Статья основана на одиннадцатом видео из 30 тем курса SQL c 0 от Аристова Евгения. Ссылки на видео на платформах RUTUBE и VK видео.
Табличное пространство
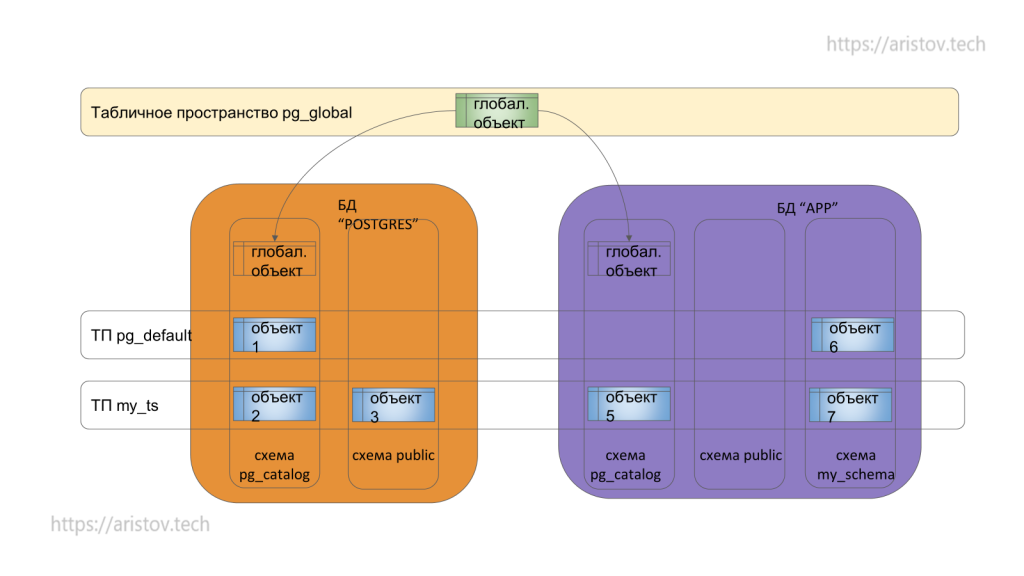
Все объекты баз данных хранятся в табличных пространствах. По умолчанию есть пространство pg_default, которое находится в том же каталоге, что и кластер PostgreSQL. Табличные пространства можно создавать и самостоятельно (монтировать диски, сетевые устройства и т.д.), размещать в них объекты.
Объекты — всё, что материально хранится: таблицы, индексы и т.д.
В разные базы данных можно монтировать одно и то же табличное пространство, то есть хранить объекты в одном табличном пространстве.
Также существуют глобальные объекты, которые находятся в единственном каталоге pg_catalog (например, pg_class) и относятся ко всем базам данных в кластере.
Рассмотрим хранение объектов.
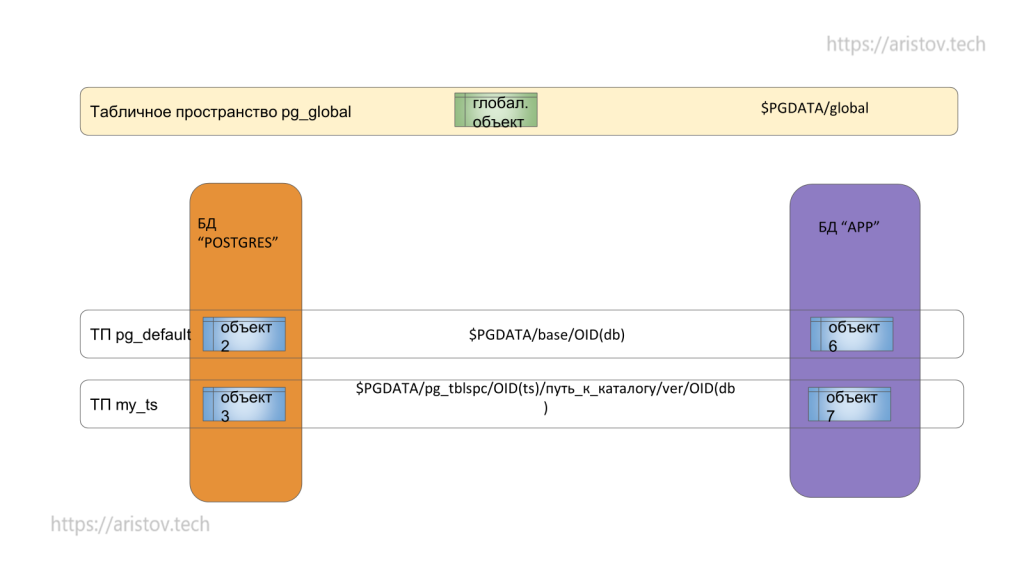
В классическом pg_default есть каталог с PostgreSQL, каталог base, идентификатор базы данных (глобальный).
В каталог pg_tblspc можно смонтировать любой другой каталог — там будет ссылка на физический диск. Это нужно для распараллеливания нагрузки.
Важно, что один объект может быть расположен только в одном месте (табличном пространстве). При этом перенос возможен, но это физический перенос файла (понадобится эксклюзивная блокировка).
Варианты оптимизации ТП:
- Отдельные объекты (БД, таблицы) разместить в разных ТП, расположенных на разных дисках, дисковых массивах, таким образом распараллелить нагрузку
- Смонтировать часть оперативной памяти часть как файловую систему, создать ТП и держать там, например, материализованные представления, временные таблицы, индексы — то, что не страшно потерять при перезагрузке сервера. Хранить таким образом оригинальные данные нельзя
- Установить локально на сервер ssd диск под такие же некритичные данные
Устройство PostgreSQL
Рассмотрим устройство с логической точки зрения.
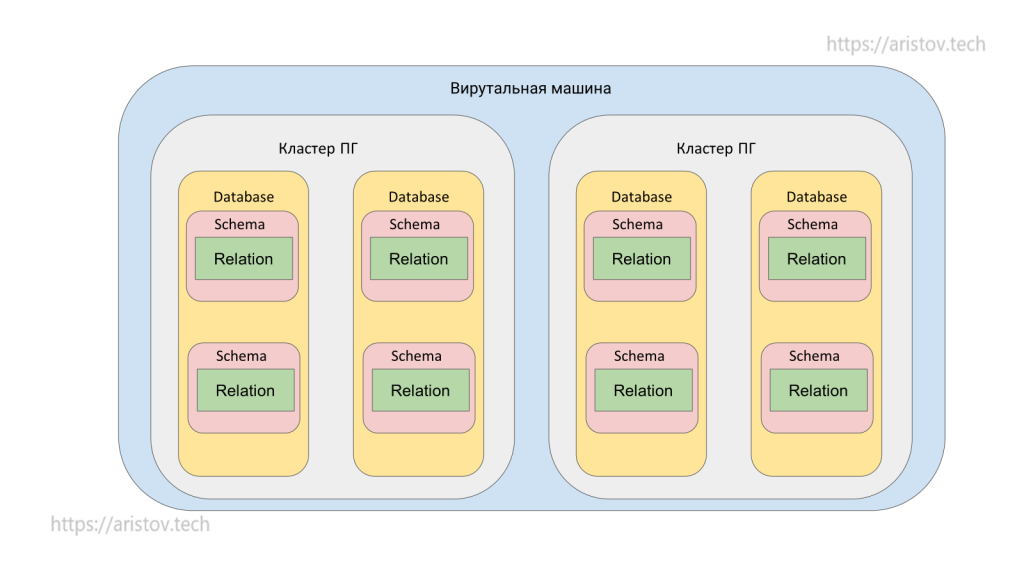
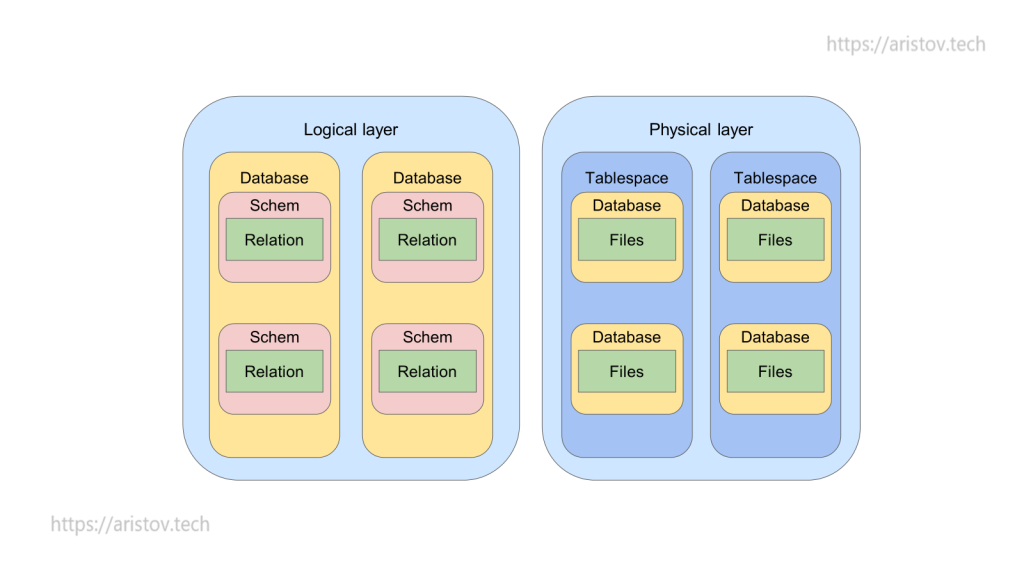
На виртуальной машине можно развернуть несколько кластеров PostgreSQL (кластер — отдельно запущенный инстанс на каком-то порту). Внутри каждого кластера может быть несколько БД, а внутри каждой БД несколько схем. В каждой схеме свои Relation (таблицы, индексы и другие объекты). Количество возможных кластеров зависит от ресурсов. БД, схемы, Relation и табличные пространства относятся к DDL — data definition language — язык, описывающий схему хранения данных.
Database
Относится к DDL.
Является контейнером самого верхнего уровня в любом кластере. Нельзя создать объект, не принадлежащий какой-то базе данных.
По умолчанию в любом кластере есть как минимум 3 БД:
- postgresql (по умолчанию работаем с ней)
- template0
- template1
Присутствует и на логическом, и на физическом уровне. То есть каждой базе данных соответствует каталог.
postgres
- Первая база данных для регулярной работы. Имеет такое имя, так как автоматически подключается по имени пользователя.
- Создается по умолчанию
- Желательно не использовать (создавать свои БД для работы), но и не удалять — иногда она нужна для различных утилит
template0
- Предназначен для восстановления из резервной копии
- По умолчанию нет прав на connect (можно изменить, но категорически не рекомендуется)
- Лучше всего не создавать в ней никаких объектов
template1
- Используется как шаблон для создания новых баз данных
- В нем имеет смысл делать некие действия, которые не хочется делать каждый раз при создании новых баз данных. Например, create extension или create schema
- Лучше не создавать объектов, так как для других
- пользователей это будет неочевидно
- Лучше сделать свой шаблон для создания других БД (template2, template3 и т.д.)
Создание базы данных
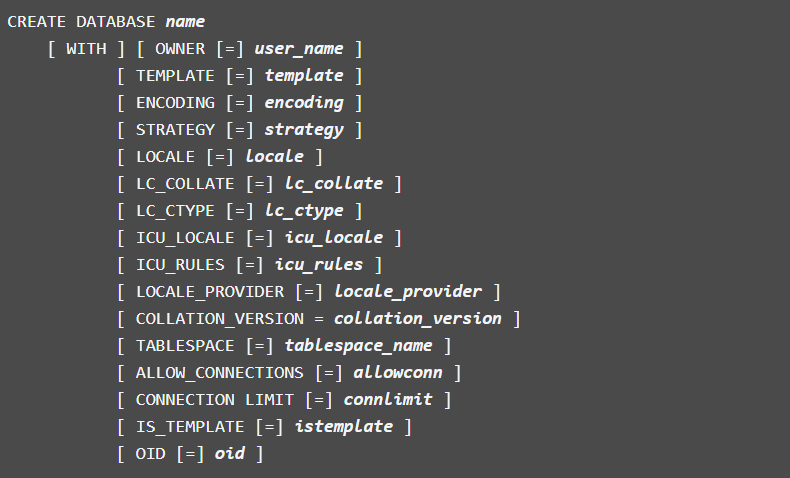
В TEMPLATE можно выбрать шаблон из существующих. С помощью IS_TEMPLATE можно сделать свою базу данных шаблоном. Есть возможность запретить подключения ALLOW_CONNECTIONS (используется в шаблонах).
Базу данных нельзя создать в транзакции. При подключении к другой базе данных текущая транзакция также прерывается. В связи с этим работа с базой данных (изменение, создание) требует аккуратности.
CREATE DATABASE aristov_tech - создание БД Scheme
Схема — контейнер второго уровня. По умолчанию используется схема PUBLIC.
Схема — логическое разделение БД на сегменты.
В разных схемах можно создавать объекты с одинаковыми именами.
Создание схемы
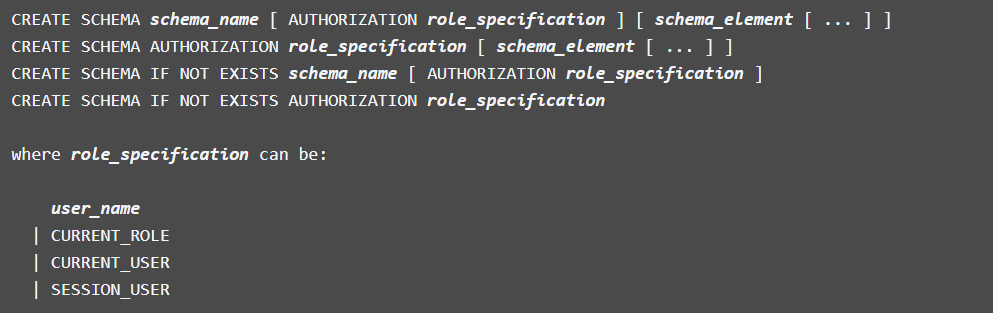
CREATE SCHEMA eugene;Если схема не указано явно, то объект ищется во всех схемах.
Для отображения таблиц схемы:
\dt eugene.* (указано имя схемы - eugene)Table
Создание объекта внутри конкретной схемы:
CREATE TABLE eugene.test (
i int
);
\d+ eugene.test

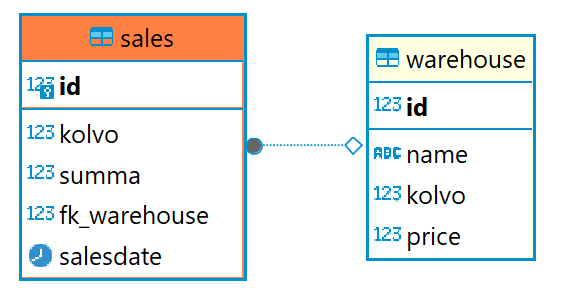
Пример создания таблицы warehouse:
DROP TABLE IF EXISTS warehouse CASCADE;
CREATE TABLE warehouse (
id serial UNIQUE,
name text NOT NULL DEFAULT '',
kolvo int NOT NULL DEFAULT 0,
price decimal NOT NULL DEFAULT 0.0
);
Сначала удаляем таблицу, но только если она существует. С помощью CASCADE удаляются также все зависящие таблицы. Рекомендуется использовать очень аккуратно, так как удаляться все зависящие таблицы, что может повлечь потерю значительного количества связанных данных. Также нельзя удалять и заново создавать объекты при необходимости отредактировать что-либо (например, изменить тип поля), так как данные при этом не сохранятся. Нужно использовать команду ALTER.
- id — последовательность, уникальное поле
- name — текстовое, не может быть NULL, по умолчанию пустое
- kolvo — целое, не может быть NULL, по умолчанию 0
- price — вещественное, не может быть NULL, по умолчанию 0.0
Default применяется, когда пользователь не задал значение при добавлении записи
Рекомендуется все поля делать NOT NULL, так как с NULL полем сложнее работать (NULL != NULL). Для работы с NULL используется is NULL. Пустая строка — » — это отсутствие символа, а NULL — несуществующее значение. При этом »=» (пустая строка равна пустой строке).
Создание таблицы sales:
DROP TABLE IF EXISTS sales;
CREATE TABLE sales(
id serial PRIMARY KEY,
kolvo int NOT NULL,
summa numeric NOT NULL DEFAULT 0.0,
fk_warehouse int references warehouse(id) ON DELETE CASCADE,
salesDate date default current_date
);- id — последовательность, уникальное поле
- kolvo — целое, не может быть NULL
- summa — вещественное, не может быть NULL, по умолчанию 0.0
- fk_warehouse — внешний ключ на таблицу warehouse
- salesDate — дата, по умолчанию текущая дата
Вставим записи в разные таблицы и просмотрим результат:
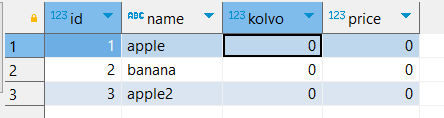

Проверим, что будет, если попробовать вставить запись с повторным id:
INSERT INTO warehouse(id, name) VALUES
(1, 'soap');
Сопоставим продажи с товарами:
Обратите внимание, что при создании таблиц не была указана схема, поэтому они были созданы в PUBLIC. Рекомендовано создавать своих схемы данных, использовать public считается неправильным.
Relation
Виды RELATION в БД
r = ordinary table
Кроме простых таблиц, также существуют и другие отношения:
i = index,
S = sequence,
v = view,
m = materialized view,
c = composite type,
t = TOAST table,
f = foreign table
Каждому Relation соответствует отдельный файл на диске.
Просмотр конфигурационных файлов (подробнее в статье):
show hba_file;
show config_file;
show data_directory;Создадим объект и просмотрим его расположение:
CREATE TABLE test5(
i int
);
SELECT pg_relation_filepath('test5');Посмотрим пример создания своего табличного пространства.
Создадим своё табличное пространство в домашнем каталоге пользователя postgres каталоге:
sudo su postgres
cd ~
mkdir temp_tblspce
CREATE TABLESPACE ts location '/var/lib/postgresql/temp_tblspce';Напоминаю, что табличное пространство можно смонтировать на любо диск, распараллелив таким образом работу.
Перемещение (физическое) объекта в другое ТП:
CREATE TABLE test2 (
i int
)
TABLESPACE pg_default;Лучше заранее грамотно проектировать базу, так как перенос занимает время, требует ресурсов и эксклюзивного доступа.
Просмотр физического размера базы:
SELECT pg_database_size('app');Для упрощения восприятия можно вывести число в отформатированном виде:
SELECT pg_size_pretty(pg_database_size('app'));
Просмотр размера индексов:
SELECT pg_size_pretty(pg_indexes_size('test2'));Просмотр default табличного пространства:
SELECT count(*)
FROM pg_class
WHERE reltablespace = 0;Просмотр схем по умолчанию (в данной переменной указана очередность поиска объектов):
SHOW search_path;Рекомендуется всегда указывать схему, в которой работаете, чтобы не было разночтений
Constraint или ограничения
Рекомендуется всегда использовать NOT NULL
UNIQUE внутри себя содержит уникальный индекс
PRIMARY KEY требует внимательной работы с каскадами
CHECK — проверки. Например, цена больше нуля. Рекомендуется отдавать на бэкенд.
Подробнее об ограничениях здесь.
Именование объектов
Необходимо давать интуитивно понятные имена объектам
PostgreSQL автоматически текст приводит к нижнему регистру.
Два популярных варианта именования:
- camelCase -> camelcase
- snake_case -> snake_case
Можно, но крайне не рекомендуется использовать кавычки (сохраняется регистр, можно использовать русский и пробелы) — тогда имя будет сохранено как в оригинале: «camelCase» -> «camelCase» и всегда придётся использовать кавычки и то же написание.
DEFAULT vs IDENTITY
Классический SERIAL -> INT NOT NULL DEFAULT(nextval(‘test_i_seq’))
CREATE TABLE color (
color_id SERIAL,
color_name VARCHAR NOT NULL
);
Начиная с 10 версии рекомендуется использовать IDENTITY
CREATE TABLE color (
color_id INT GENERATED ALWAYS AS IDENTITY,
color_name VARCHAR NOT NULL
);
Отличие заключается в том, что IDENTITY можно использовать для единственной таблицы, а SERIAL — как сквозную нумерацию в разных таблицах.
Оба способа основаны на SEQUENCE.
Презентация и исходники к статье доступны на github.
12 из 30 тем будет скоро доступна. Если вы хотите быстрее получить доступ – присоединяйтесь к онлайн группе, ссылка доступна в описании курса.
Добавить комментарий