
Статья основана на материалах открытого вебинара “Patroni in Kubernetes”. Запись занятия доступна в youtube, rutube и VKВидео.
Презентация и материалы доступны по ссылке.
Проблематика
В PostgreSQL доступно не так много возможностей для обеспечения высокой доступности — HA (high availability). Вариантов мало:
Типы репликации:
- Логическая
- Физическая
Задержки репликации:
- Синхронная
- Асинхронная
Доступность реплики:
- Warm
- Hot
Рассмотрим структуру проекта Mail.Ru Target, которую представили на конференции Highload. Есть master и пять реплик:
- Реплика failover (sailover на картинке почему-то)
- Реплика для бэкапов (так как они несут большую нагрузку)
- Несколько реплик для OLTP нагрузки
- Реплика для OLAP нагрузки — эти два вида нагрузки обязательно нужно разделять!
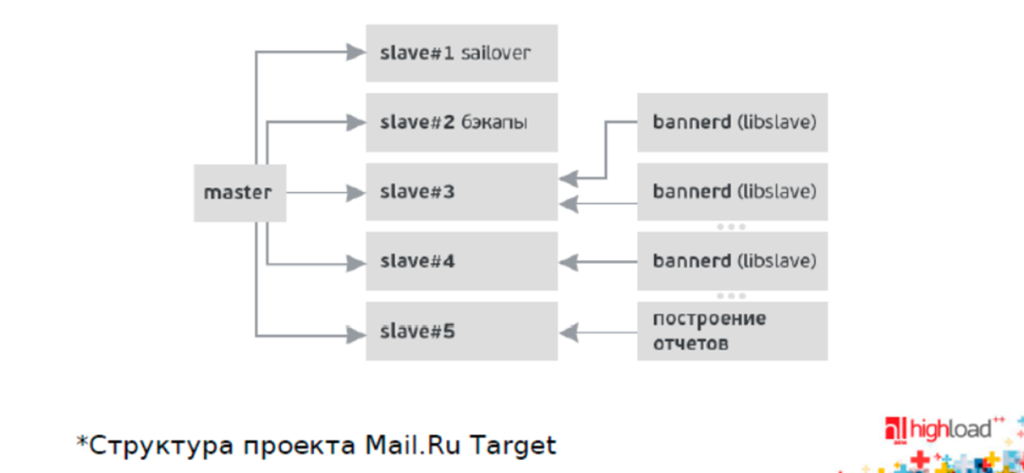
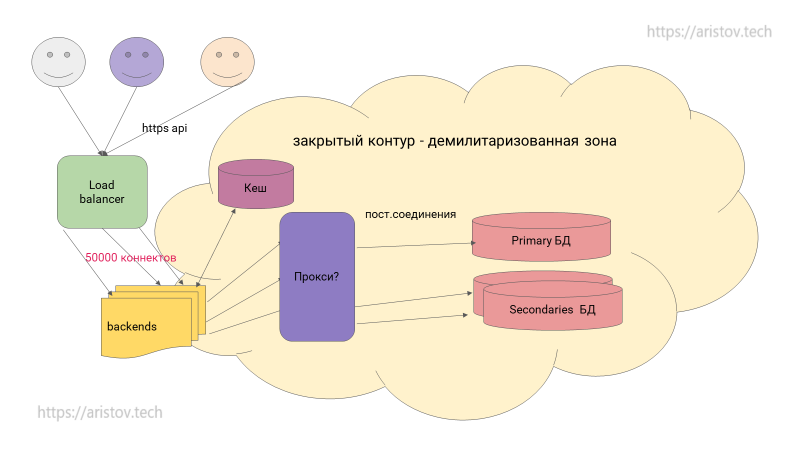
Это классический вариант продакшна.
Пользователи обращаются к лоад балансеру, который перенаправляет на бэкенды, используется кеш. Далее через прокси обращается к БД. Спорный вопрос — где располагать бэкенды — нет точного ответа, размещать их за демилитаризованной зоной или на границе.
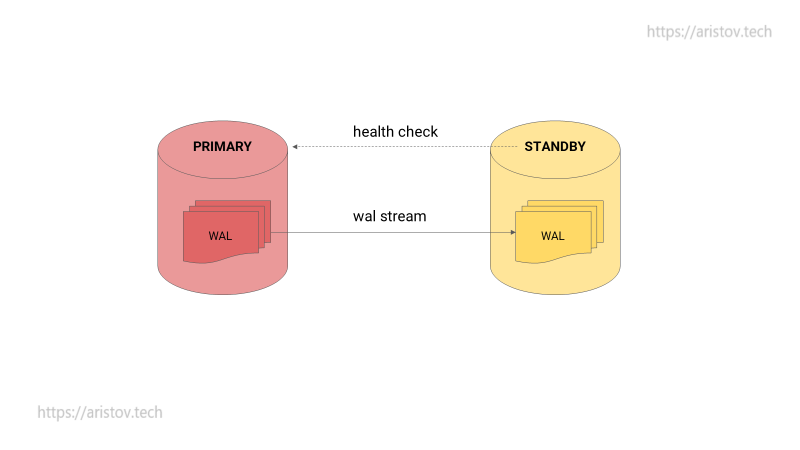
Проблема возникает при выходе из строя PRIMARY — кто будет переключать STANDBY в PRIMARY?
Классическое решение — демон, который выполняет health check и переключает STANDBY ноду.
Но что происходит при обрыве связи? STANDBY считает, что PRIMARY умер и переключается.
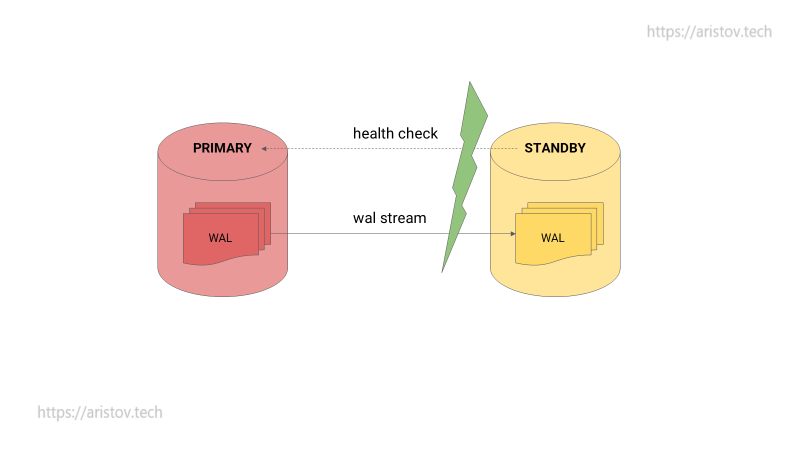
На выходе имеется две PRIMARY ноды — сплитбрейн. Реального решения этой проблемы без потери данных не существует.
Можно добавить наблюдателя — Witness — мониторящего ноды со стороны.
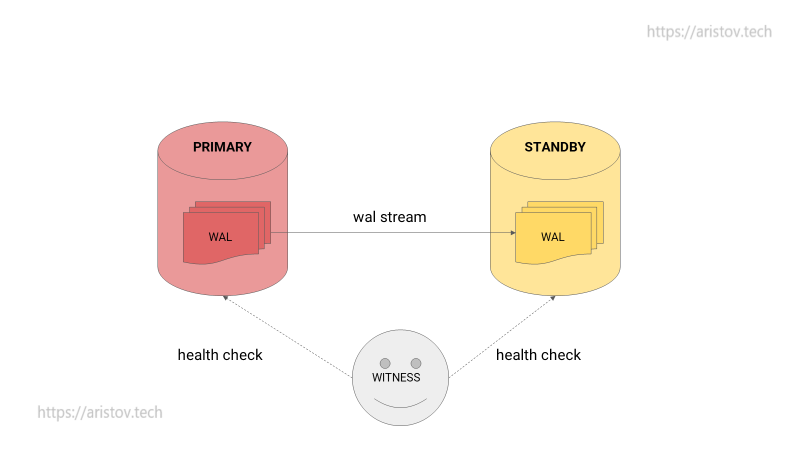
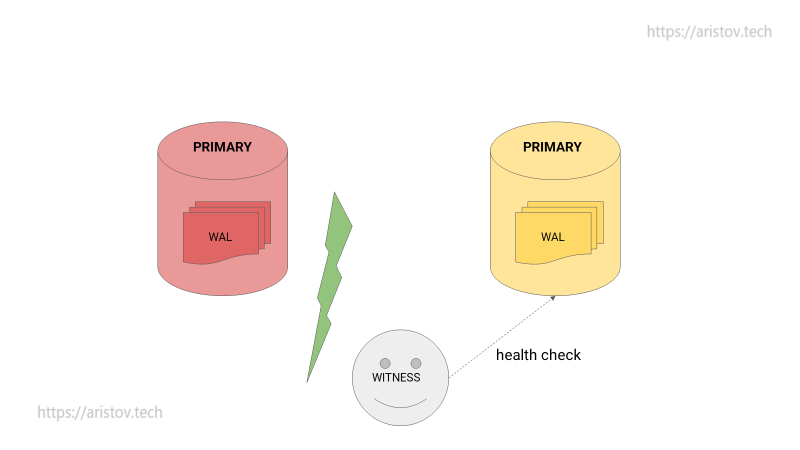
Однако при смерти наблюдателя STANDBY никогда не перейдет в PRIMARY.
При обрыве связи аналогично случаю без наблюдателя появится две PRIMARY ноды.
Существующее решение — добавление не мониторинга, а устойчивого кластера. Тогда лидер пушит сообщения в него, а STANDBY читает с него. В качестве кластера может выступать ETCD/CONSUL/ZOOKEEPER. При смерти PRIMARY или обрыве связи STANDBY по классической схеме (RAFT-протокол) пытаются захватить лидерство.
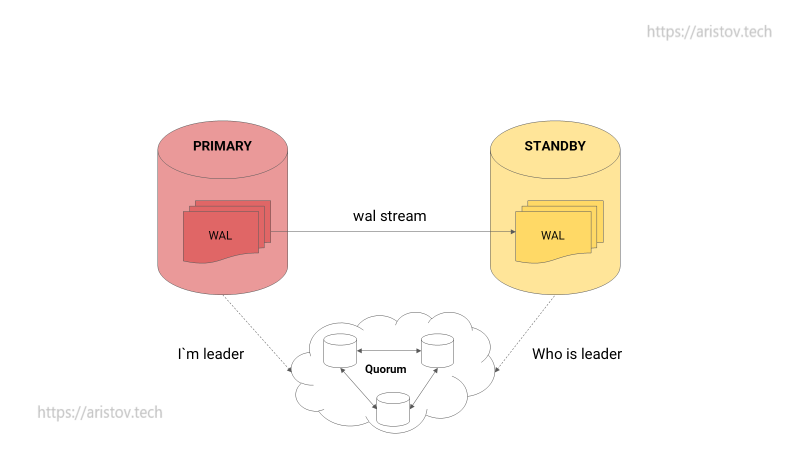
PRIMARY нода пушит ключ, после конца жизни ключа начинается гонка за лидерство.
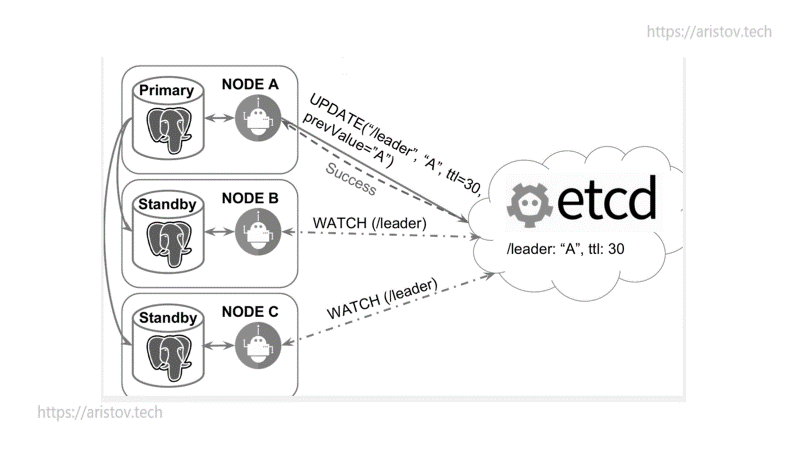
Вся схема может обслуживаться через демонов на Python.
Готовые решения
Вариантов готовых кластеров большое количество, большинство из них Open Source.
HA:
- Patroni (90% рынка)
- Stolon (примерно 9% рынка)
- Slony
- ClusterControl
- Kubegres
Параллельные кластера:
- Postgres-BDR
- CitusData (есть шардирование из коробки)
- Bucardo
- CockroachDB (под капотом является NoSQL решением, но работает по протоколу PotgreSQL)
- Yogabyte
- Greenplum (классический параллельный вариант)
- Arenadata (продвинутый вариант Arenadata)
Классическое решение — Patroni
Из представленных выше решений 90% рынка занимает Patroni от компании Zalando.
Популярность можно объяснить бесплатностью утилиты и большим комьюнити, что позволяет решать возникшие при эксплуатации вопросы.
Разберем схему работы с Patroni.
На входе через HAPROXY определяется master-slave, конфигурация пишется в ETCD, а демоны обсуживают и переключают PostgreSQL. Стоить обратить внимание, что система не отказоустойчива, так как всего один HAPROXY.
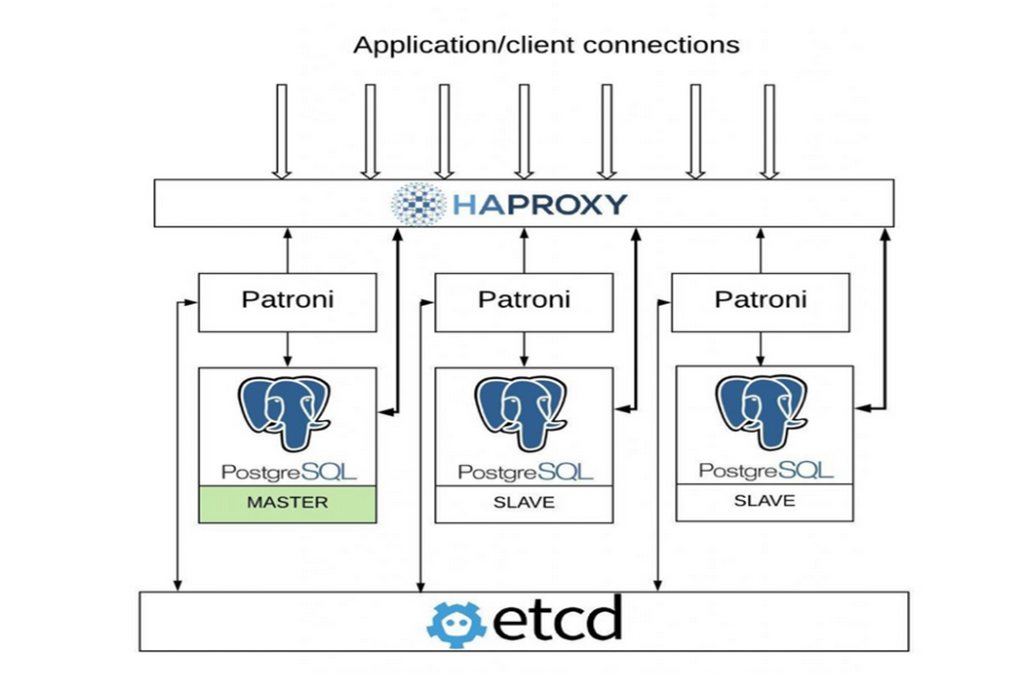
В целом принцип работы Patroni выглядит следующим образом:
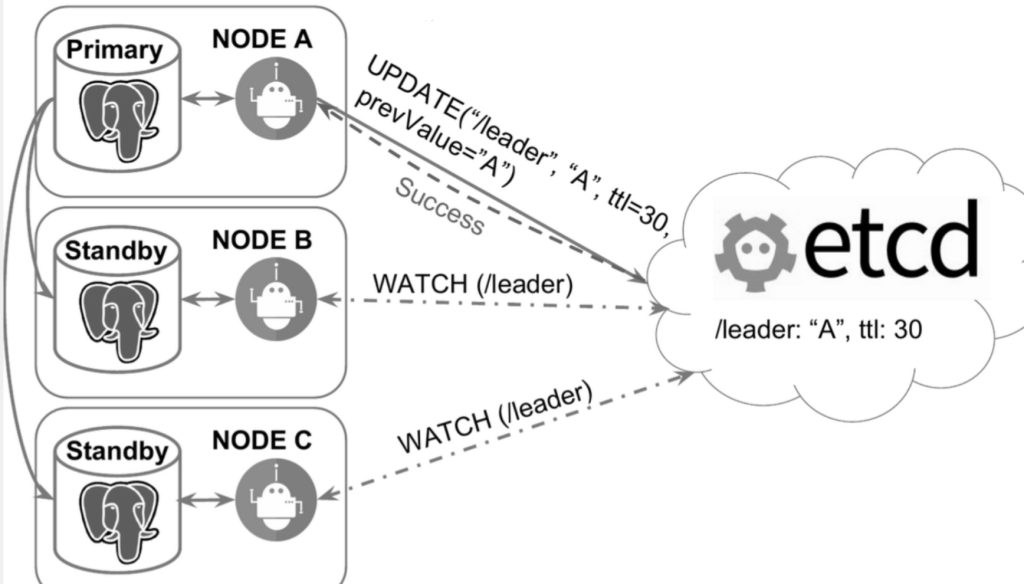
С заданной периодичностью лидер публикует информацию, что он лидер, остальные подписаны на обновления. Как только они видят, что запись просрочилась, начинается гонка для выбора следующего лидера. При этом мастер видит, что DCS недоступна и переходит в режим read only или вообще прекращает принимать подключения — в зависимости от настроек. Когда связь появится — он попытается стать репликой и доприменить все изменения, прошедшие с того времени (если это возможно) или перенакатит все данные снова.
Функции DCS (distributed control system):
- ETCD (или Consul, Zookeeper) хранят информацию о том, кто сейчас лидер
- DCS хранит конфигурацию кластера
- помогает решить проблему с партиционированием сети
При построении отказоустойчивого кластера стоит учитывать и другие принципы:
- STONITH (принцип, при котором некоторые ноды автоматически выводятся из строя для проверки отказоустойчивости)
- watchdog (автоматическая перезагрузка зависшей ноды, например, Nomad by HashiCorp )
Популярным конкурентом ETCD является consul.
- Service check
- Есть GUI
- Есть свой DNS
- Patroni может анонсировать master/replica
- ETCD при большой загрузке дает высокую нагрузку на дисковую подсистему (обычно, когда данные помещаются на те же ноды, куда и PostgreSQL)
С версии 2.0 Patroni нативно поддерживает выборы нового мастера по raft-протоколу без использования etcd/consul, однако в новых версиях эта возможность была отменена.
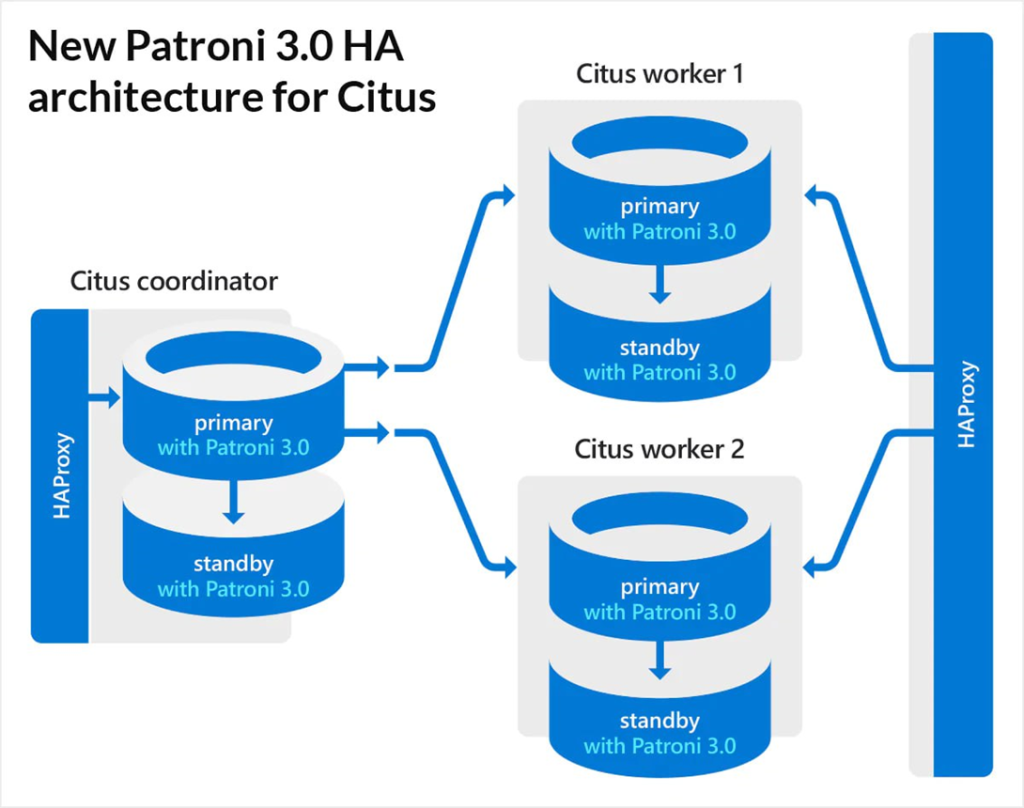
CITUS использует версию Patroni 3.0 без etcd. Присутствует координатор, который знает, где лежат шардированные данные.
Зачем нужен Patroni
- PostgreSQL не умеет взаимодействовать с etcd
- Демон на Python будет запущен рядом с PostgreSQL (единая точка конфигурирования)
- Демон умеет взаимодействовать с etcd
- Демон принимает решение promotion/demotion
DCS на основе ETCD
ETCD — это распределенное хранилище данных вида «ключ-значение»
Особенности:
- хранение небольших объемов метаданных в виде ключей относительно небольшого размера
- полная репликация между нодами и высокая степень доступности
- все данные пишутся на диск, in-memory отсутствует
- использует для работы алгоритм консенсуса RAFT
- написан на Go, кроссплатформенный, имеет небольшой размер и большое сообщество
Преимущества:
- простой API интерфейс http + json
- иерархическая структура хранения данных по аналогии с файловой системой
- возможность отслеживание изменений (watch) и реакция на них (в этом качестве используется в Kubernetes)
- распределенные блокировки
- транзакции
- B-tree индексы для ключей
- полностью ACID
Особенности кластера ETCD:
- минимально отказоустойчивый кластер можно собрать из 3 нод
- мультимастер
- допустимое количество вышедших из строя нод можно посмотреть в таблице (обратите внимание, что сейчас версия API 3+)
- теоретически количество нод не ограничено, но надо помнить о том, что любое изменение данных согласуют все ноды кластера
- задержка записи-чтения (так как используется запись на диск) в свою очередь приводит к нестабильной работе кластера и постоянным переизбраниям мастера
- так как плохо переживает нагрузку на дисковую подсистему — не рекомендуется размещать ноды кластера на используемых уже в продакшне ВМ
- рекомендованный размер кластера — 5 нод
Несмотря на мультимастер, у ETCD по факту присутствует лидер.
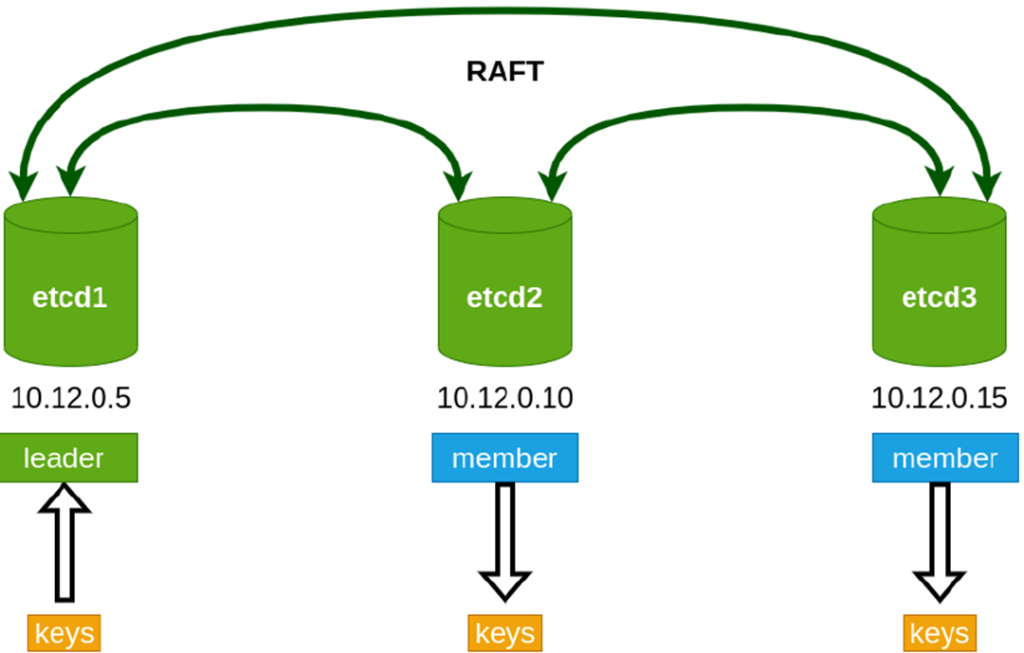
Patroni
Состояние кластера
- patronictl — утилита для управления кластером
- patronictl -c /etc/patroni.yml list (указывается файл, где описан кластер)
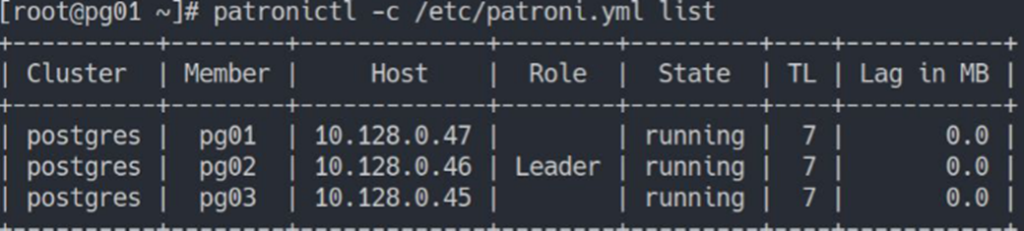
Видно имя кластера, ноды, адреса, лидера и т.д.
Автоматический Failover
#systemctl stop patroni — любой другой способ протестировать failover
- 30 секунд по умолчанию на истечение ключа в DCS
- Далее Patroni стучится на каждую ноду в кластере и спрашивает, не является ли она мастером, проверяет WAL-логи (насколько близки они к мастеру). В итоге, если WAL-логи у всех одинаковые, то выбирается следующий по порядку.
Важно, что опрос нод идёт параллельно.
Основные команды
Редактирование конфигурации — patronictl -c /etc/patroni.yml edit-config
Ручной Switchover — patronictl -c /etc/patroni.yml switchover
Перезагрузка — patronictl -c /etc/patroni.yml restart postgres pg02
Применение новых параметров, требующих обязательной перезагрузки
Реинициализация — patronictl -c /etc/patroni.yml reinit postgres pg03
Реинициализирует ноду в кластере. Т.е. по сути удаляет дата директорию и делает pg_basebackup, если это поведение не изменено параметром create_replica_method
Истории аварий с Patroni, или Как уронить PostgreSQL-кластер
Современный Patroni
Сейчас существует REST API 4.0.3 (версии растут каждый день), у которого интерфейс шире, чем у ctl
Доступ идет по http, нужно закрывать доступ от злоумышленников. Ранее доступ был без шифрования и доступ мог получить кто угодно. Можно зашифровать трафик и требовать сертификаты для доступа и управления patroni
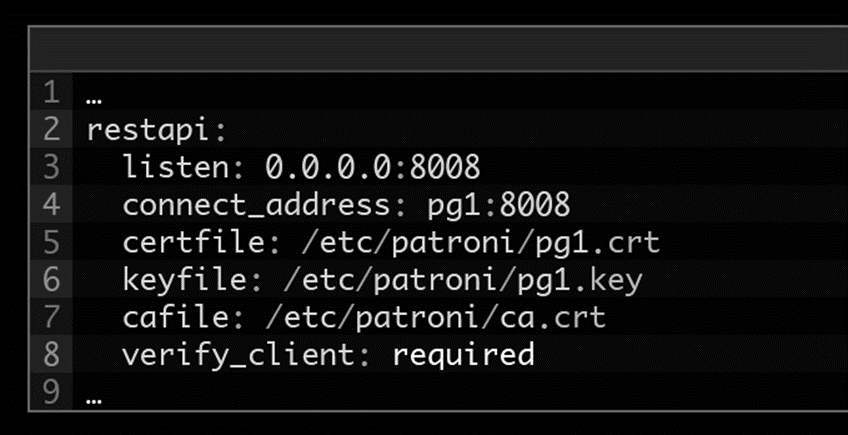
Можно получить доступ к текущим параметрам кластера
GET /read-only: как и вышеупомянутая конечная точка, но включает также основную.
GET /synchronous или GET /sync: возвращает HTTP-код состояния 200, только если узел Patroni работает как синхронный резервный.
GET /read-only-sync: аналогично вышеуказанной конечной точке, но также включает основную.
GET /quorum: возвращает HTTP-код состояния 200, только если этот узел Patroni указан в качестве узла кворума в synchronous_standby_names на основном узле.
GET /read-only-quorum: аналогично вышеуказанной конечной точке, но также включает первичный узел.
GET /asynchronous или GET /async: возвращает HTTP-код состояния 200, только если узел Patroni работает как асинхронный резервный.
GET /patroni
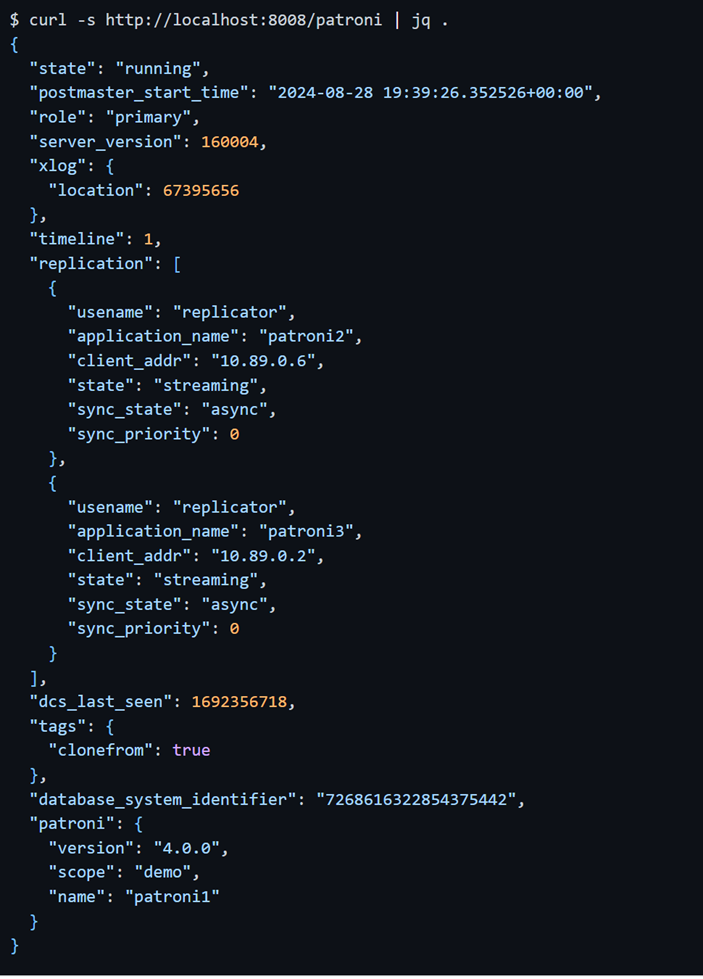
GET /health: возвращает HTTP-код состояния 200, только если PostgreSQL работает.
GET /liveness: возвращает HTTP-код состояния 200, если цикл сердцебиения Patroni запущен правильно, и 503, если последний запуск был более ttl секунд назад на основной или 2*TTL на реплике. Может использоваться для livenessProbe.
GET /readiness: возвращает HTTP-код состояния 200, когда узел Patroni работает как лидер или когда PostgreSQL запущен и работает. Конечная точка может быть использована для readinessProbe, когда невозможно использовать конечные точки Kubernetes для выборов лидера.
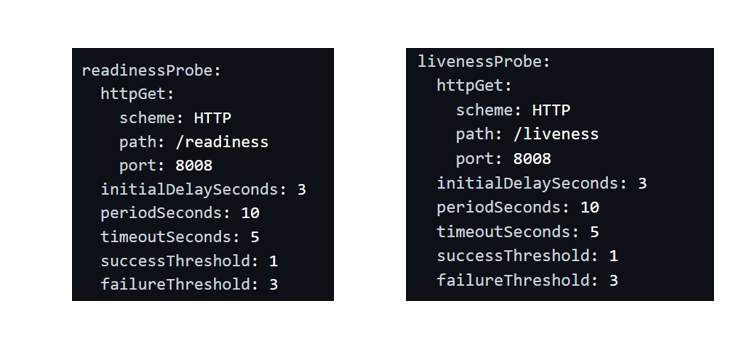
GET /metrics
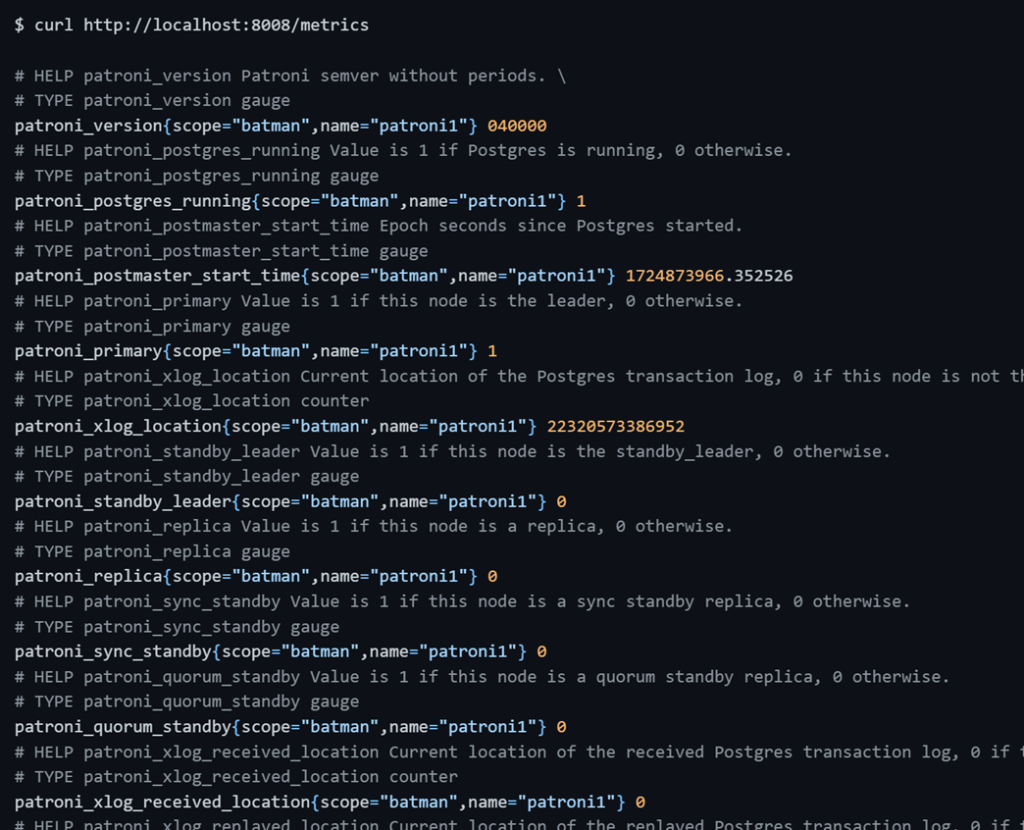
GET /history: история смены таймлайнов (смены основной ноды)
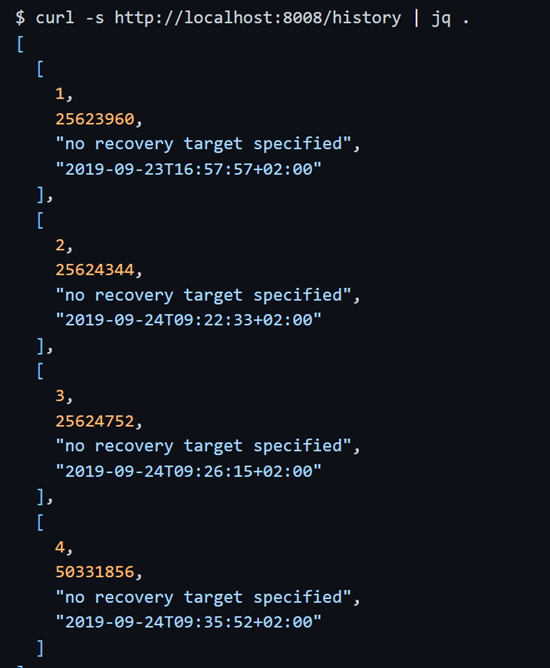
GET /config: текущая динамическая конфигурация
PATCH /config: изменить онлайн параметр
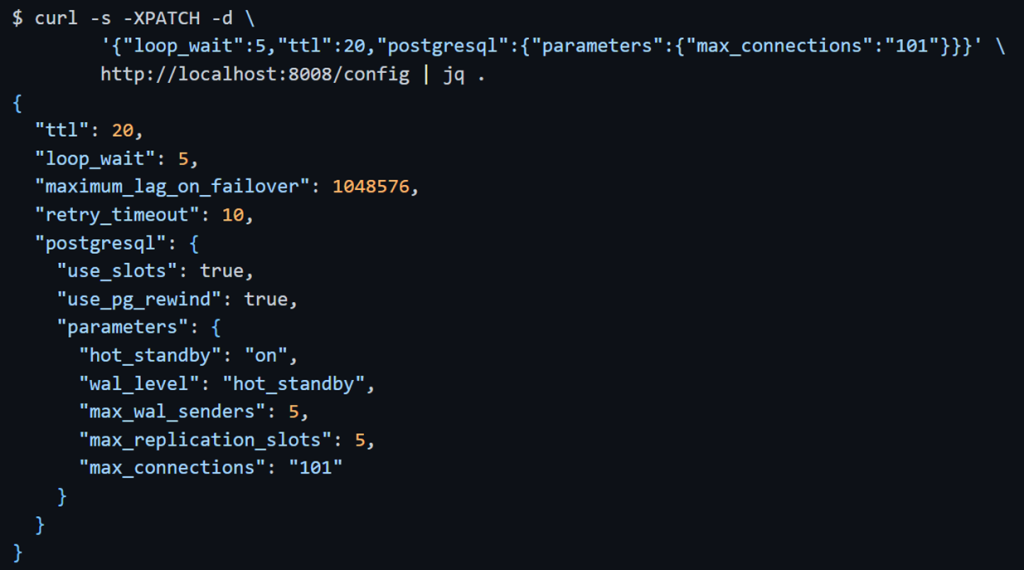
/switchover
/failover
DELETE /switchover — можно удалить планируемое ручное переключение с мастера



POST /reload
POST /reinitialize — переинициализация через pg_basebackup или стороннюю утилиту, указанную replica creation method
PGBouncer
PgBouncer — пул соединений:
- легковесный — 2 Кб на соединение
- можно выбрать тип соединения: на сессию, транзакцию или каждую операцию
- онлайн-реконфигурация без сброса подключений
HAproxy
Помогает выбрать, где нода.
Неплохо бы еще добавить HAPROXY для балансинга нагрузки
Еще варианты балансеров:
- используем или встроенный GLB в облако или варианты:
- NGINX
- Множество хостов в строке подключения
- jdbc:postgresql://node1,node2,node3/postgres?targetServerType=master
- postgresql://host1:port2,host2:port2/?target_session_attrs=read-write
Итоговые варианты архитектуры
1-й вариант
Все идут на HAproxy, далее балансировка нагрузки и отправка на PostgreSQL, который обслуживается Patroni.
Недостаток: HAproxy — единая точка отказа.
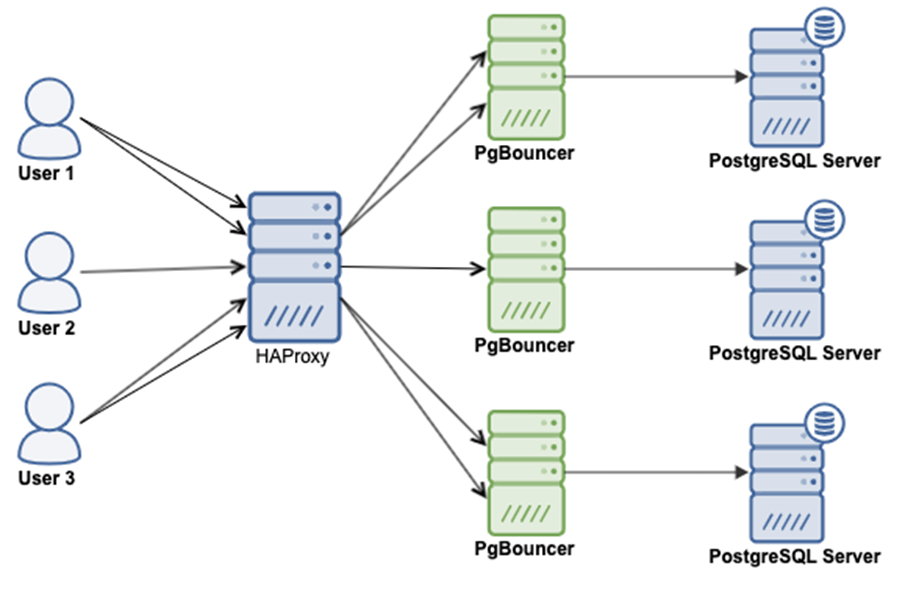
2-й вариант
Сначала балансировка нагрузки, уже потом HAproxy. В данном варианте две точки отказа — и HAproxy, и PgBouncer.
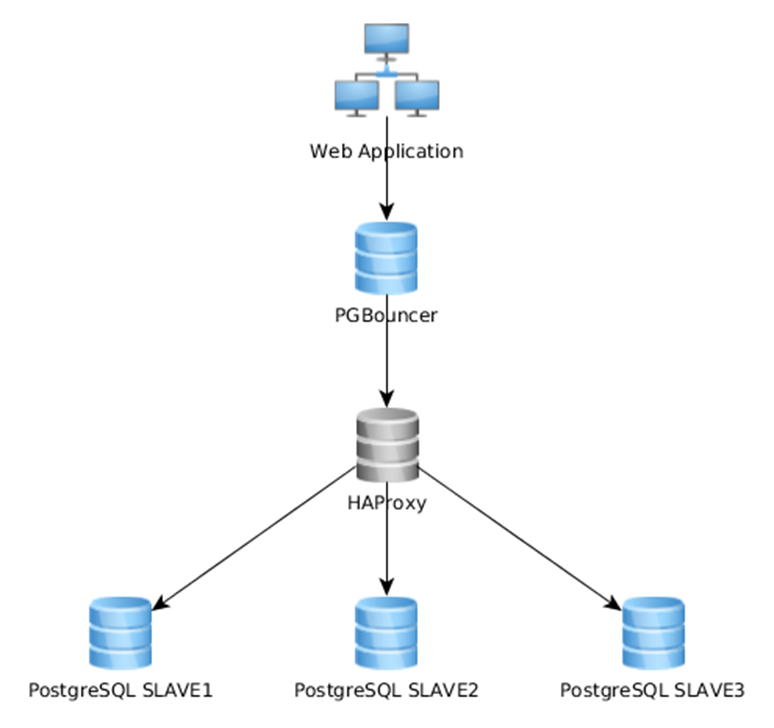
3-й вариант
Вариант от Orion Soft. Keepalived — единая отказоустойчивая точка входа, HAproxy в нескольких вариантах (тоже отказоустойчив), далее балансировщик заменен на Odyssey, ещё один HAproxy (удален в новой версии).

Клиенты ходят на виртуальный IP, который держат две ноды сразу.
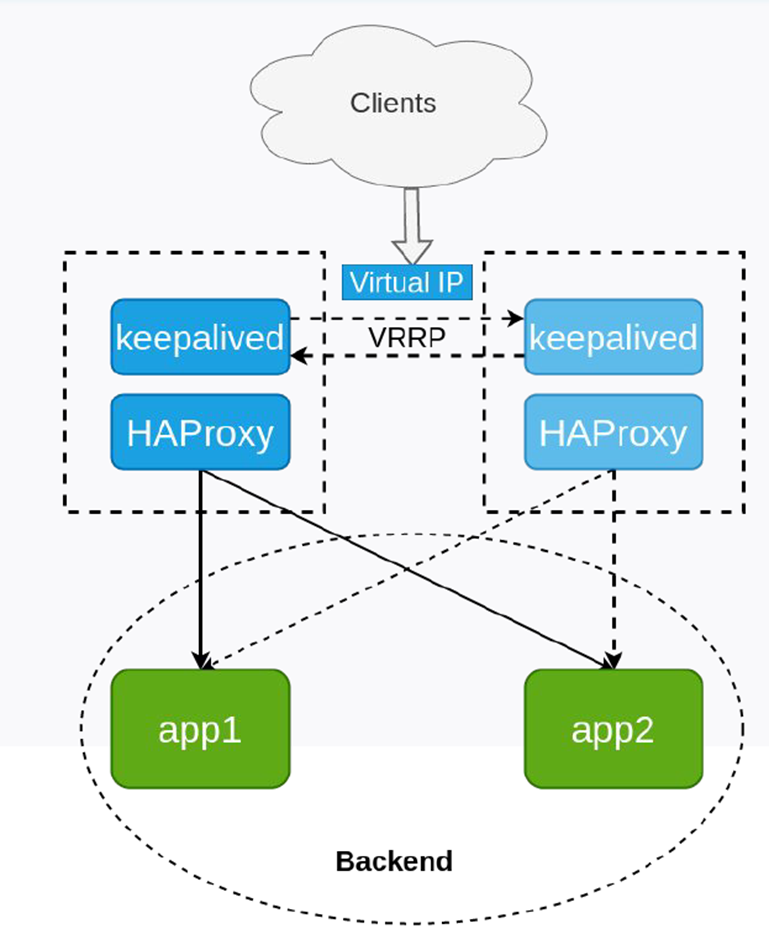
В Гугл облаке не работает, в Яндексе работает.
4-й вариант
Вариант от AWS. Есть глобальный Load Balancer, который знает, где HAproxy и PgBouncer. Если кто-то из них не справляется, то система масштабируется
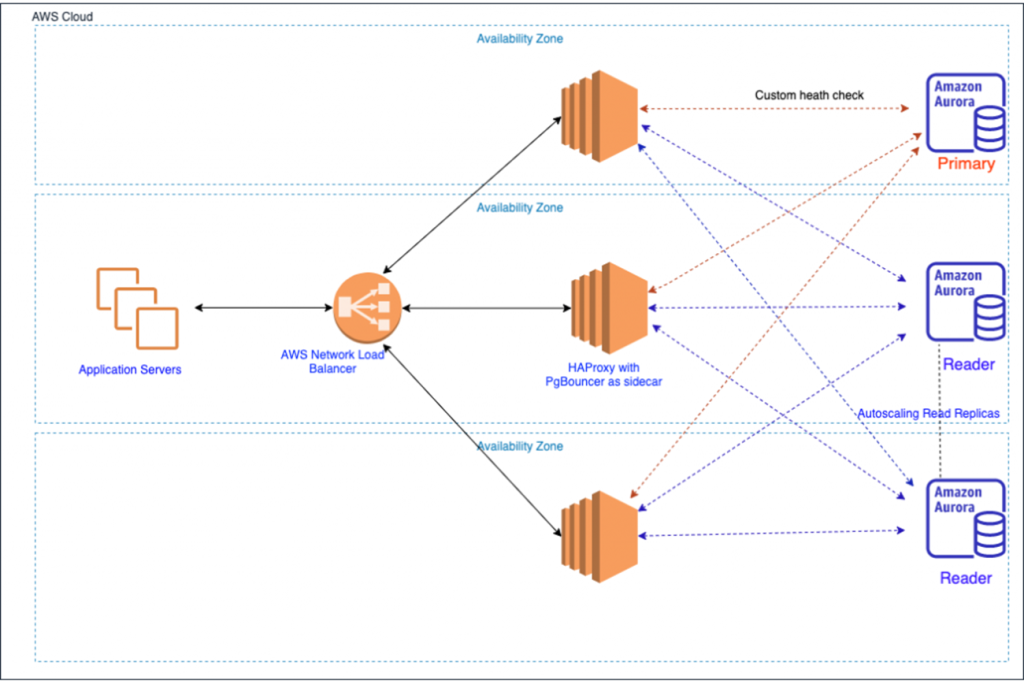
Облачные варианты
DBaaS
Плюсы:
- кластер за пару кликов в GUI
- бэкапы, репликация за 1 нажатие
Минусы:
- повышенная стоимость — только платные лицензии
- нет контроля над инстансом
- минимум настроек
- дебаг запросов превращается в многоуровневый квест
- обычно HA реплику не получится использовать как read реплику
- огромная сложность построения мултиклауд конфигураций и даже реплики у другого провайдера
- время развертывания инстанса значительно превышает вариант on premise
Kubernetes
Оркестратор над Docker контейнерами. Позволяет убрать слой абстракции и упростить работу.
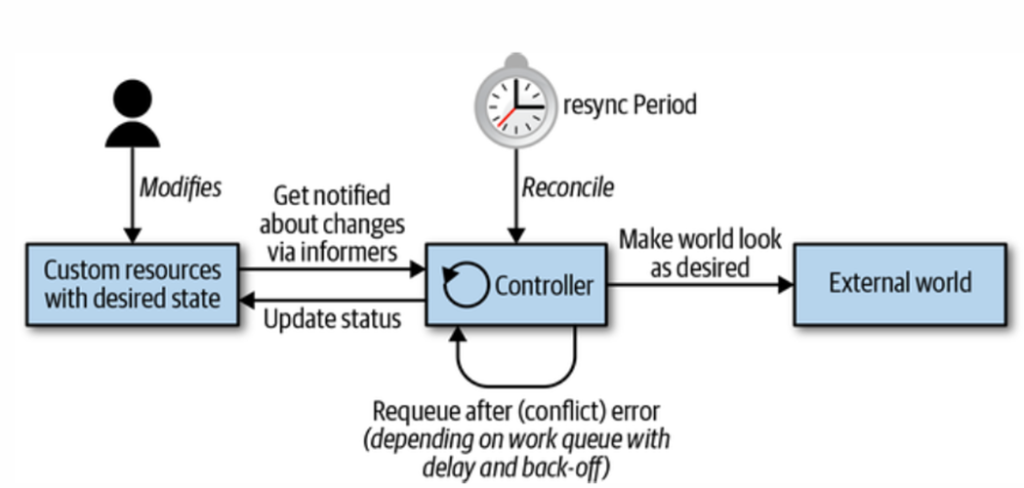
K8s хранит декларативное описание желаемого состояния в виде набора ресурсов разных типов, а набор контроллеров (и операторов):
1. Обнаруживает несоответствия и делает все возможное, чтобы их устранить
2. Слушает изменения состояния и обновляет статус объектов
K8s – это конструктор, который позволяет хранить и работать с разными типами ресурсов и выбирать подходящий контроллер для достижения того или иного состояния.
Настройка с помощью yaml-файлов проще и позволяет использовать ресурсы почти на 100%. При сбое одной ВМ происходит автоматическая миграция на другие. По сути является инструментом автоматического масштабирования.
Спорным вопросом является PostgreSQL в Kubernetes.
В схеме работы есть Kubernetes Master, которому через API отправляются запросы. Он знает, где находятся ноды, за которыми наблюдает Kubelet (сравнивает то, что нужно, с тем, что уже есть).
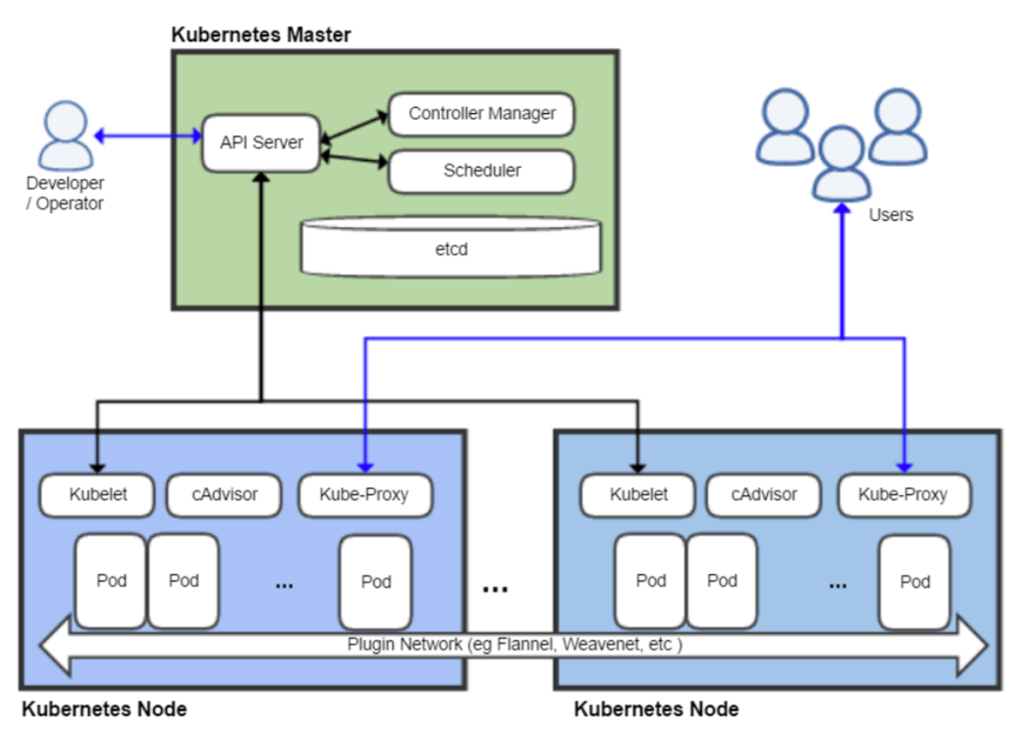
Можно разворачивать как в облачном, так и on premise кластере.
Плюсы — гибкость и простота развертывания HA конфигураций со встроенными пулерами и т.д., обычно есть GUI для управления.
Варианты запуска:
- свой релиз обернуть в чарт
- cloud native
- операторы (для YAML разработчиков новый тип ресурса — postgresql)
- от авторов Patroni
- от дистрибьютора Crunchy
- от контрибьютора EnterpriseDB
- на хабе операторов 15 вариантов
Архитектуру на примере
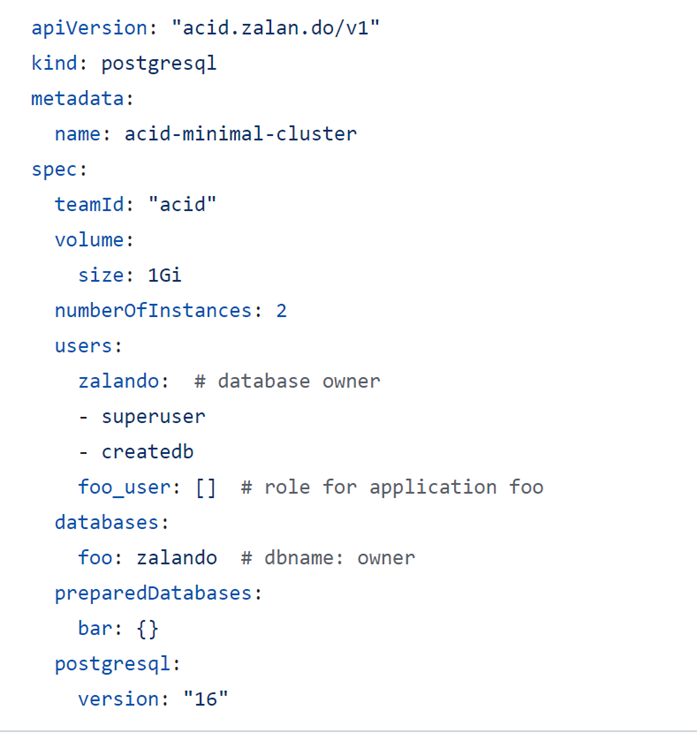
Данный конфиг создает готовый автоматизированный отказоустойчивый кластер Patroni.
В статье на Хабре собраны и протестированы основные операторы:
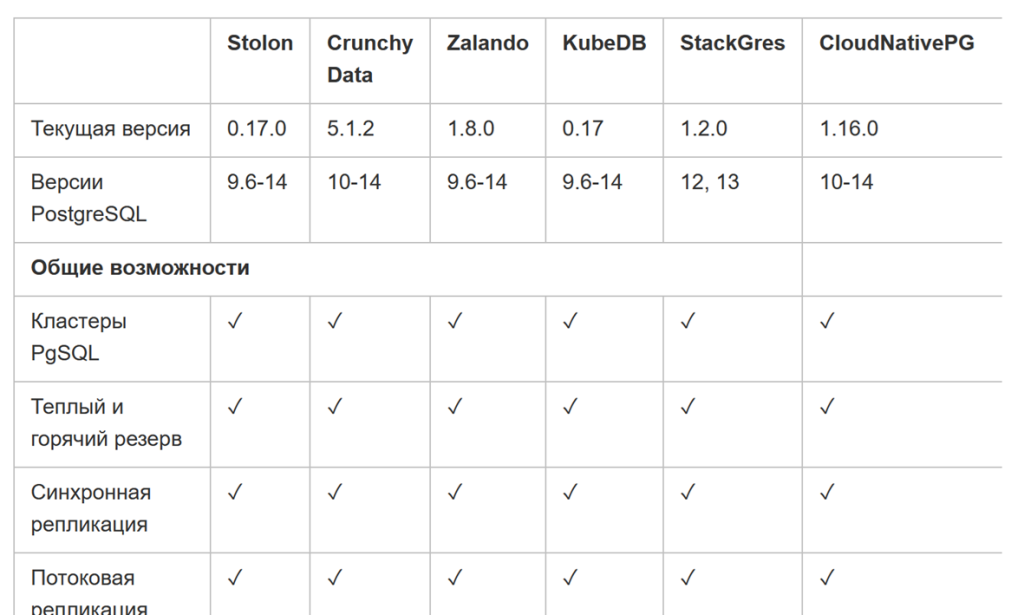
Плюсы Kubernetes:
Расплачиваемся за дополнительный уровень абстракции ресурсами
- Огромная гибкость, масштабируемость и отказоустойчивость
- Миграция управляющих pod между нодами
- Выше порог входа для k8s
- Ниже для создания HA PostgreSQL, но выше для решения возникших проблем
- Наоборот для On-premise
Минусы Kubernetes:
- On-premise позволяет утилизировать 100% ресурсов
- Производительность локальных NVMe значительно выше CEPH и аналогов
Практика
Скрипты, как обычно, доступны на github.
Создание кластера одной командой (3 ноды, время создания примерно 5 минут):
gcloud beta container --node-locations "us-central1-c"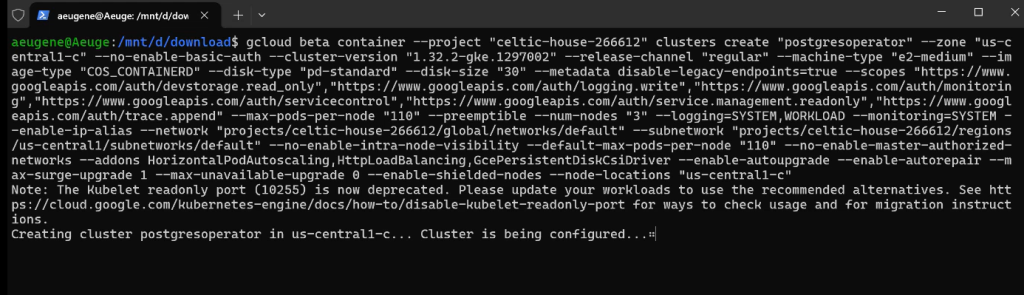

Обратите внимание, что в гугл облаке версии постоянно меняются, после обновления старую версию развернуть не получится.
Список кластеров:
gcloud container clusters list 
Внутренности кластера:
kubectl get all 
Внутренности под капотом:
kubectl get all -A 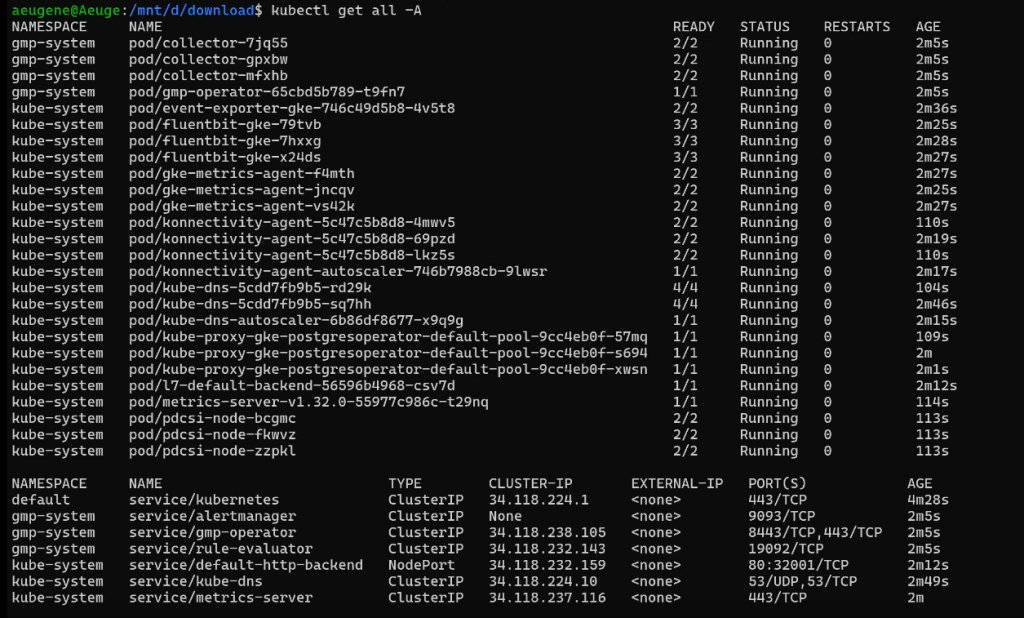
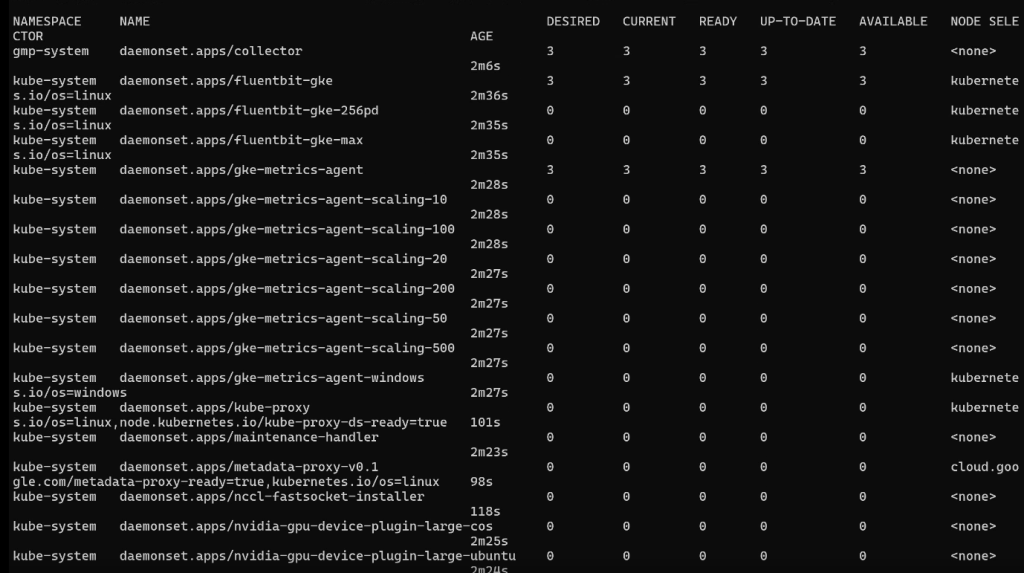
Ресурсы текущего кластера:
kubectl api-resources 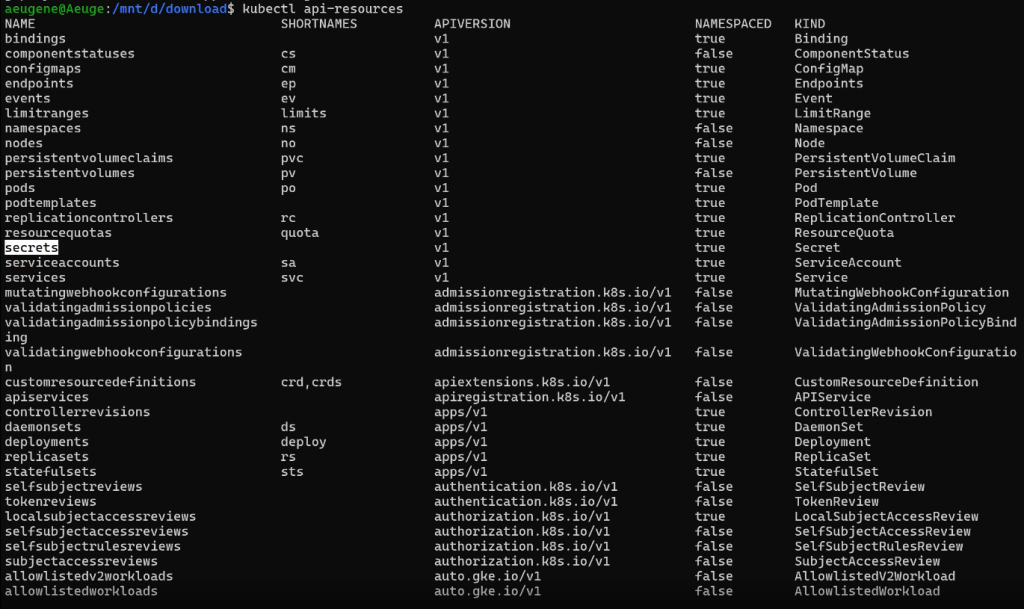
В базовой конфигурации нет PostgreSQL. Установим его:
cd /mnt/d/download
git clone https://github.com/zalando/postgres-operator
cd postgres-operator
helm install postgres-operator ./charts/postgres-operatorhelm install является установкой приложения, которое можно обновлять и удалять.

Проверка, что postgres стартовал:
kubectl --namespace=default get pods -l "app.kubernetes.io/name=postgres-operator"
Проверка, что ресурс появился:
kubectl api-resources | grep postgres 
Установим графический интерфейс:
helm install postgres-operator-ui ./charts/postgres-operator-ui
Проверка запуска:
kubectl --namespace=default get pods -l "app.kubernetes.io/name=postgres-operator-ui"
Проверим, что все сервисы появились:
kubectl get all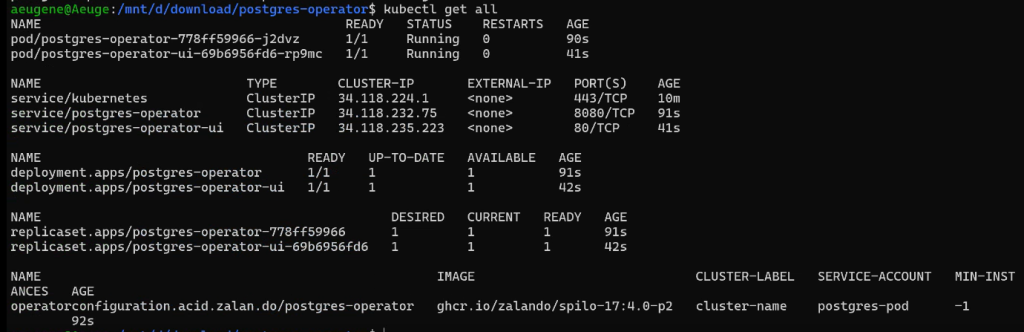
Создание порта до контейнера:
kubectl port-forward svc/postgres-operator-ui 8081:80
Ссылка для перехода в интерфейс — http://localhost:8081/#new
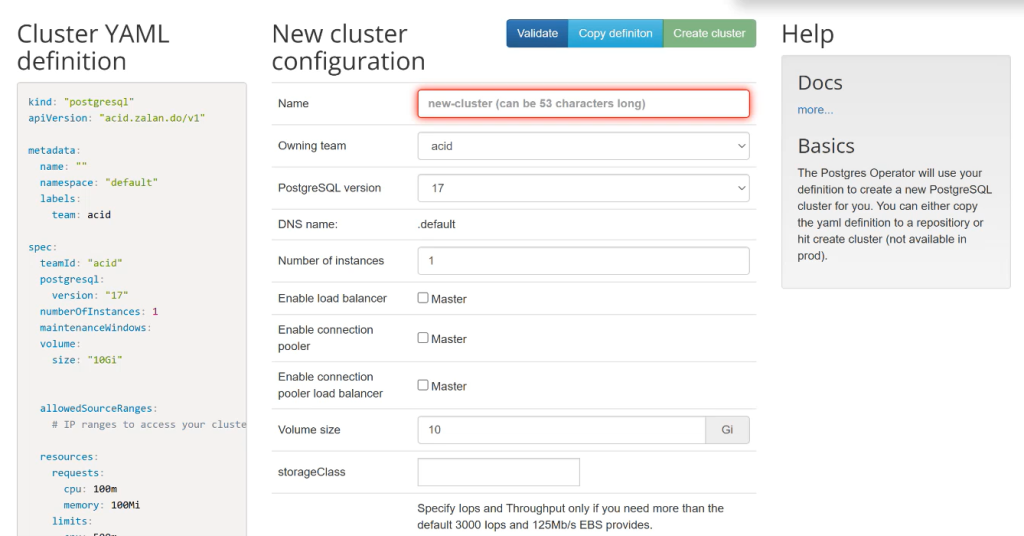
Создаем кластер (заполняем имя, версию, количество инстансов):
Процесс запуска:
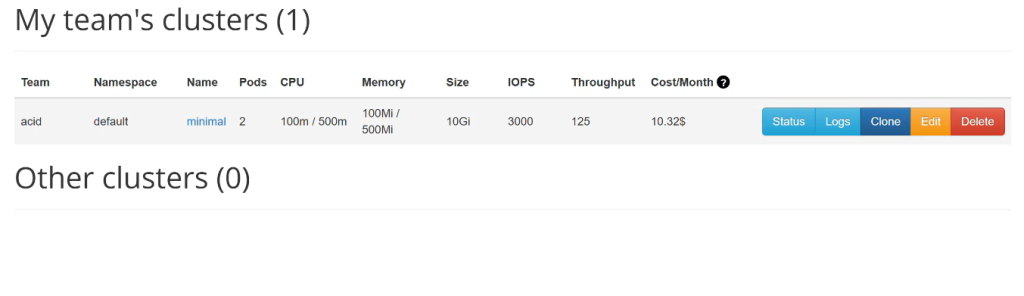
Проверим, где что лежит:
kubectl get all -o wide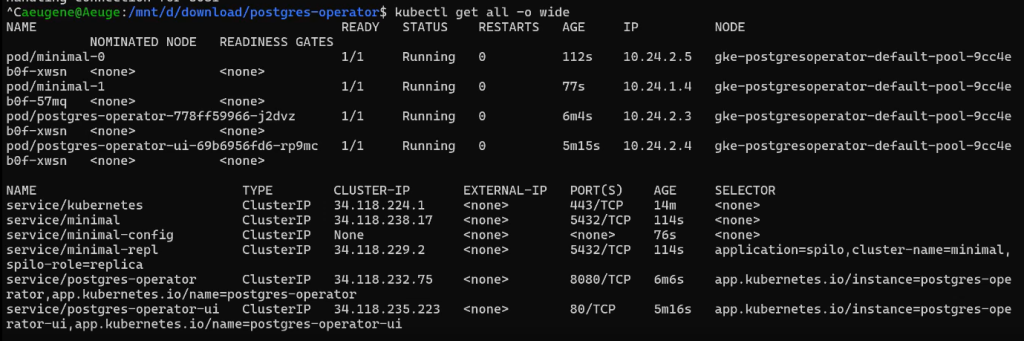
Подробная информация о ноде:
kubectl get node gke-postgresoperator-default-pool-9cc4eb0f-57mq -o wide
У кластера свой диск под каждую ноду:
gcloud compute disks list
Проверка ресурсов:
kubectl top node gke-postgresoperator-default-pool-9cc4eb0f-57mq
Для проверки postgres экспортируем пароль:
export PGPASSWORD=$(kubectl get secret postgres.minimal.credentials.postgresql.acid.zalan.do -o 'jsonpath={.data.password}' | base64 -d)echo $PGPASSWORD
Прокидываем порты:
kubectl port-forward service/minimal-repl 5433:5432
Подключение изнутри:
psql -U postgres -h localhost -p 5433 -W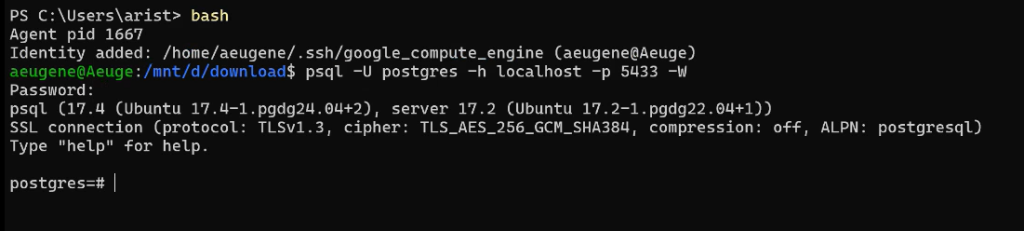

Зайдем внутрь контейнера:
kubectl exec -it pod/minimal-0 -- bashПроверка сборки:
kubectl exec -it pod/minimal-1 -- patronictl -c postgres.yml list
Удаление кластера:
gcloud container clusters delete postgresoperator --zone us-central1-c
Спасибо, что прочитали статью. Приходите на следующие ОУ!!!
Список из 6 предыдущих также доступен.
Добавить комментарий