Статья основана на 30 видео из 30 тем курса SQL c 0 от Аристова Евгения. Ссылки на видео на платформах RUTUBE и VK видео.
Ранее в блоге уже выходили статьи про транзакции и уровни изоляции транзакций. В этой статье рассмотрим данные темы подробнее.
ACID
Следование принципам ACID позволяет обеспечить параллельную нагрузку.
Параллельная нагрузка:
- Одновременная работа множества сессий
- Модификация данных таким образом, чтобы пользователи не мешали друг другу ни с точки зрения чтения, ни с точки зрения записи
- Целостность данных
ACID — это:
Atomicity — Атомарность
Consistency — Согласованность
Isolation — Изолированность
Durability — Долговечность
Соответствие принципам ACID достигается с помощью транзакций.
Транзакции
Транзакция — это одна или более операций, выполняемых приложением, со следующими свойствами:
- Транзакция выполняется или отменяется полностью (атомарность)
- Параллельные транзакции не мешают друг другу (изолированность)
- Транзакция переводит базу данных из одного корректного состояния в другое корректное состояние (согласованность)
OLTP — Online Transaction Processing — Транзакционные системы (системы для выполнения большого количества маленьких запросов)
Начало транзакции с помощью одно из вариантов:
BEGIN;
BEGIN TRANSACTION;
START TRANSACTION;Подтверждение (фиксация) транзакции (два варианта):
COMMIT;
COMMIT TRANSACTION;Отмена транзакции (два варианта):
ROLLBACK;
ROLLBACK TRANSACTION;Если внутри транзакции произошла какая-то ошибка, то её невозможно будет зафиксировать, а только отменить. Дальнейшие команды после ошибки выполнены также не будут.
Уровни изоляции транзакций
Стандарт SQL допускает 4 уровня изоляции транзакций, которые определяются в терминах аномалий, которые допускаются при конкурентном выполнении транзакций на этом уровне.
Аномалии:
- dirty read («грязное» чтение): одна транзакция может читать ещё не зафиксированные изменения в данных от другой транзакции. ROLLBACK (отмена) второй транзакции приведет к тому, что первая прочитает данные, которых никогда не существовало. Большинство СУБД не разрешают такой уровень изоляции.
- non-repeatable read (неповторяющееся чтение): если первая транзакция прочитала строку, а вторая транзакция изменила или удалила эту строку и выполнила COMMIT (фиксацию), то при повторном чтении этой же строки первой транзакцией, будет видно строка изменена или удалена.
- phantom read (фантомное чтение): если первая транзакция прочитала набор строк по некоторому условию, а затем вторая транзакция добавила строки, также удовлетворяющие этому условию, то при повторении запроса первой транзакцией, она получит обновленную выборку строк.
- serialization anomaly (аномалия сериализации): СУБД пытается выстроить транзакции последовательно во всех возможных комбинациях. При невозможности одного из вариантов происходит данная ошибка.
Рассмотрим, какие аномалии возможны на разных уровнях изоляции транзакций:
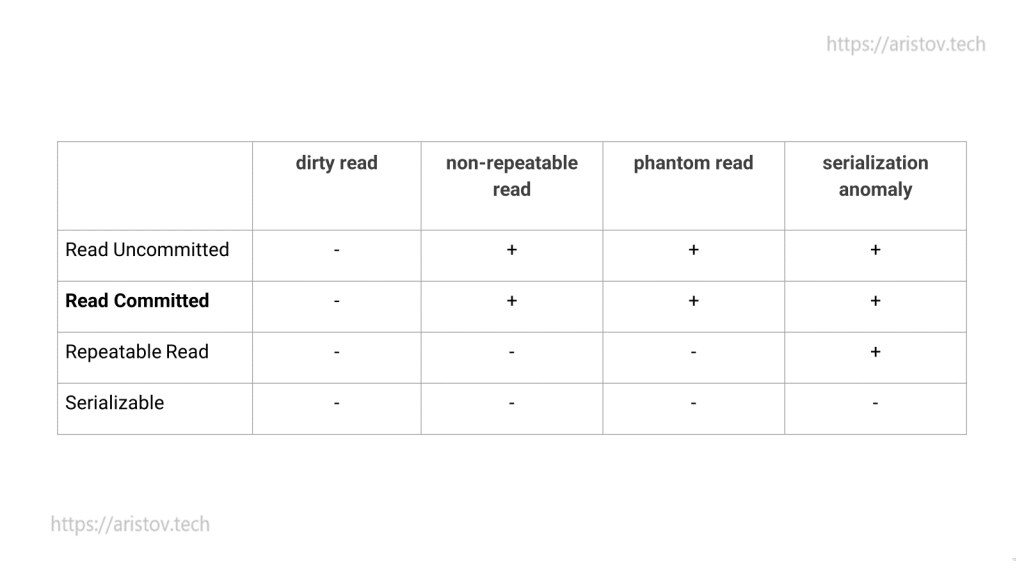
На всех уровнях не допускается потеря зафиксированных изменений, то есть реализуется буква D — Durability, но для этого должен быть включен синхронный commit (параметр synchronous_commit на уровне local или выше).
Повышение уровня изоляции влечет расходы ресурсов.
Разберем пример аномалии сериализации из документации.
Пусть есть таблица с Классом и Значением:
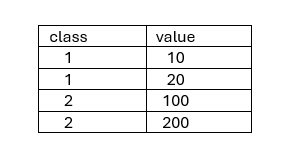
Первая транзакция считает сумму по первому классу:
SELECT SUM(value)
FROM mytab
WHERE class = 1;Далее эта транзакция хочет записать значение суммы во второй класс.
Вторая транзакция считает сумму по второму классу:
SELECT SUM(value)
FROM mytab
WHERE class = 2;Затем, наоборот, хочет записать значение в первый класс.
PostgreSQL выдаст ошибку, связанную с тем, что не может выстроить транзакции в таком порядке, чтобы они не мешали друг другу:
ERROR: could not serialize access due to read/write dependencies among transactionsПри уровне Repeatable Read такой ошибки бы не возникло и обе транзакции были бы зафиксированы.
PostgreSQL по умолчанию работает на уровне Repeatable Commited.
Практика
Для рассмотрения практического примера будем работать из двух консолей одновременно (для начала двух разных транзакций).
Сначала удалим таблицу, если она существует, а затем создадим заново и вставим одно значение:
DROP TABLE IF EXISTS test;
CREATE TABLE test(
i int
);
INSERT INTO test VALUES
(1);
SELECT * FROM test;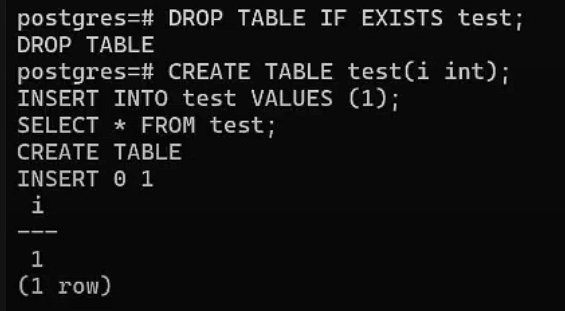
В первом окне начнем транзакцию и сделаем внутри неё выборку:
BEGIN;
SELECT *
FROM test;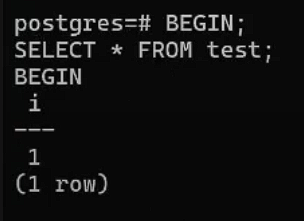
Во втором начнем транзакцию, обновим строку и завершим транзакцию:
BEGIN;
UPDATE test
SET i = 777
WHERE i = 1;
COMMIT;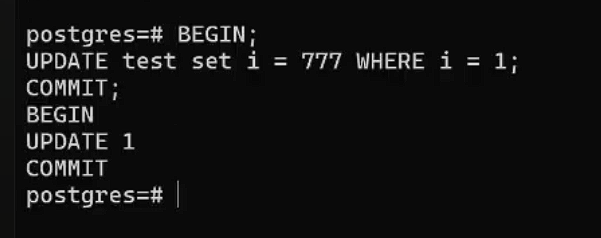
Далее в первом окне повторим выборку:
SELECT *
FROM test;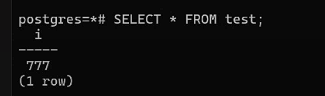
Видим аномалию неповторяющегося чтения — одинаковый запрос на выборку внутри одной транзакции дал разный результат (так как другая транзакция уже зафиксировала свои изменения).
Отменим транзакцию в первом окне (выборку):
ROLLBACK;
Теперь в первом окне начнем транзакцию на конкретном уровне изоляции и сделаем выборку:
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SELECT *
FROM test;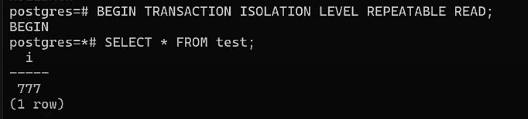
Во втором окне начнем транзакцию, добавим значение, завершим:
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
INSERT INTO test VALUES
(888);
COMMIT;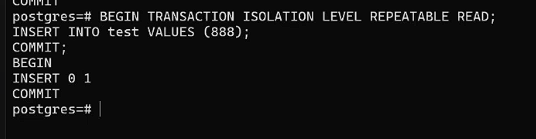
Теперь в первом окне уже зафиксированных изменений не видно:
SELECT *
FROM test;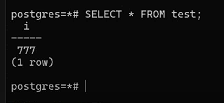
Причина в измененном уровне изоляции.
Повторим на практике пример из документации.
В первом окне создадим новую таблицу (без транзакции):
DROP TABLE IF EXISTS STest;
CREATE TABLE Stest (
i int,
amount int
);
INSERT INTO sTEST VALUES
(1,10),
(1,20),
(2,100),
(2,200);
SELECT *
FROM stest;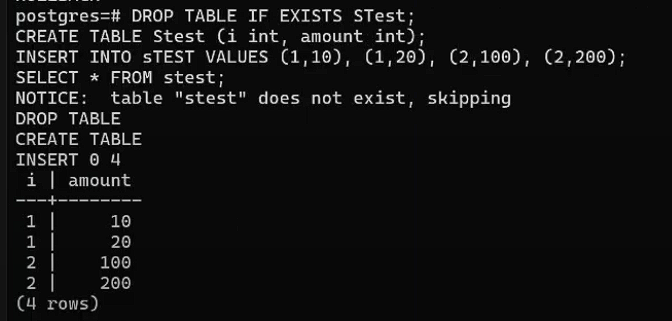
В этом же окне начнем транзакцию на конкретном уровне, сделаем внутри неё выборку (подсчет суммы для первого класса) и вставим результат выборки в таблицу во второй класс:
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SELECT sum(amount)
FROM stest
WHERE i = 1;
INSERT INTO stest VALUES
(2,30);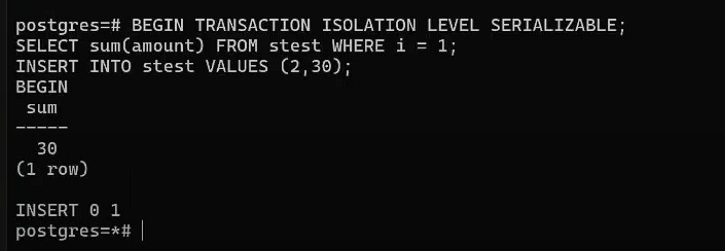
Теперь во втором окне подсчитаем сумму для второго класса и вставим в первый:
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SELECT sum(amount)
FROM stest
WHERE i = 2;
INSERT INTO stest VALUES
(1,300);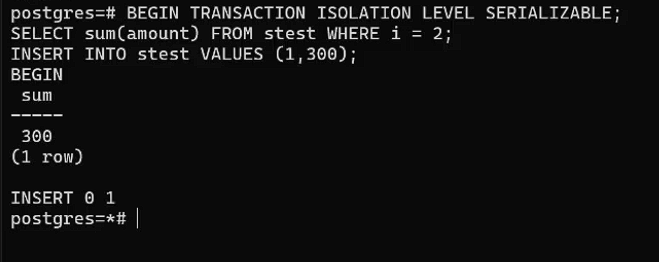
Фиксация изменений во втором окне:
COMMIT;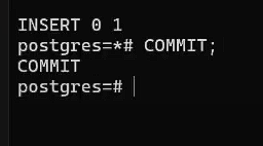
Ошибка при фиксации в первом окне:
COMMIT;
На уровне REPEATABLE READ никаких ошибок с аналогичным запросом не возникнет.
Презентация к статье здесь.
Заключение
Вы прочитали последнюю, 30 из 30, статью курса SQL с 0 от Евгения Аристова.
Для тех, кто вдохновился этим курсов и готов изучать PostgreSQL дальше, у меня есть курс по оптимизации PostgreSQL.
Надеюсь, этот курс дал вам прочную основу для работы с PostgreSQL, теперь вы можете создавать запросы для анализа данных, управления базами данных и даже автоматизации рутинных задач.
Помните, что PostgreSQL — это мощный инструмент, его возможности безграничны. Не останавливайтесь на достигнутом, продолжайте изучать.
Хотите узнать больше?
- Каждая статья была основана на моем видео на YouTube, смотрите их все в плейлисте на моем канале.
- Читайте другие статьи в блоге
- Подпишитесь на канал ютуб, канал TG чтобы не пропустить новые видео по PostgreSQL!
- Следите за анонсами открытых уроков, моего курса по оптимизации PostgreSQL и других активностей проекта aristov.tech.
Добавить комментарий