Запись занятия доступна в ютуб версии, рутуб версии и VK Видео.
Материалы к статье доступны на гитхабе.
В статье вспомним работу с памятью и процессами, рассмотрим проблематику долгих транзакций, рассмотрим разницу поведения подключений при различных статусах idle VS idle in transaction, изучим подводные камни этих вариантов и проведём практические исследования.
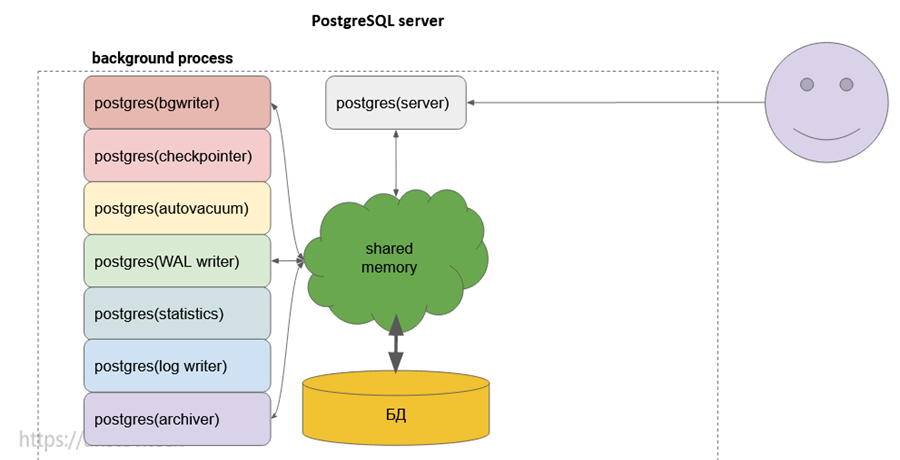
Вспомним, как стартует PostgreSQL, а именно, как происходит порождение процессов.
Первый и основной процесс PostgreSQL – postgres server process:
- называется postgres
- запускается при старте сервиса
- порождает все остальные процессы, используя клон процесса – fork
- создаёт shared memory
- слушает TCP и Unix socket
- запускаются основным процессом PostgreSQL при старте сервиса (fork)
- выделенная роль у каждого процесса (будем рассматривать тонкости в дальнейших главах):
- logger – запись сообщений в лог-файл
- checkpointer – запись грязных страниц из buffer cache на диск при наступлении checkpoint
- bgwriter – проактивная запись грязных страниц из buffer cache на диск
- walwriter – запись WAL buffer в WAL file
- autovacuum – демон, отвечающий за периодический запуск vacuum
- archiver – архивация и репликация WAL
- statscollector – сбор статистики использования по сессиям и таблицам
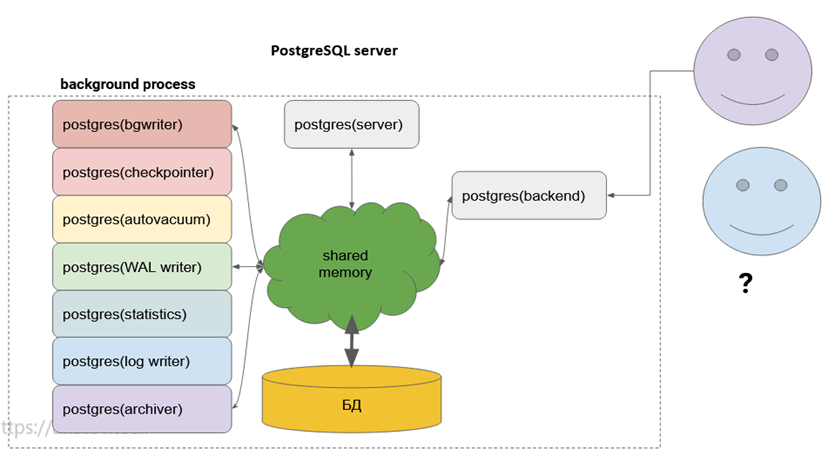
Остальные порождаемые им процессы это backend processes. Каждый процесс:
- сейчас тоже называется postgres
- запускается основным процессом PostgreSQL
- обслуживает клиентскую сессию
- работает, пока сессия активна
Максимальное количество определяется параметром max_connections (по умолчанию 100).
После того, как процессы клонированы, они начинают выполнять каждый свою задачу. Далее создаётся общая разделяемая память, которую эти процессы совместно используют, через неё идёт общение с файлами на дисках.
Представим, что приходит клиент (psql, java и так далее) пытается подключиться к PostgreSQL:
Происходит fork процесса postgres, и дальше этот процесс postgres backend уже напрямую сам общается с shared memory. Далее к нам приходит следующий клиент:
Снова клон процесса. На каждого пользователя свой бэкенд-процесс:
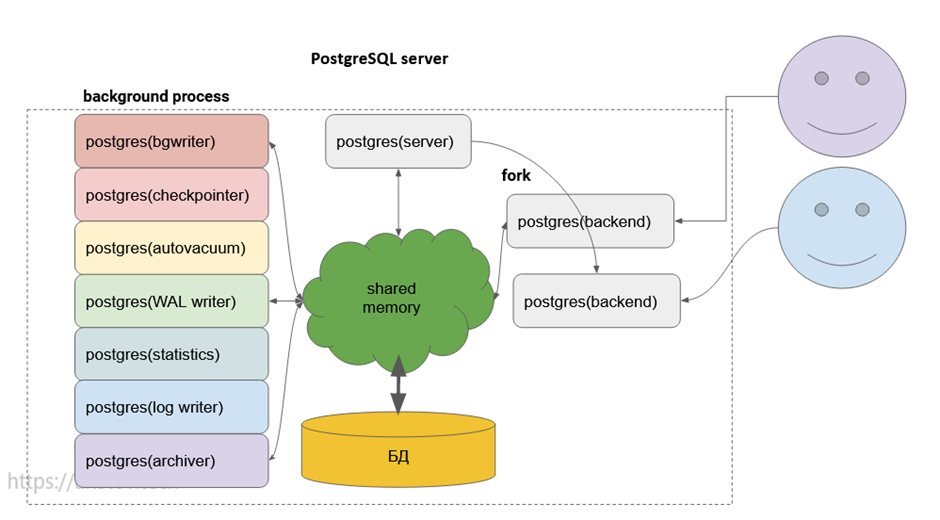
Клон процесса работает довольно быстро, но, всё же, это миллисекунды. Кроме этого, выделяется work_mem и temp_buffers на каждый процесс, что тоже несёт свои накладные расходы.
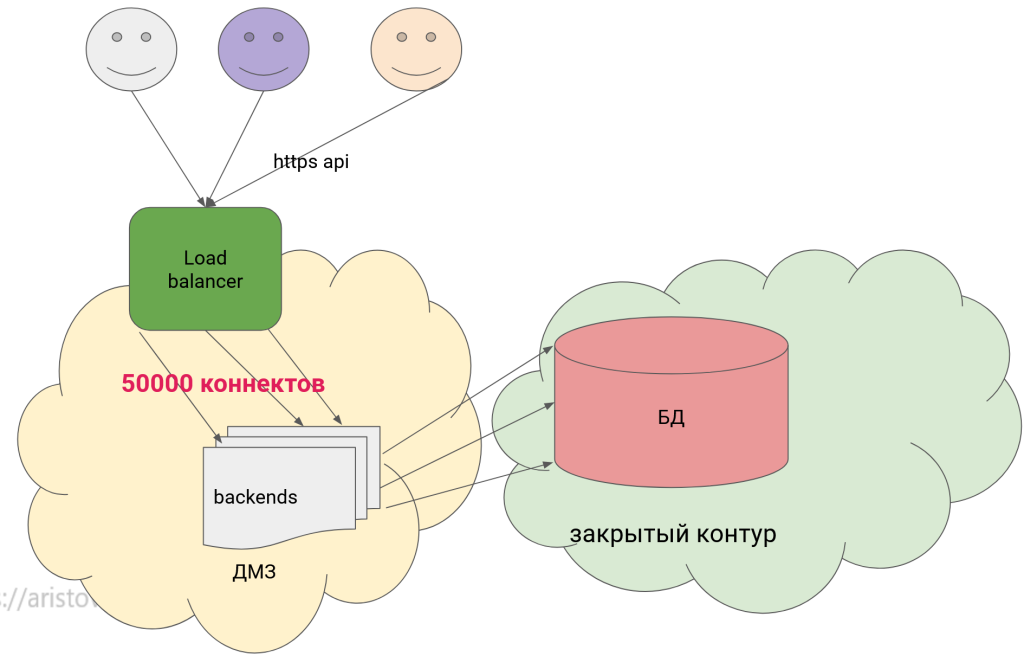
Получается, было бы оптимально не создавать клон процесса и выделять память под каждый запрос, а использовать специальную утилиту, которая как раз и будет держать постоянно висящие подключения и обслуживать посторонние сессии. Такая утилита называется pool connector (pooler или пулер). Также она может нам помогать терминировать SSL-трафик после демилитаризованной зоны (DMZ).
Что ещё важно в такой схеме подключений – использование балансировщика нагрузки, чтобы равномерно распределить нагрузку на бэкенд-процессы. Более подробно разбирается на моём курсе по оптимизации.
Кроме того выделяется память для каждой сессии:
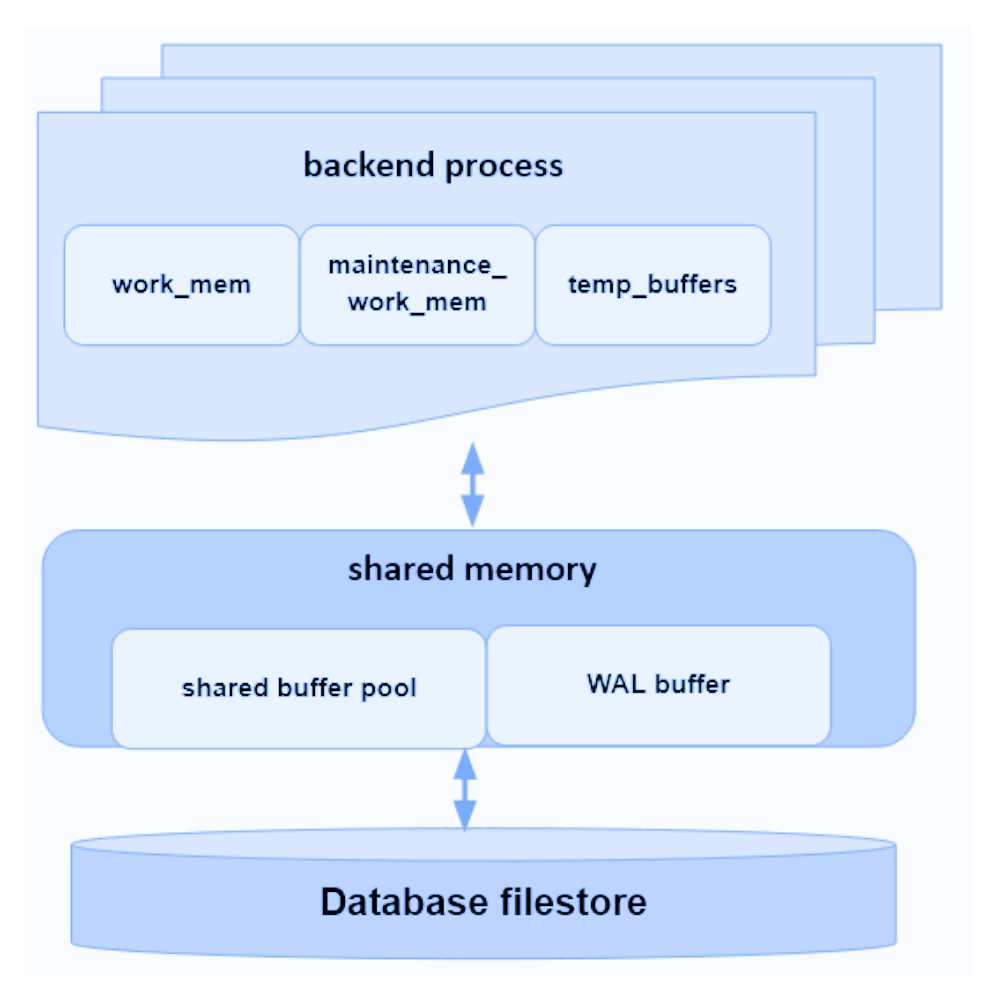
Эта память принадлежит КАЖДОМУ backend процессу:
- work_mem (4 MB) — используется на этапе выполнения запроса для сортировок строк, например ORDER BY и DISTINCT — выделяться может неоднократно!
- maintenance_work_mem (64MB) — используется служебными операциями типа VACUUM и REINDEX. Выделяется только при использовании команд обслуживания в сессии.
- temp_buffers (8 MB) используется на этапе выполнения для хранения временных таблиц.
При превышении выделяемой памяти во время работы будет использоваться temp tablespace на диске, что довольно медленно.
Важно выделить больше памяти, чем устанавливается по умолчанию! Например, используя калькулятор ресурсов.
Также важно иметь в виду, что на большие сложные запросы можно выделить work_mem прямо на сессию!
Теперь можно рассмотреть проблематику выделения множества коннектов. Схематически можно изобразить:
А именно построить графики производительности PostgreSQL в зависимости от количества коннектов:
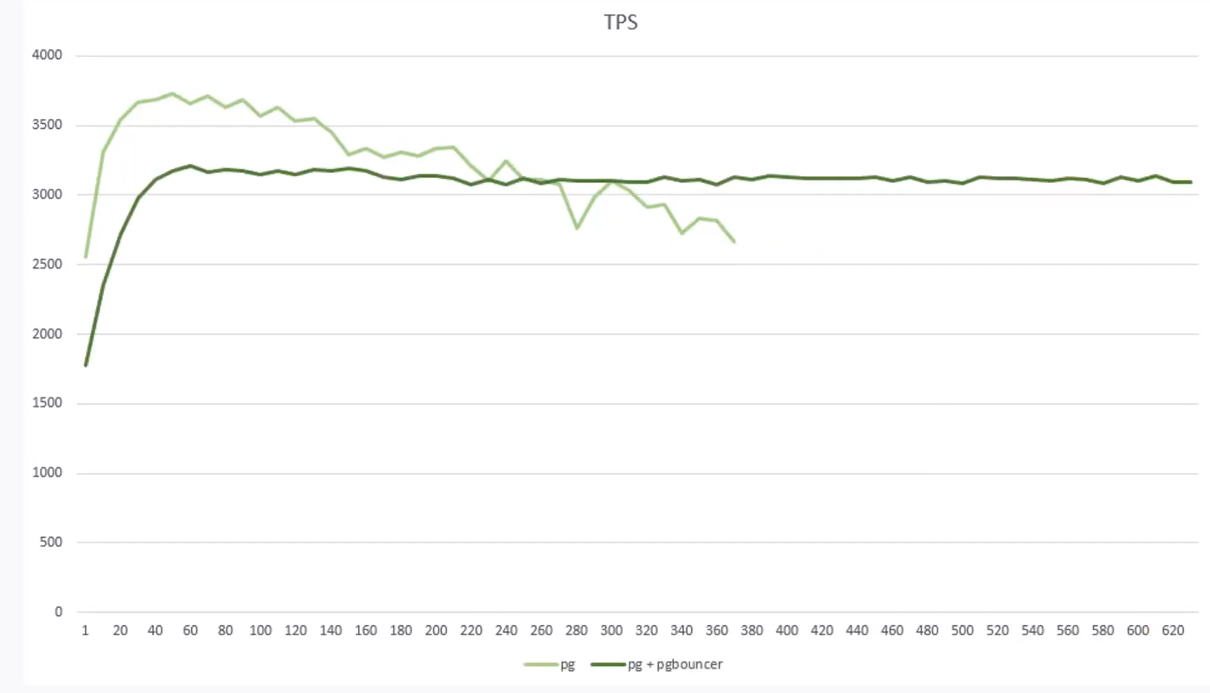
Видим интересную картину, что при использовании pgbouncer мы немного жертвуем производительностью, но при этом на большом (более 500) количестве коннектов у нас нет такого катастрофического падения производительности.
Итого какие мы имеет проблемы?
- коннект в PostgreSQL очень дорог
- без пулконнектора (pgbouncer, pgpool-II,pgagroal,odyssey) жить тяжело — но необходимо учитывать overhead и особенности каждого пулера
- возникает идея — если держать постоянные коннекты (не тратить время на fork процессов)?
Сегодня у нас будет стенд из 2 виртуальных серверов в облаке Google (вы можете использовать любые другие ВМ или докер), один с PostgreSQL 16, второй для скриптов на python для тестирования массовых подключений и проигрыша сценариев (скрипты выложены на github).
Внутри мы загрузим мою БД с тайскими перевозками:
sudo su postgres
cd ~ && wget https://storage.googleapis.com/thaibus/thai_small.tar.gz && tar -xf thai_small.tar.gz && psql < thai.sqlОткроем доступ по внутренней VPC (не через интернет!):
sudo -u postgres psql -c "ALTER USER postgres WITH PASSWORD 'admin123#';";
echo "listen_addresses = '10.128.15.196, 127.0.0.1'" | sudo tee -a /etc/postgresql/16/main/postgresql.conf
echo "host all all 10.0.0.0/8 scram-sha-256" | sudo tee -a /etc/postgresql/16/main/pg_hba.conf
sudo pg_ctlcluster 16 main restart
Подключимся из второго терминала и посмотрим на список процессов используя команды:psql -U postgres -h localhost -p 5432 -d postgres -WSELECT * from pg_stat_activity;
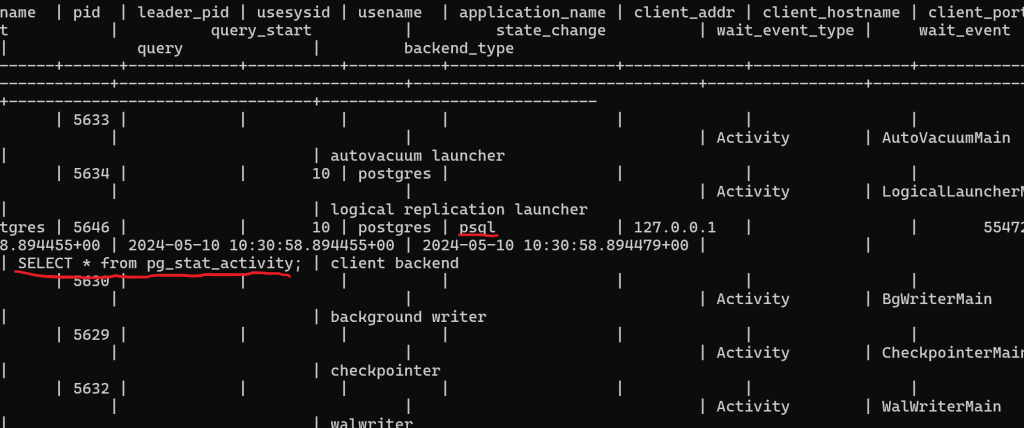
Увидим кроме обслуживающих процессов и свой с текущим запросов из psql. Если мы откроем еще один коннект из psql и повторим запрос, мы как раз и увидим ситуацию с idle:

Наши ситуации для исследований на сегодня:
- idle — есть коннект, транзакций нет, т.е. мы не делаем ничего
- idle in transaction — есть и транзакция, но висит и ждёт чего-то (блокировки) /кого-то (вручную держим открытую транзакцию).
При этом idle in transaction:
- держит блокировки
- посмотреть можно через представление pg_locks: select * from pg_locks
- память занята под work_mem + temp_buffers
Создание транзакций внутри коннекта тоже не бесплатно.
Существует аффект при ручном создании (BEGIN;) транзакций (не AUTOCOMMIT) — падение производительности до 2х раз на коротких SELECT.
Решение — создание долгих транзакций, а внутри них уже не зависящие друг от друга запросы (oracle way).
Проблему решает включенный AUTOCOMMIT и виртуальные транзакции (подробные исследования на курсе, а также разница между COMMIT vs ROLLBACK).
Казалось, бы что может пойти не так при ситуации idle in transaction?
Database has long running idle in transaction connection — Amazon Aurora


https://dba.stackexchange.com/a/77587/271578

Даже Павел Лузанов из PostgresPro:

Давайте разбираться.
Гипотезы для проверки:
- затруднение обслуживающих процессов (vacuum)
- при наличии только операций чтения
- при наличии пишущих транзакций
- а если повысить уровень изоляции транзакций?
- что с таблицей блокировок и pg_stat_activity?
- повышенное потребление памяти?
- снижение производительности?
- освобождается ли work_mem после завершения запроса? транзакции?
Гипотеза 1
Часть 1
Начнем с проверки гипотезы «затруднение обслуживающих процессов (vacuum) при наличии только операций чтения».
Сгенерируем в первом терминале миллион записей:
DROP TABLE IF EXISTS records;
CREATE TABLE records(id serial, filler text);
\timing
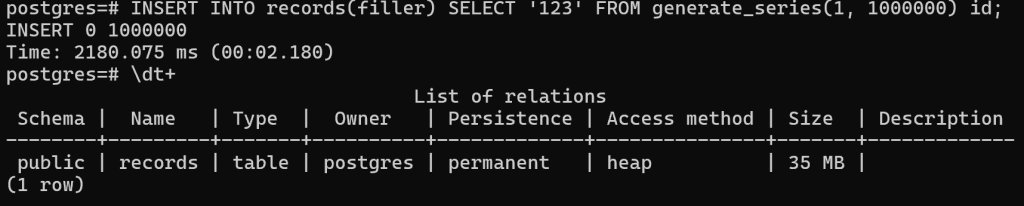
INSERT INTO records(filler) SELECT '123' FROM generate_series(1, 1000000) id;
\dt+
Теперь переходим к сути эксперимента — в одной транзакции читаем эти строки и не закрываем транзакцию, в параллельной пытаемся выполнить VACUUM:
BEGIN;
SELECT count(*) FROM records;
—2 terminal
VACUUM records;
VACUUM FULL records;
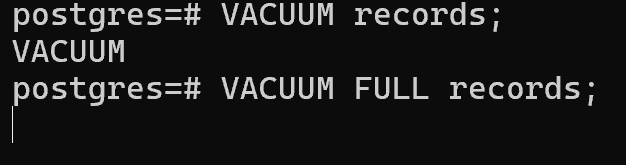
Ожидаемо VACUUM успешно выполнился, а вот требующий эксклюзивной блокировки VACUUM FULL нет, он висит в ожидании полного доступа. Как только мы завершим транзакцию в первом сеансе, он произведет полную очистку.
Часть 2
Следующий эксперимент — пишущая нагрузка, а более точно — удаление строк:
ROLLBACK;
BEGIN;
DELETE FROM records WHERE id < 100000;
SELECT relname, n_live_tup, n_dead_tup, trunc(100*n_dead_tup/(n_live_tup+1))::float "ratio%", last_autovacuum FROM pg_stat_user_tables WHERE relname = 'records';
SELECT txid_current();
Во 2 терминале пытаемся почистить мертвые строки, удалённые в первой транзакции:VACUUM ANALYZE records;
Ошибок нет, но посмотрим, очистится ли мертвая строка в первом терминале:SELECT relname, n_live_tup, n_dead_tup, trunc(100*n_dead_tup/(n_live_tup+1))::float "ratio%", last_autovacuum FROM pg_stat_user_tables WHERE relname = 'records';

Мы не видим изменений. Это связано с тем, что физически запись мы не зафиксировали и параллельно к ней доступ VACUUM не имеет.
Попробуем прямо внутри первой транзакции физически почистить запись:
VACUUM ANALYZE records;
И получим вот такую ошибкуERROR: VACUUM cannot run inside a transaction block
VACUUM НЕ работает внутри транзакции.
Теперь остается только вариант ROLLBACK, так как у нас произошла отмена транзакции.
ROLLBACK;
Часть 3
В следующем эксперименте сделаем выборку в первой сессии, а в другой попытаемся удалить строки:
BEGIN;
SELECT count(*) FROM records;
—2 terminal
DELETE FROM records WHERE id < 100000;
VACUUM ANALYZE records;
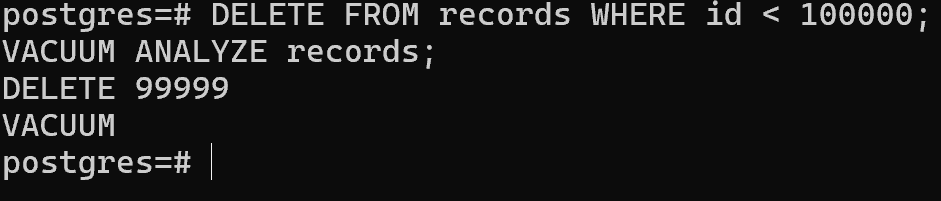
Проблем не возникло, так как уровень изоляции транзакций по умолчанию READ COMMITTED.
Остальные гипотезы
Перейдем к более сложным экспериментам — с массовой нагрузкой коннектами.
Скрипты подготовки ВМ с python выложены на github, как и доступен репозиторий с исходными скриптами.
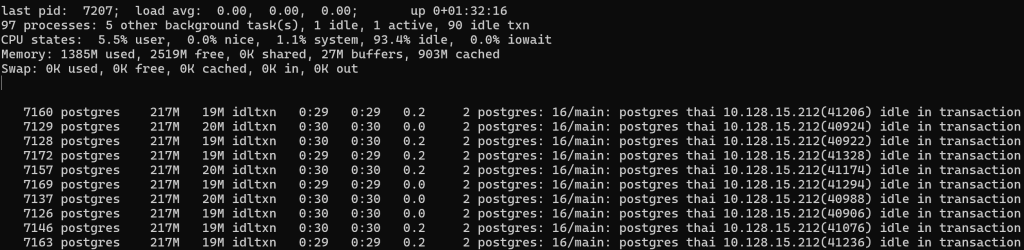
Запустим в третьем терминале 10 коннектов по умолчанию, при этом кроме установки соединения они не будут ничего делать и посмотрим нагрузку в pg_top:
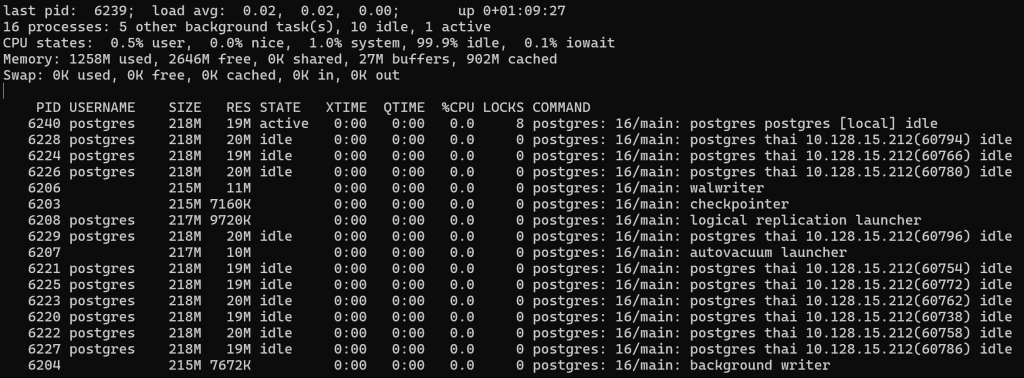
Процессор практически не нагружен, на переключение контекстов практически не тратится времени, памяти тоже потратили ~20МБ.
Усложним задачу и нагрузим в 100 коннектов:
python3 pg_tester.py -c 100
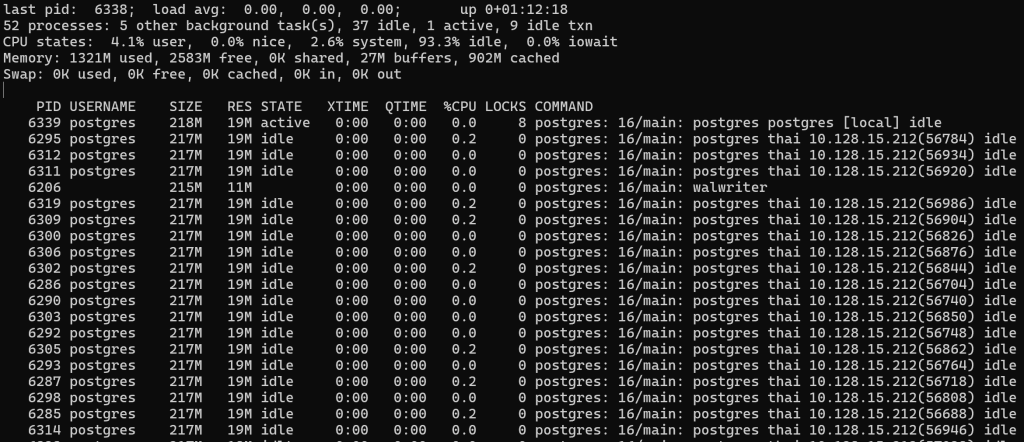
В целом, тоже справляемся на отлично, но когда все коннекты окажутся заняты (а у нас всего их 100 по умолчанию), нас выбросит:

Уменьшим количество коннектов до 90 и запустим в режиме idle in connection — после установления соединения еще и откроем транзакцию (BEGIN):
python3 pg_tester.py -c 90 -T IdleInTransaction
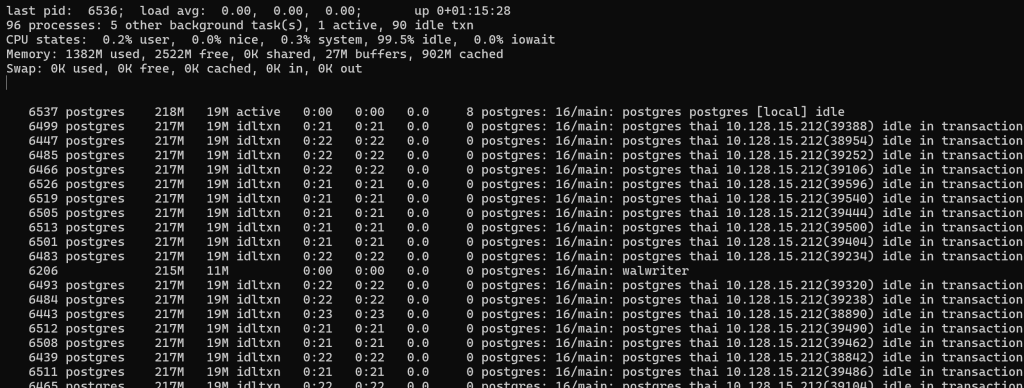
И видим, что просто висящие и ничего не ждущие процессы практически не аффектят на систему.
Запустим в следующем режиме — каждую секунду будет вызываться запрос SELECT 1 — для проверки живо ли соединение. Лично моё мнение — это антипаттерн и такие запросы хоть немного, но снижают производительность. А когда таких бэкендов тысячи и больше? Для решения этой задачи лучше использовать паттерн curcuit breaker.
python3 pg_tester.py -c 90 -T SelectOne
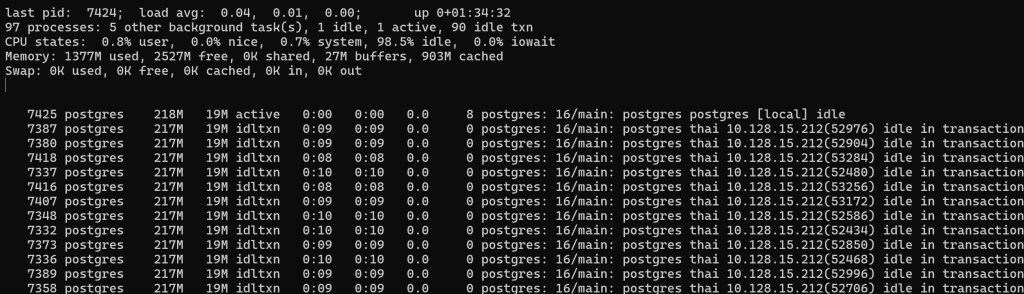
Видим, что часть процессов уже начинает немного потреблять процессор.
Посмотрим на таблицу с блокировками:
SELECT count(*) from pg_locks;
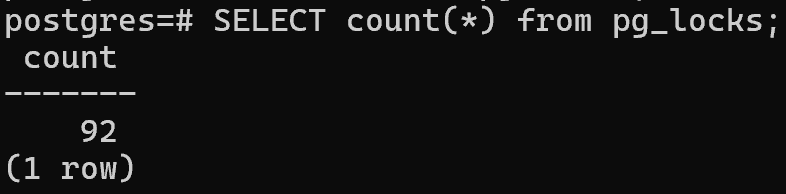
И видим, что ситуация уже потихоньку начинает ухудшаться, системные таблицы заполняются всё больше. А это мы еще в реальную БД не ходили и объекты не запрашивали — на каждую таблицу получим 1+ блокировку и т.д.
В последнем на сегодня эксперименте, вместо SELECT 1 сделаем случайную выборку строки из тайских перевозок. Модифицируем файл и заменим строки:
nano clients/Client.py
import random
select * from book.bus where id = " + str(random.randint(1, 5000000)) + ";"
Посмотрим нагрузку и представление pg_locks:
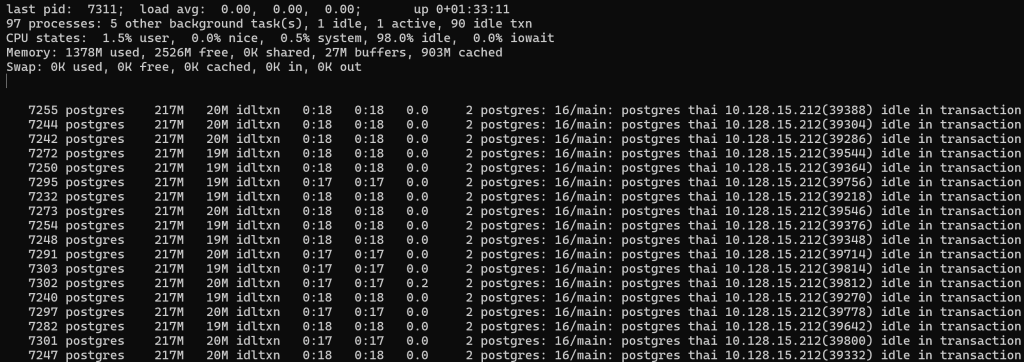
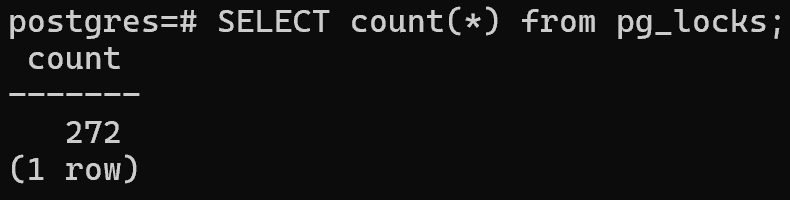
И это нагрузка всего 90 простейших запросов по индексу..
Сделаем по 10 запросов в секунду — уменьшим время сна:
900 запросов уже повеселее.
Пока временных ресурсов на проведение всех запланированных экспериментов не хватило, некоторые выводы уже можно сделать, но вы можете дообогатить скрипты и проверить гипотезы сами.
Что еще можно проверить:
- освобождается ли work_mem после завершения запроса?
- транзакции?
- на тяжелом запросе и анализе выделения памяти?
Если кому интересно, можете провести исследование вышеперечисленных экспериментов и оформить на гитхабе — оставлю ваше авторство на ваш эксперимент и в подарок моя книга или скидка на курс, свяжитесь со мной через сайт или телеграм и обсудим условия.
Что еще стоит учитывать:
VACUUM всё таки блокируется при хранении долгого снимка базы данных. Снимок — это структура данных, которая определяет, какие другие транзакции видны определенной транзакции. Снимки остаются открытыми до тех пор:
- пока выполняется SQL-оператор (поэтому длительно выполняющийся запрос может заблокировать выполнение VACUUM)
- пока открыт курсор
- на уровне изоляции REPEATABLE READ или SERIALIZABLE, в течение всего времени транзакции
Не забываем про проблему Transaction ID wraparound — заморозка и всё с этим связанное.
Параметр old_snapshot_threshold = -1 — НЕ МЕНЯЕМ ни к коем случае!
В теории должен БЫЛ решить проблему со старыми снепшотами при долгих транзакциях, но все как обычно.
Проблему признали, но так никто и не пофиксил (обещают в 17 версии)
Исходный код с ошибочной долгой обработкой, кто любит покопаться.
Пример из жизни: 100+ ядер и долгие транзакции — до 5 раз падение производительности
В завершение подведу итоги:
Вопреки мнению большинства экспертов долгие транзакции могут сэкономить время на создание транзакций и при этом не мешать обслуживающим процессам, но:
- выделение постоянной памяти (work_mem + temp_buffers)
- разросшаяся таблица pg_stat_activity + pg_locks
- работает для уровня изоляции read committed
- периодически необходимо пересоздавать транзакцию
- при обрыве соединения, если были не только читающие запросы — можем потерять изменения — всё таки лучше пишущие транзакции не делать длинными
- плюс будут мешать другим транзакциям
- плюс необходимо учитывать области видимости незавершенных транзакций!
Это всё необходимо учитывать, если вы решили пойти по пути долгих транзакций!!
А есть ли плюсы, кроме эфемерной экономии на создании транзакции?
Моя рекомендация — объединять в транзакции логически зависимые апдейты, а селекты доверить автокоммиту и виртуальным транзакциям.
Добавить комментарий