Когда мы изменяем страницы данных в памяти, они не сразу попадают на диск. А ведь у нас просто может упасть кластер, причин множество. А наша задача — обеспечить возможность восстановления согласованности данных после сбоя — Durability в ACID.
Для этого применяется механизм упреждающей записи — используется журнал (WAL — write ahead log):
- при изменении данных действие записывается в журнал
- журнальная запись попадает на диск раньше изменённых данных
- восстановление после сбоя — повторное выполнение потерянных операций с помощью журнальных записей
Что туда попадает:
- изменение любых страниц в буферном кэше
- фиксация и отмена транзакций (про транзакции здесь и здесь) — буферы XACT
НЕ ПОПАДАЮТ — временные и нежурналируемые таблицы
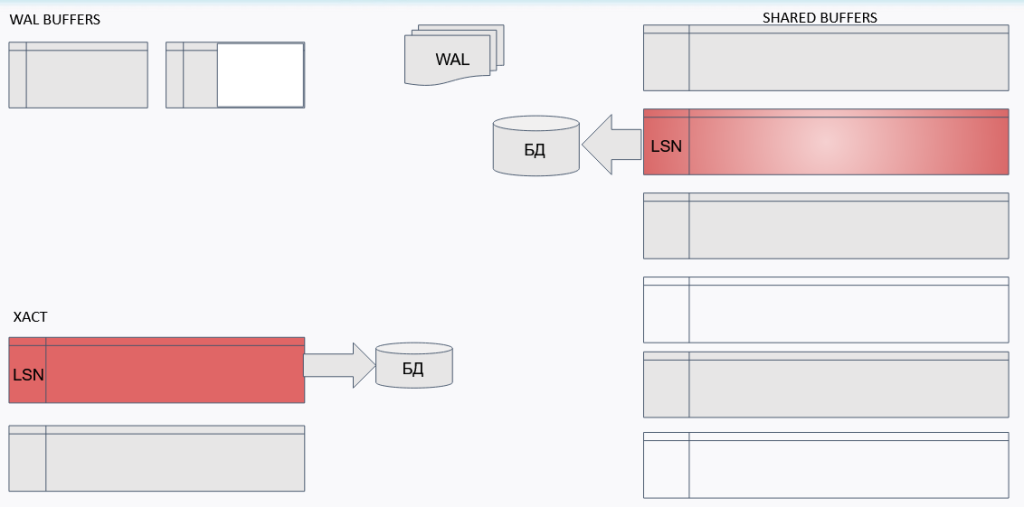
Схематично можно изобразить:
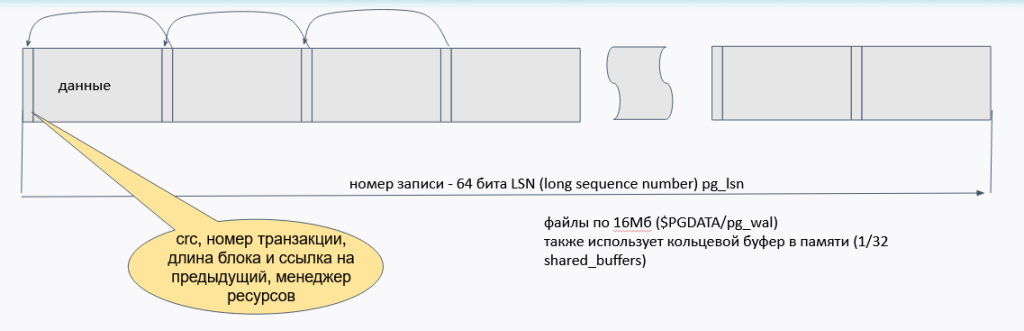
То есть изменённые блоки попадают сначала в журнал, а потом уже когда-нибудь (точнее посмотрим дальше) — на жёсткий диск. Опять же, журнал пишется на диск не в ту же долю секунды — есть определённая задержка:

Данные должны дойти до энергонезависимого хранилища через многочисленные кэши — СУБД сообщает операционной системе способом, указанным в wal_sync_method. При этом не забываем про аппаратное кэширование. При этом я не учитываю сетевые массивы.
Посмотрим на параметры:
SHOW fsync;
SHOW wal_sync_method;
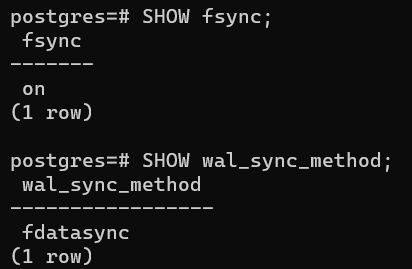
Изменить их можем в postgresql.conf.
Утилита pg_test_fsync помогает выбрать оптимальный способ.
Пишем изменённые данные в буфер и в WAL-буфер. На самом деле запись идёт не сразу в файл логов, а в буфер файла логов.
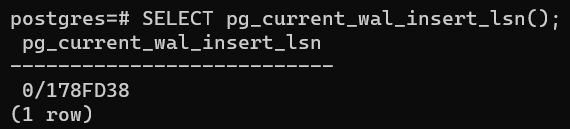
При этом данные записываются в буфер с текущим номером:
SELECT pg_current_wal_insert_lsn();
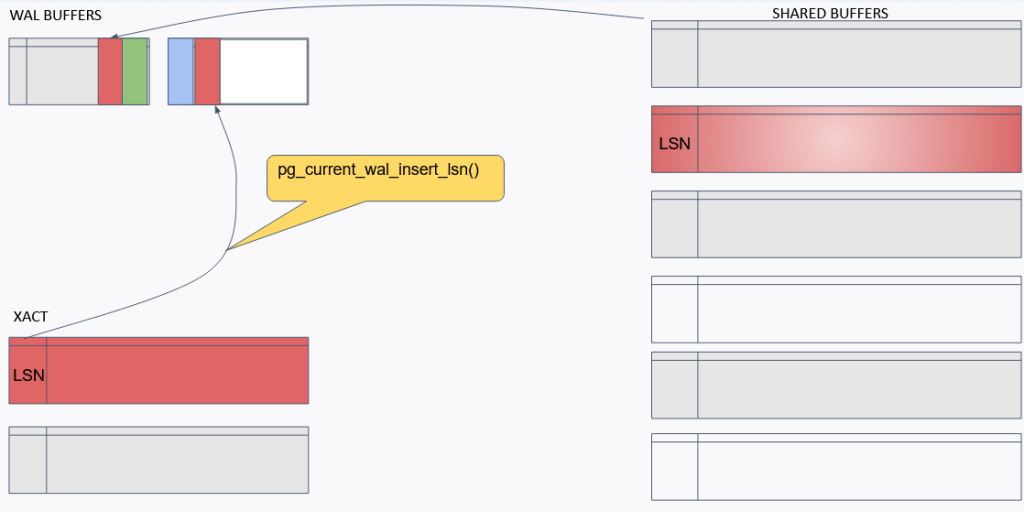
XACT — мультитранзакции тоже пишут свои данные в буфер.
Потом при наступлении определённого события происходит вызов команды записи данных на жёсткий диск.
После записи WAL-буфера на диск уже пишутся сами данные:
Соответственно, при при старте сервера после сбоя (состояние кластера в pg_control отличается от «shut down») происходит следующий сценарий:
- для каждой журнальной записи определяем страницу, к которой относится эта запись
- применяем запись, если её LSN больше, чем LSN страницы
- перезаписываем нежурналируемые таблицы init-файлами
Посмотрим на практике.
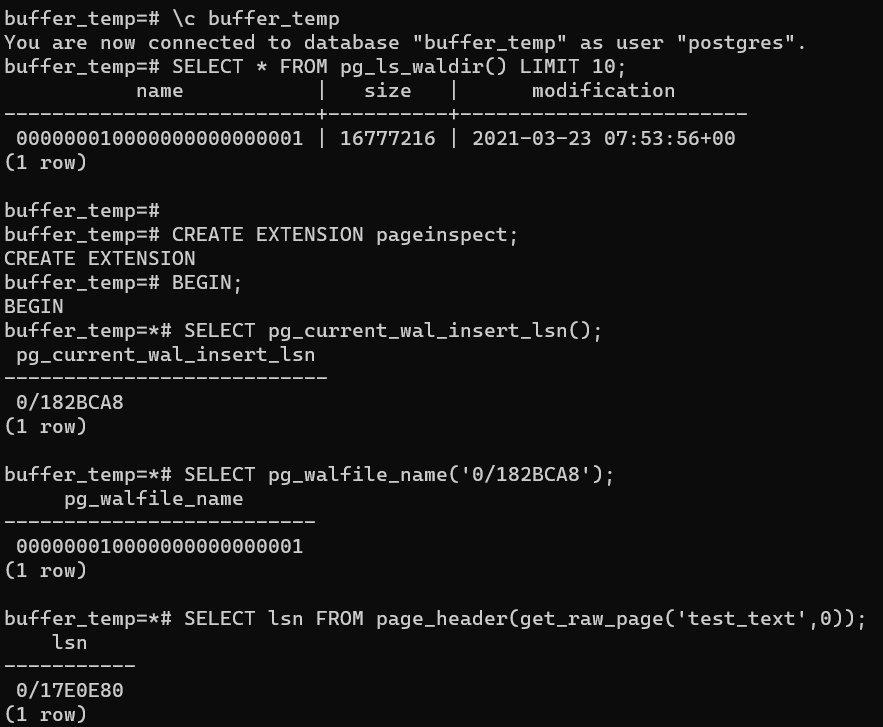
Подключимся к БД buffer_temp:
\c buffer_temp
Посмотрим на текущие WAL-файлы:
SELECT * FROM pg_ls_waldir() LIMIT 10;
Создадим расширение для просмотра содержимого страниц:
CREATE EXTENSION pageinspect;
Начнём транзакцию:
BEGIN;
Посмотрим текущую позиция LSN:
SELECT pg_current_wal_insert_lsn();
Посмотрим, какой у нас WAL file:
SELECT pg_walfile_name(‘0/182BCA8’);
Посмотрим последний номер LSN в 0 страницы таблицы test_text используя сырые данные функцией get_raw_page:
SELECT lsn FROM page_header(get_raw_page(‘test_text’,0));
Закоммитим транзакцию:
COMMIT;
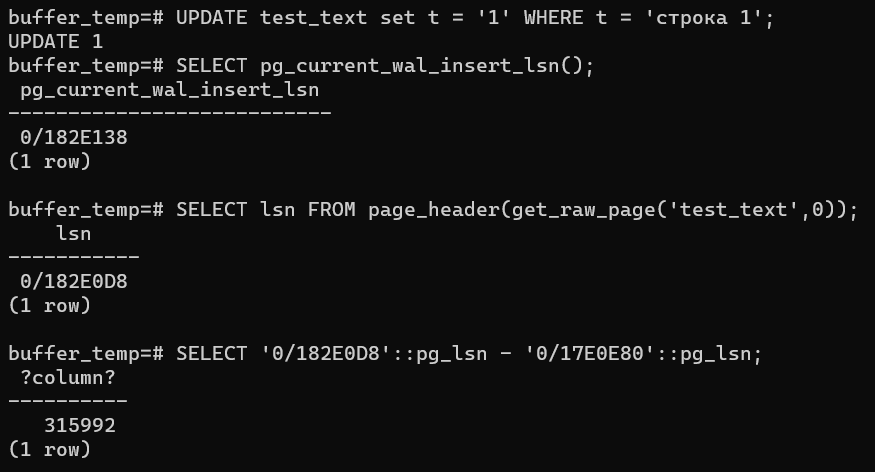
Обновим строку:
UPDATE test_text set t = ‘1’ WHERE t = ‘строка 1′;
Увидим, что когда текущий LSN изменился — у нас уже другая транзакция (подробнее о разных транзакциях) :
SELECT pg_current_wal_insert_lsn();
Так и изменился LSN в странице 0, где изменили данные:
SELECT lsn FROM page_header(get_raw_page(‘test_text’,0));
Посмотрим, сколько всего байт журнальных записей прошло с тех пор:
SELECT ‘0/182E0D8’::pg_lsn — ‘0/17E0E80’::pg_lsn;
Посмотрим на физический WAL-файл, что там произошло между этими значениями LSN:
/usr/lib/postgresql/15/bin/pg_waldump -p /var/lib/postgresql/15/main/pg_wal -s 0/17E0E80 -e 0/182E0D8 000000010000000000000001
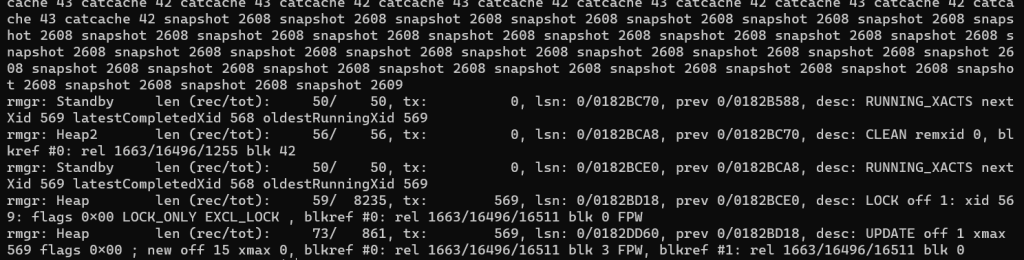
Здесь лишь хвост — так как больше 300 000 байт за это время успело попасть в файл. Таким образом, здесь увидим все SQL-команды и транзакции, которые проходили за это время.
Возникают интересные вопросы. В какой момент нужно сбрасывать на диск WAL-файлы? Что делать с грязными буферами? И нужно ли это вообще? Можно же с самого начала накатить все wal?
Есть несколько причин для периодического сброса изменений на диск:
- зачем хранить большой объём измененной информации в буфере?
- сколько займёт время восстановления, если произойдет сбой?
- сколько может изменённая страница лежать в буферном кэше?
Ответы на эти вопросы мы рассмотрим в следующих статьях.
Добавить комментарий