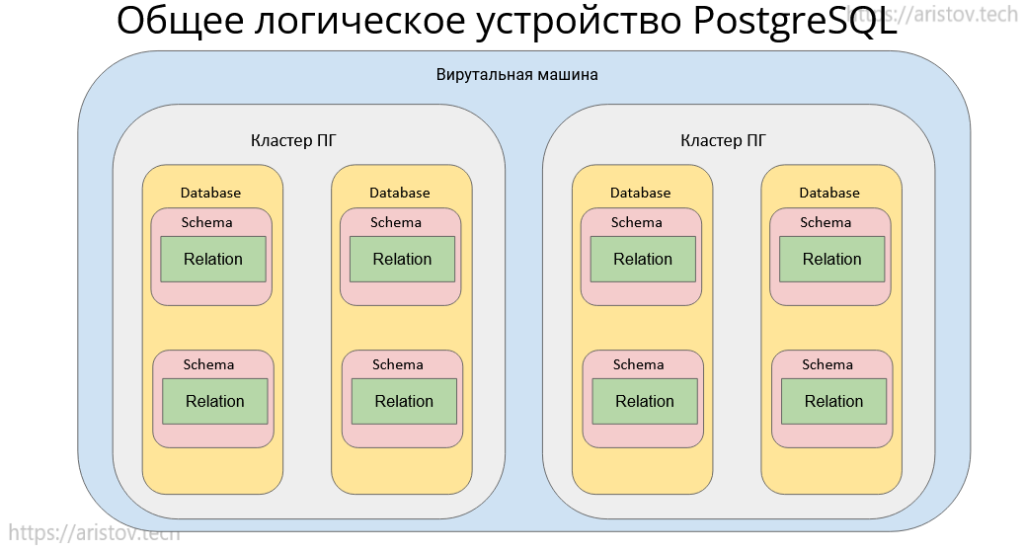
Начнем мы с контейнера верхнего уровня — виртуальной машины (ВМ). Внутри ВМ могут быть установлены разные версии PostgreSQL и на каждой версии может быть развернут 1 или более кластеров PostgreSQL. Я не ошибся — 1 инстанс СУБД PostgreSQL называется кластером в их терминологии.
Далее внутри инстанса у нас существуют 3 базы данных по умолчанию:
postgres — используется:
● первая база данных для регулярной работы
● создаётся по умолчанию
● хорошая практика — также не использовать
● но и не удалять — иногда нужна для различных утилит
template0 — используется:
● для восстановления из резервной копии
● по умолчанию даже нет прав на connect
● не рекомендовано вносить изменения — лучше всего не создавать в ней никаких объектов
template1 — используется:
● как шаблон для создания новых баз данных
● в нём имеет смысл делать некие действия, которые не хочется делать каждый раз при создании новых баз данных — создать хранимые функции/процедуры, создать справочники, включить расширения и т.п.
Конечно мы можем и сами создавать как шаблоны, так и базы данных.
Далее внутри БД у нас есть еще логическое разделение на схемы данных — schema. По умолчанию используется схема public — не самый рекомендованный вариант. Лучше создавать свою именованную схему. По умолчанию объекты (таблицы и др) в схеме видят другие объекты только этой же схемы, что очень удобно для логического разбиения на области видимости.
Внутри схемы уже непосредственно создаются отношения (relation). Одной схеме может принадлежать от 0 и более отношений. Соответственно, каждое отношение принадлежит своей схеме и своей базе данных.
Давайте посмотрим, какие виды отношений (relkind) у нас есть:
● r = ordinary table — обычная таблица — используется для хранения данных
● i = index — индекс — ускоряем поиск данных
● S = sequence — последовательность — генерируем автоматически нумерацию строк
● v = view — представление — грубо говоря сохраненный заранее вид запроса к таблицам
● m = materialized view — материализованное представление — кроме сохраненного текста запроса, также хранит и сами данные
● c = composite type — композитный тип — раширяем стандартный набор типов данных
● t = TOAST table — для хранения слишком больших строк
● f = foreign table — внешние таблицы — подключаем другой инстанс PostgreSQL или другой СУБД
Если представить визуально схему логического устройства PostgreSQL, то она будет выглядеть следующим образом:
Давайте посмотрим на практике.
Подключимся к созданному на предыдущем этапе кластеру и посмотрим список БД используя команду psql:
\l

Создадим свою БД и подключимся к ней:
CREATE DATABASE aeugene;
\c aeugene;

Теперь создадим таблицу и добавим пару записей:
CREATE TABLE test (i serial, t text);
INSERT INTO test(t) VALUES (‘Аристов’),(‘Евгений’);
SELECT * FROM test;
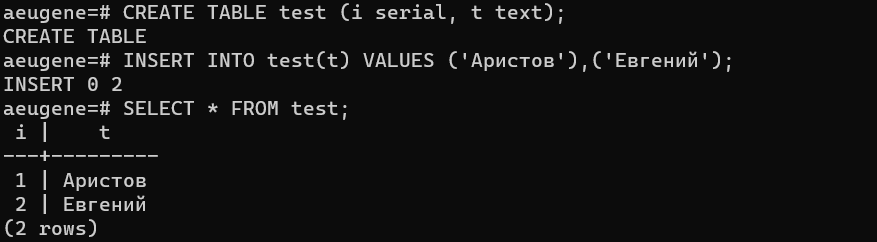
Видим, что автоматический счетчик строк (имя поля i, тип — счетчик с автоматическим увеличением) работает на отлично и обе строки у нас успешно сохранились внутри таблицы test в схеме public (а именно в ней мы по умолчанию и работаем) в БД aeugene.
Какие еще есть возможности по управлению схемой данных для хранения и управления БД мы рассмотрим в следующей статье.
Добавить комментарий