Статья основана на 16 видео из 30 тем курса SQL c 0 от Аристова Евгения. Ссылки на видео на платформах RUTUBE и VK видео.
В прошлых статьях мы уже рассматривали некоторые команды в PostgreSQL — SELECT, ALTER&DROP, WHERE. В этой статье изучим INSERT.
После создания базы и схемы данных нужно загружать непосредственно данные, так как без них база данных не имеет смысла.
INSERT
Стандартно данные собираются по каким-то критериям и загружаются в базу командой INSERT.
Вставляем в конкретную таблицу значения:
INSERT INTO table_name [ AS alias ] [ ( column_name [, …] ) ]
{ DEFAULT VALUES | VALUES ( { expression | DEFAULT } [, …] ) [, …]Можно вставить предварительную выборку SELECT в другую таблицу:
INSERT INTO table_name [ AS alias ] [ ( column_name [, …] ) ]
SELECT …Обратите внимание, что SELECT INTO создает новую таблицу, а INSERT INTO SELECT добавляет в существующую.
Создадим аналогичную всем прошлым статьям таблицу Склад:
DROP TABLE IF EXISTS warehouse;
CREATE TABLE warehouse (
id serial UNIQUE,
name text NOT NULL DEFAULT '',
kolvo int NOT NULL DEFAULT 0,
price numeric NOT NULL DEFAULT 0.0,
salesTime timestamp with time zone NOT NULL DEFAULT current_timestamp, -- UTC
salesTime2 timestamp NOT NULL DEFAULT current_timestamp
);
Напишем самый простой запрос:
INSERT INTO warehouse VALUES
(DEFAULT,'apple');
SELECT *
FROM warehouse;
Обратите внимание, что в данном запросе не указаны конкретные поля, в которые нужно вставить данные. В таком случае поля заполняются по порядку. Первое поле «id» явно указано «DEFAULT» (заполнить DEFAULT значением — следующий номер из автоматически созданной последовательности. Подробнее будем разбирать в 13 теме), «name» также указано явно, остальные поля тоже заполнились значением по умолчанию. Важно, что если бы при создании таблицы не было бы указано это значение, то возникла бы ошибка, так как PostgreSQL не знал бы, чем заполнить не указанные ячейки.
Теперь напишем запрос, в котором явно указаны поля и соответствующие им значения:
INSERT INTO warehouse (id, name) VALUES
(DEFAULT,'apple');
Добавилась ещё одна строчка. Не указанные столбцы снова заполнились DEFAULT значением.
Также можно добавлять несколько строк сразу, указывая вставляемые значения в скобках через запятую:
INSERT INTO warehouse(id, name) VALUES
(DEFAULT,'apple'),
(DEFAULT,'grape');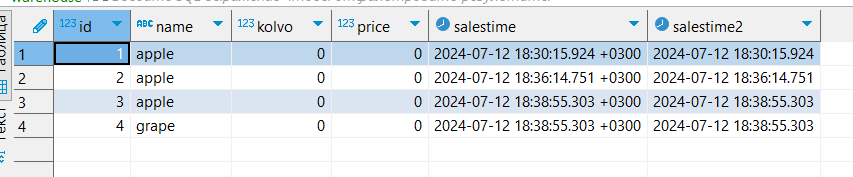
Добавились две строки. Их id — 3 и 4.
Выполним ещё один запрос, снова вставив две строчки. Но теперь заполним цену не значением по умолчанию, а нашим значением:
INSERT INTO warehouse(name,kolvo,price) VALUES ('apple',10,10.2),('grape',20,'20.2');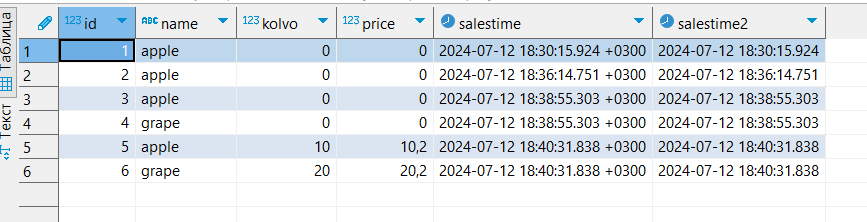
Если в NUMERIC поле используется не целое значение, то оно может быть указано в кавычках, как и TEXT, и TIMESTAMP.
Более наглядный вид запроса (не в одну строку):
INSERT INTO warehouse(name,kolvo,price) VALUES
('apple',10,10.2)
,('grape',20,'20.2');В PostgreSQL по умолчанию включен AUTOCOMMIT, то есть все команды оборачиваются в транзакции (подробнее о транзакциях в моей статье). Это затратный по времени процесс. Таким образом, при вставке, например, 100 строк разными командами запустится 100 транзакций. А при вставке этих же 100 строк одной командой запустится только одна транзакция.
Напишем запрос вида INSERT INTO … SELECT:
INSERT INTO warehouse(name,kolvo,price)
SELECT name,kolvo,price
FROM warehouse
LIMIT 1;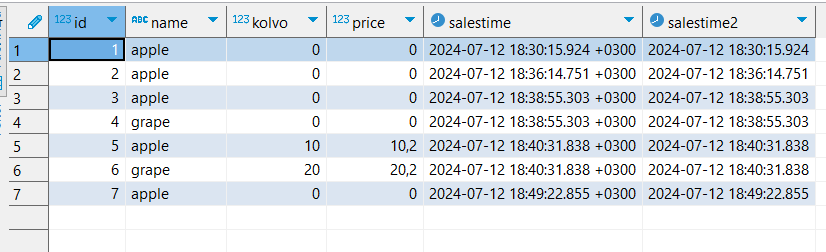
В данном примере скопировалась первая строчка этой же таблицы (в выборке SELECT стоит LIMIT 1, который ограничивает выборку одной строкой). Этим способом можно вставить миллионы строк из любой выборки.
ON CONFLICT
Во время вставки данных могут возникать ошибки.
Попробуем вставить строку с уже существующим id:
INSERT INTO warehouse(id,kolvo) VALUES
(1,10);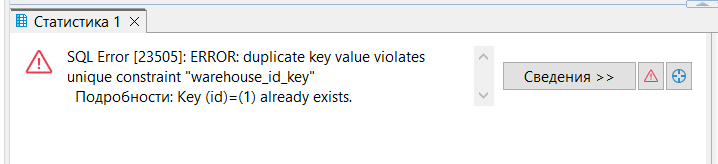
Возникла ошибка уникальности из-за установленного ограничения — constraint.
Иногда мы не можем добавить значение из-за ограничения целостности. Классика — такое уникальное значение уже существует.
Конструкция ON CONFLICT позволяет обработать конфликты (ограничения).
[ ON CONFLICT [ conflict_target ] conflict_action ]where conflict_target can be one of:
( { index_column_name | ( index_expression ) } [ COLLATE collation ] [ opclass ] [, …] ) [ WHERE index_predicate ]
ON CONSTRAINT constraint_nameand conflict_action is one of:
DO NOTHING
DO UPDATE SET { column_name = { expression | DEFAULT } |
( column_name [, …] ) = [ ROW ] ( { expression | DEFAULT } [, …] ) |
( column_name [, …] ) = ( sub-SELECT )
} [, …]
[ WHERE condition ]При возникновении конфликта старых и новых данных можно ничего не делать (DO NOTHING), тогда возникнет предупреждение, либо обновить конфликтующую строчку (DO UPDATE).
Например, во время завоза на склад уже прописанных в базе данных наименований, нужно не создавать новые строчки (заново добавляя товары), а в старых строчках добавлять количество.
Напишем запрос для обновления количества при конфликте по полю id:
INSERT INTO warehouse AS w(id,kolvo) VALUES
(1,10)
ON CONFLICT (id)
DO UPDATE SET kolvo = w.kolvo + EXCLUDED.kolvo;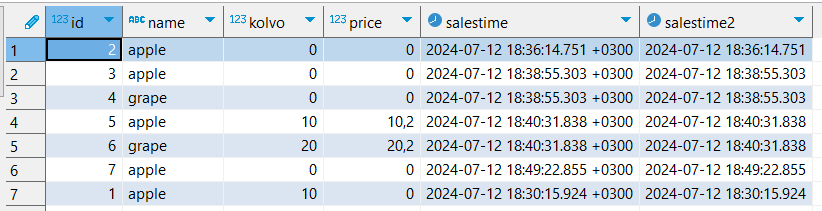
Обновленная строчка появилась внизу.
В некоторых СУБД есть специальная команда UPSERT, предназначенная для таких случаев. Но в PostgreSQL этой команды нет, но в целом это аналогичная замена.
Запрос для игнорирования конфликта:
INSERT INTO warehouse AS w(id,kolvo) VALUES
(1,10)
ON CONFLICT (id)
DO NOTHING;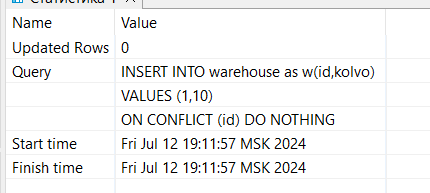
Параметр Updated Rows равен 0, значит ничего не произошло (появился конфликт, новая строка не была вставлена, но и шибка также не произошла).
Нельзя создавать несколько условий для конфликта:
INSERT INTO warehouse AS w(id,kolvo) VALUES
(1,10)
ON CONFLICT (id)
DO UPDATE SET kolvo = w.kolvo + EXCLUDED.kolvo
ON CONFLICT (name)
DO UPDATE SET kolvo = w.kolvo + EXCLUDED.kolvo;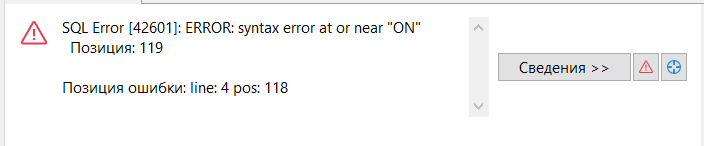
Удалим все данные из нашей таблицы и настроим новое ограничение — уникальность имени товара, затем вставим данные:
DELETE
FROM warehouse;
CREATE UNIQUE INDEX idx_warehouse_name ON warehouse(name);
INSERT INTO warehouse(id,name,kolvo,price) VALUES
(1,'apple',10,10.2),
(2,'grape',20,'20.2');
Теперь попробуем снова настроить двойной конфликт, когда в нашей таблице уже два уникальных поля:
INSERT INTO warehouse AS w(name,kolvo) VALUES
('apple',10)
ON CONFLICT (id,name)
DO UPDATE SET kolvo = w.kolvo + EXCLUDED.kolvo;
Мы всё равно не можем обработать такой конфликт. Для реализации ограничения можно написать хранимую процедуру с EXCEPTION, либо создать третье уникальное поле, состоящее из комбинации предыдущих двух (в таком случае в ON CONFLICT должен проверять именно его).
RETURNING
Команда INSERT после добавления данных может возвращать какие-либо значения. Например, вернуть id, который был автоматически присвоен новой строке.
[ RETURNING * | output_expression [ [ AS ] output_name ] [, ...] ]При указании * вернутся все поля, которые были обновлены/записаны.
Запрос, который возвращает id новой записи, которое можно использовать в дальнейших запросах:
INSERT INTO warehouse(id, name) VALUES
(DEFAULT,'apple888')
RETURNING id;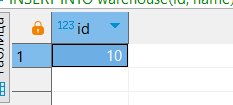
Обновленная таблица:

У новой строки действительно id равен 10.
Batch load
Как уже упоминалось выше, одна транзакция работает быстрее, чем несколько.
Создадим процедуру для добавления 10000 строк:
CREATE or replace PROCEDURE trans(x int)
AS $$
BEGIN
FOR i in 1..10000 LOOP
INSERT INTO warehouse(name) VALUES ('apple'||i);
IF x = 1 THEN
COMMIT;
END IF;
END LOOP;
END;
$$ LANGUAGE plpgsql;При передаче в данную процедуру «1» на каждую строчку будет создана новая транзакция, а при передаче «0» — одна транзакция на всё.
Сравним время выполнения процедур:
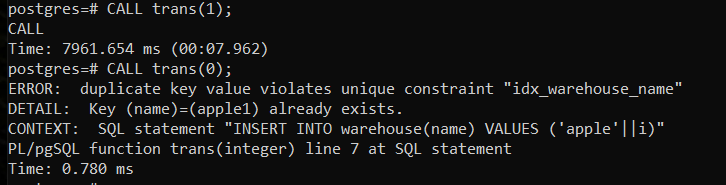
Время отличается в ~тысячу раз.
Рекомендации
Оптимальные размеры батчей при вставке данных от 100 тыс. до 1 млн. строк. При таких размерах батчей не должно произойти выхода за размер буферов
Для ускорения работы можно заменить INSERT на COPY, так как он работает быстрее. Копировать можно из текстового .csv файла. В 17 версии PostgreSQL COPY скорее всего будет ещё значительно ускорен.
Во избежание конфликтов можно отключить индексы, триггеры и внешние ключи если позволяет логика
Лучше использовать ANALYZE после больших вставок
COPY in 16 Postgres can be 300% faster
Презентация к статье здесь.
17 из 30 тем будет скоро доступна. Если вы хотите быстрее получить доступ – присоединяйтесь к онлайн группе, ссылка доступна в описании курса.
Добавить комментарий