Статья основана на 14 видео из 30 тем курса SQL c 0 от Аристова Евгения. Ссылки на видео на платформах RUTUBE и VK видео.
В одной из прошлых статей мы уже рассматривали ALTER&DROP для создания и удаления объектов. В этой статье узнаем, как эти объекты просматривать.
SELECT
SELECT нужен для просмотра уже существующих в БД записей. В среднем в RDBMS решениях 80-95% запросов основано на SELECT (остальное INSERT, UPDATE).
SELECT [ ALL | DISTINCT [ ON ( expression [, …] ) ] ]
[ * | expression [ [ AS ] output_name ] [, …] ]
[ FROM from_item [, …] ]DISTINCT — уникальные строчки (используют в JOIN), довольно дорогая операция, используйте в крайнем случае.
SELECT INTO
При необходимости записать результат выборки куда-либо используется SELECT INTO.
PostgreSQL: Documentation: 16: SELECT INTO
SELECT [ ALL | DISTINCT [ ON ( expression [, …] ) ] ]
* | expression [ [ AS ] output_name ] [, …]
INTO [ TEMPORARY | TEMP | UNLOGGED] [ TABLE ] new_table
[ FROM from_item [, …] ]TEMPORARY — сохранение во временную таблицу (только на время сессии)
UNLOGGED — нелогированная быстрая таблица, но никакой отказоустойчивости
Будут записаны только те поля, которые были выбраны с соответствующими типами. БЕЗ constraint, индексов, DEFAULT значений.
Рекомендации
Список полезных советов:
- Не используем * (подтягивается лишняя информация из TOAST на диске, порядок и количество столбцов не гарантированы после изменения схемы данных)
- Используем читаемый синтаксис
- Используем полное имя таблиц (с указанием схемы через точку)
- Используем алиасы AS (имена должны логически соответствовать и быть понятны)
Особенности:
- Обычно используется паджинация (вывод по 20-100 строк) — можно настроить в ЯП или GUI (DBeaver)
- Можно использовать хранимые процедуры для обработки, чтобы не выводить большие объемы информации
- При выходе за пределы work_mem — используется временное дисковое пространство (оно медленнее). В других СУБД также есть настройки, отвечающие за размер буфера и таймауты
Практика
Создаем таблицу Склад:
CREATE TABLE warehouse (
id serial UNIQUE,
name text NOT NULL DEFAULT '',
kolvo int NOT NULL DEFAULT 0,
price numeric NOT NULL DEFAULT 0.0,
salesTime timestamp with time zone NOT NULL DEFAULT current_timestamp, -- UTC
salesTime2 timestamp NOT NULL DEFAULT current_timestamp
);
INSERT INTO warehouse(name) VALUES
('apple');
INSERT INTO warehouse(name, price) VALUES
('banana',2.1);В SELECT можно выполнять арифметические операции:
SELECT 1+1;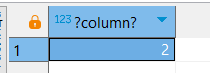
Пример использования * (не рекомендуется):
SELECT *
FROM warehouse;
Правильный способ выбора всех полей (перечисление полей в запросе):
SELECT id,name,kolvo,price,salesTime
FROM warehouse;
Поля можно перечислять в любом порядке (от этого зависит то, в каком порядке они будут выведены):
SELECT name,id,kolvo,price,salesTime
FROM warehouse;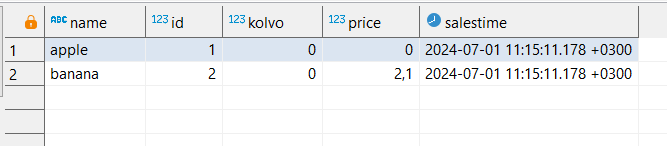
Непосредственно в SELECT можно сразу преобразовывать типы:
SELECT name,id,kolvo,price,salesTime::date
FROM warehouse;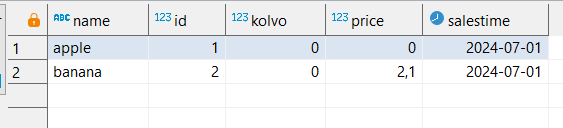
Также можно использовать функции:
SELECT name,id,kolvo,price,(salesTime + '1 day')::date
FROM warehouse;
Создадим схему Продажи с таблицей Склад внутри:
CREATE SCHEMA sales;
CREATE TABLE sales.warehouse (
id serial UNIQUE,
name text NOT NULL DEFAULT '',
kolvo int NOT NULL DEFAULT 0,
price numeric NOT NULL DEFAULT 0.0,
salesTime timestamp with time zone NOT NULL DEFAULT current_timestamp, -- UTC
salesTime2 timestamp NOT NULL DEFAULT current_timestamp
);На сложные поля, если не понятно из названия, лучше давать комментарий:
comment on column sales.warehouse.salesTime2 is 'Дата продажи';Вставим значения:
INSERT INTO sales.warehouse(name) VALUES
('apple');
INSERT INTO sales.warehouse(name, price) VALUES
('banana',2.1);
INSERT INTO sales.warehouse(name) VALUES
('apple');Всегда нужно обращаться к полю в форме «схема.таблица.поле», так как при совпадении имен полей в разных таблицах PostgreSQL выдаст ошибку. Чтобы не прописывать каждый раз «схема.таблица», можно дать короткое имя (ALIAS), в данном случае «w»:
SELECT w.name,
w.id,
w.kolvo,
w.price,
(w.salesTime + '1 day')::date AS nextDay
FROM sales.warehouse w;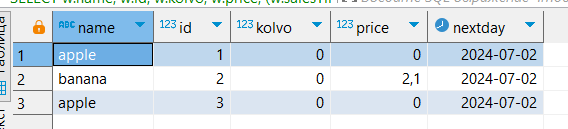
Если ставить запятую не в конце строки, а в начале, то можно закомментировать любое поле:
SELECT w.name
-- ,w.id
,w.kolvo
,w.price
,(w.salesTime + '1 day')::date AS nextDay --в комментарии после формулы лучше написать, что она значит
FROM sales.warehouse w;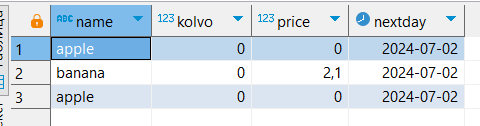
Выбор уникальный имён с помощью DISTINCT (очень дорогая по времени и памяти операция):
SELECT DISTINCT w.name
FROM sales.warehouse w;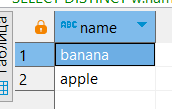
Создадим таблицу w2 с помощью SELECT INTO:
SELECT w.name
-- ,w.id
,w.kolvo
,w.price
,(w.salesTime + '1 day')::date AS nextDay
INTO w2
FROM sales.warehouse w;Посмотрим, что хранится в w2:
SELECT *
FROM w2;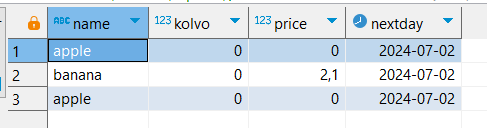
Презентация к статье здесь.
15 из 30 тем будет скоро доступна. Если вы хотите быстрее получить доступ – присоединяйтесь к онлайн группе, ссылка доступна в описании курса.
Добавить комментарий