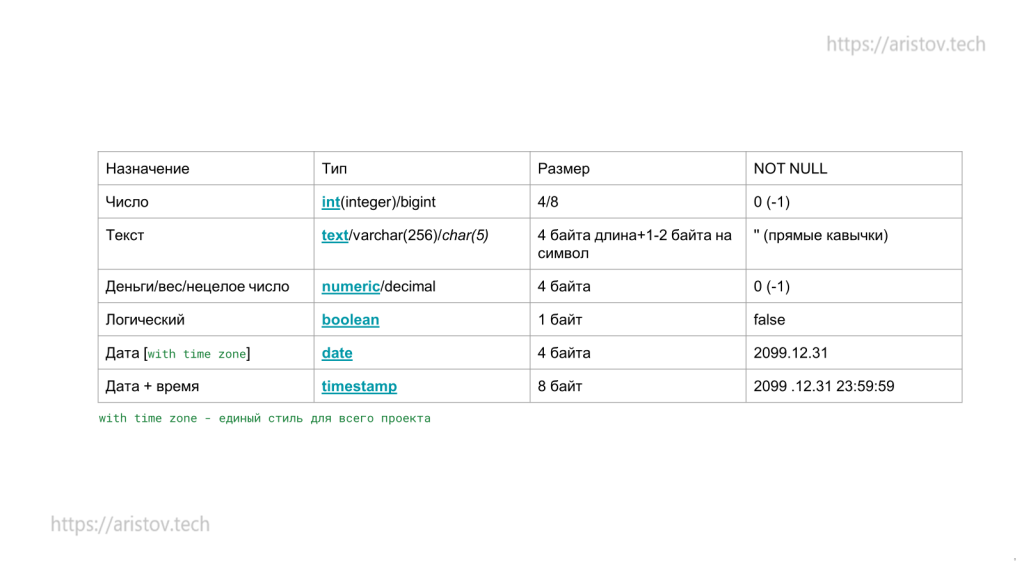
Колонка NOT NULL в таблице — варианты, чем можно заменить значение NULL, чтобы не использовать концепцию с NULLABLE значениями, основная проблема которых NULL != NULL и связанных с этим проблемами.
INT — простейшее число(4 байта), диапазон значений от -2 млрд до 2 млрд. BIGINT — большое число (8 байт). SERIAL основан на INT (диапазон тот же, подробнее в статье). В PostgreSQL нет беззнакового типа, поэтому для последовательностей длиной больше 2 млрд существует BIGSERIAL.
VARCHAR/TEXT — текст переменной длины (в VARCHAR можем ограничить длину поля), CHAR — текст фиксированной длины.
Рекомендации: использовать поля типа TEXT, так как в нём нет проверки на длину, проверку осуществлять на бэкенде; задавать для поля NOT NULL (пустые ячейки заполнять »).
NUMERIC/DECIMAL — вещественное число, можно задать количество символов до запятой и после неё. REAL — числа с плавающей точкой.
BOOLEAN — логический тип, который занимает 1 байт.
DATE — дата, можно сделать с учётом часового пояса (занимает столько же места). Рекомендуется использовать единый подход во всём проекте.
TIMESTAMP — дата + время
Напоминаю, что рекомендуется использовать кодировку UTF-8.
Финансовая арифметика
В PostgreSQL для денежных единиц рекомендуют использовать MONEY, но в данном типе данных могут быть проблемы с подсчетом у клиентов из Америки.
Отличие американской системы от остального мира:
- Считают до 0.001 доллара, а в остальном мире до 0.01
- Округляют к ближайшему четному(3.5->4 VS 3.5->3 ; 4.5->4 VS 4.5->4), а в остальном мире к ближайшему целому.
Подсчёт зависит от того, какие параметры локали установлены на сервере.
Текущие параметры локали:
SHOW lc_monetary Вместо MONEY можно использовать NUMERIC.
Преобразование типов
PostgreSQL: Documentation: 16: Chapter 10. Type Conversion
В PostgreSQL существует специальный оператор :: (двойное двоеточие)
Например, текст ’10’ можно попытаться преобразовать к вещественному типу — ’10’ :: real
Также есть набор функций для преобразования:
PostgreSQL: Documentation: 16: 9.8. Data Type Formatting Functions
Также можно скастовать тип (но такой каст должен существовать):
SELECT CAST ('expression' AS INTEGER);UUID
UUID занимает 32 байта, обычно предназначен для уникальных значений, повторяться не может.
Можно использовать для того, чтобы объединить информацию с разных серверов, чтобы сделать равномерное распределение.
Недостаток — большой вес (также заффектит на индекс и внешние ключи), относительно долгая генерация.
Статья про скорость работы UUID.
Практическое использование
Финансы
Создадим процедуру, в которой 10000 раз прибавим к DECIMAL и FLOAT 0.001. Предполагаем, что в результате должно быть одинаковое число.
CREATE or REPLACE PROCEDURE finance(inout x text)
as $$
DECLARE
i INTEGER DEFAULT 0;
numeric_ DECIMAL(10,4) DEFAULT 0;
float_ FLOAT DEFAULT 0;
BEGIN
LOOP
numeric_ := numeric_ + 0.001;
float_ := float_ + 0.001E0;
i := i + 1;
if i > 10000
then exit;
end if;
END LOOP;
x = numeric_ || ' ' || float_;
end;
$$
language plpgsql
;call finance('');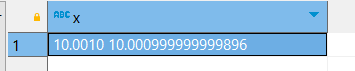
Получились два разных числа, что может сыграть большую роль в финансовых отчётах. Поэтому лучше использовать NUMERIC.
Кодировка
Просмотрим разницу в кодировке UTF русского и английского текста:
SELECT bit_length(‘test’);
SELECT bit_length(‘тест’);
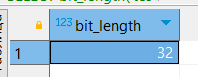
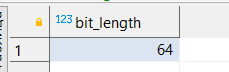
Английский текст занимает 1 байт на символ, а русский — в два раза больше. Если текст содержит более ~20 байт, то к нему применяются алгоритмы сжатия (более подробно рассматривается на курсе по оптимизации), поэтому потери из-за использования этой кодировки небольшие.
Описание
Описание типов данных:
Имя- тип_данных — ограничение — значение_по_умолчанию
name text NOT NULL DEFAULT »
Рекомендуется всегда указывать DEFAULT значение, которое будет записано, если какое-то поле не указано. Также если забыть указать какое-то поле, а на него установлено NOT NULL, то возникнет ошибка (DEFAULT поможет избежать этого).
Часовые пояса
Создадим таблицу Склад, в которую добавим поля salesTime (с зоной) и salesTime2 (без зоны).
DROP TABLE IF EXISTS warehouse;CREATE TABLE warehouse (id serial UNIQUE,
name text NOT NULL DEFAULT '',
kolvo int NOT NULL DEFAULT 0,
price numeric NOT NULL DEFAULT 0.0,
salesTime timestamp with time zone NOT NULL DEFAULT current_timestamp, -- UTC
salesTime2 timestamp NOT NULL DEFAULT current_timestamp
);
INSERT INTO warehouse(name) VALUES ('apple');
INSERT INTO warehouse(name, price) VALUES ('banana',2.1);
SELECT * FROM warehouse;В поле с временной зоной дополнительно хранится часовой пояс:

PostgreSQL может сравнить поле с часовым поясом и без (видит, что это один момент времени):
SELECT * FROM warehouse WHERE salesTime=salesTime2;
Преобразования типов
Преобразуем текстовое значение ’10 ‘ к real, numeric (с разным количеством символов), text
SELECT '10 '::real::numeric, '10'::numeric, '10'::numeric (10,2), '10'::text;
SELECT CAST('10' AS INTEGER);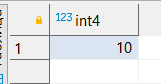
Преобразуем текстовую строку к дате, для этого нужно указать, в каком порядке записаны части даты:
SELECT to_date('05 May 2024', 'DD Mon YYYY');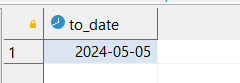
Как уже упоминалось в прошлой статье, при необходимости изменения типа поля рекомендуется создать поле нового типа, преобразовать туда старое поле, затем удалить старое и переименовать новое.
UUID
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE TABLE accounts (
id UUID PRIMARY KEY DEFAULT uuid_generate_v1(),
balance DECIMAL
);INSERT INTO accounts(balance) VALUES ('10');
SELECT * FROM accounts;
Просмотрим размер UUID:
SELECT bit_length(id::text) FROM accounts;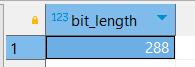
Презентация к статье здесь.
14 из 30 тем будет скоро доступна. Если вы хотите быстрее получить доступ – присоединяйтесь к онлайн группе, ссылка доступна в описании курса.
Добавить комментарий