Статья основана на материалах открытого вебинара, прошедшего 30.10. Запись занятия доступна в ютуб версии, рутуб версии и VK Видео.
Презентация и исходники доступны по ссылке.
Проблематика
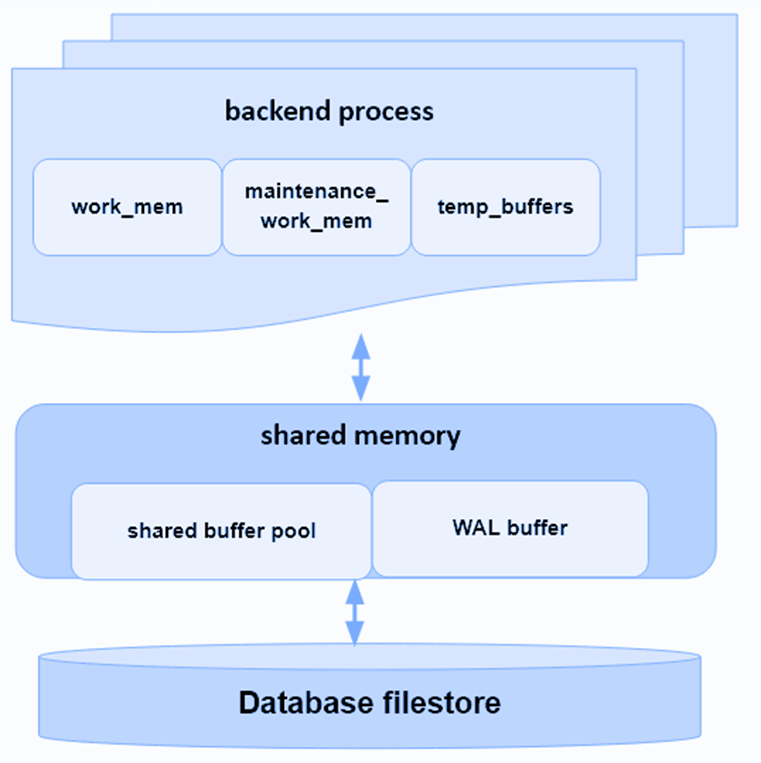
Классический старт PostgreSQL: запускается базовый процесс postgres, происходит его fork (каждый fork процесса занимается своей задачей), формируется разделяемая память, в которой лежит буферный пул и другие структуры.
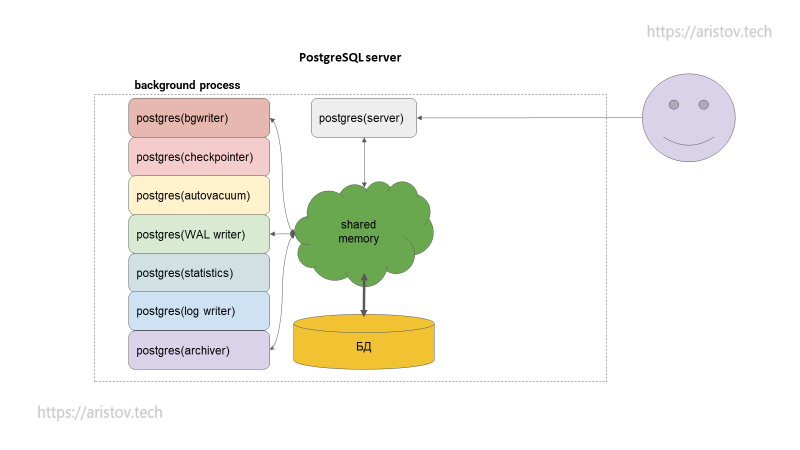
Далее приходит клиент и снова происходит fork процесса postgres.
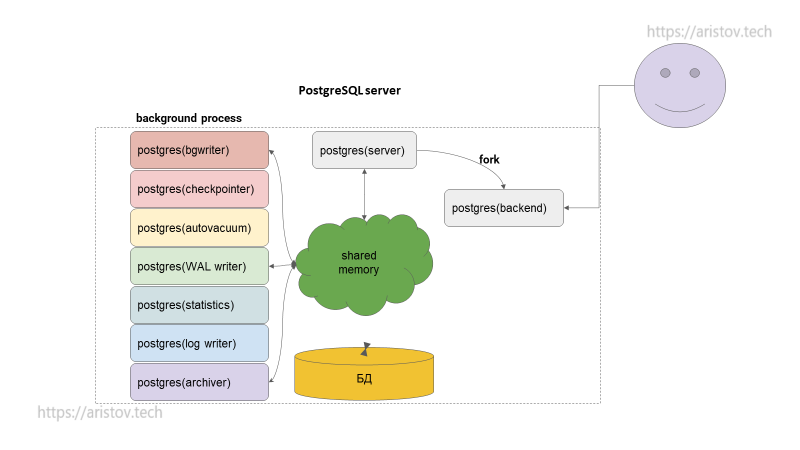
Затем приходит следующий пользователь и снова происходит fork процесса и так далее с каждым новым пользователем (fork — это хоть и быстро, но затратно по ресурсам).
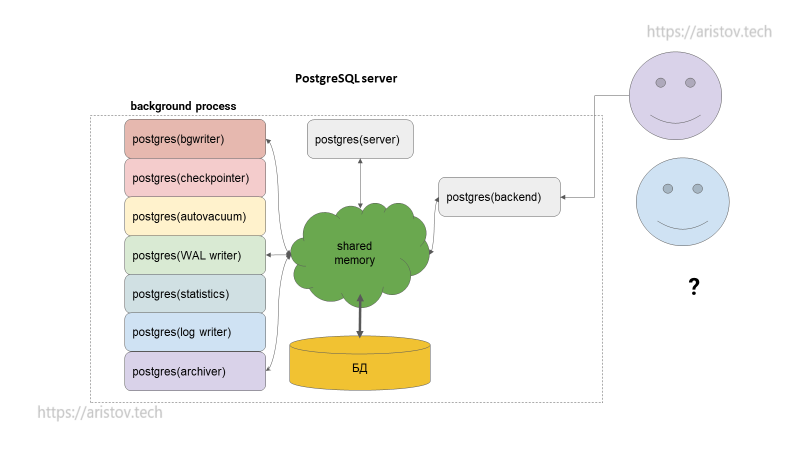
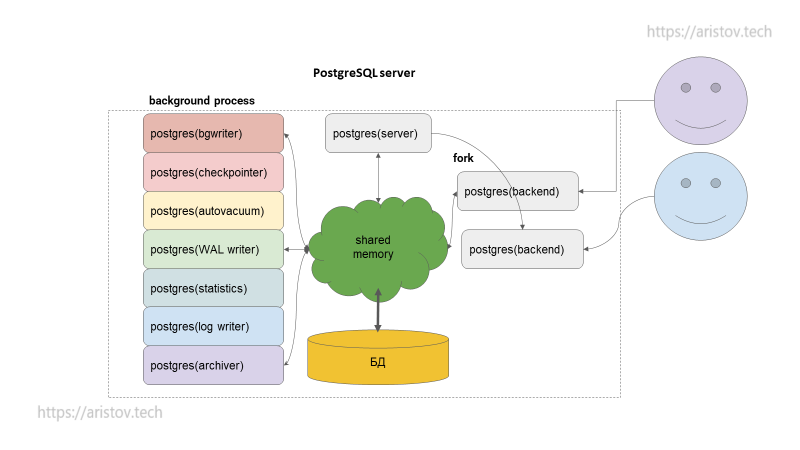
На каждый процесс выделяется своя память. Классически на backend process выделяется work_mem — 4 МБ (при различных операциях сортировки и хэширования может выделяться неоднократно — до 5 раз). Она используется на этапе выполнения запроса. Также может выделяться maintenance_work_mem — 64 МБ, если используются служебные операции (indexes, vacuum и т. д.). Temp_buffers — 8 МБ -выделяется при использовании временных таблиц. Обязательно выделяются shared buffer для чтения данных с диска/индекса.
В итоге подключение новых пользователей — одно из больных мест PostgreSQL из-за использования памяти.
Выработанная практически формула настройки памяти:
ОЗУ (>ГБ) + Shared buffers (25-40%) + max_connections * (work_mem + temp_buffers) + maintance_parallel_workers * maintance_work_mem.
Если пролетели с настройками памяти, то OOM killer может прийти и убить базовый процесс вместо backend process, что довольно печально.
Варианты доступа к кластеру
Варианты подключение к PostgreSQL
После установки PostgreSQL запускается с такими параметрами:

Подробнее об установке в статьях — установка PostgreSQL и варианты установки.
Изначально открыт доступ только с локальной машины. Классический доступ может получить суперпользователь (через sudo), например, пользователь postgres. Он предназначен для запуска кластера PostgreSQL и является владельцем всех файлов, относящихся к PostgreSQL (исполняемых файлов, файлов данных и логов). По умолчанию к этим файлам кроме него могут получить доступ только суперпользователи Linux — root и группа пользователей, имеющая право на запуск утилиты sudo, позволяющей повысить свои личные права до прав суперпользователя.
Доступ к PostgreSQL после запуска возможен только через psql и Unix socket. Это означает, что пароль от единственного пользователя СУБД НЕ будет запрашиваться при входе в PostgreSQL, вместо этого PostgreSQL спросит у ОС — авторизован ли такой пользователь в ОС.
В нашем случае суперпользователь БД также имеет имя postgres. Если в Linux перейти от пользователя aeugene к пользователю postgres (повысив свои права до суперпользователя Linux и дав команду переключиться на пользователя postgres), то при запуске утилиты psql произойдет следующее — PostgreSQL спросит у Linux авторизован ли пользователь postgres и пустит внутрь СУБД без пароля. Иначе доступ мы не получим.
Рекомендуется НЕ использовать пользователя postgres, а создавать своих пользователей с нужными правами. На пользователя postgres же ставить сложный пароль.
Варианты подключения к PostgreSQL:
- Зайти в psql под пользователем postges (sudo su postgres)
- Повысить свои права и выполнить команду psql из-под пользователя postgres (не заходя под его именем) — sudo -u postgres psql.
Варианты аутентификации
Кроме подключения по Unix Socket стандартным подключением к СУБД является подключение по сети (протокол TCP/IP).
Для того, чтобы зайти по сети мы должны отредактировать два конфигурационных файла:
- hba_file.conf — настройки встроенного в PostgreSQL firewall
- postgresql.conf — настройки PostgreSQL, в том числе подключений извне
Расположение этих файлов зависит от типа и варианта ОС. Посмотреть, где они расположены можно из утилиты psql:
- show hba_file;
- show config_file;
В Ubuntu данные файлы расположены:
- /etc/postgresql/16/main/pg_hba.conf
- /etc/postgresql/16/main/postgresql.conf
Используем утилиту просмотра файлов cat под текущим пользователем Linux postgres:
cat /etc/postgresql/16/main/pg_hba.confОткрывайте только сетевое подключение в доверенной локальной сети! НЕ рекомендуется открывать доступ в интернет!

Подробнее о подключении к кластеру и подключении из командной строки.
Шифрование паролей
С14 версии по умолчанию используется система шифрования паролей SCRAM-SHA-256, а в более ранних версиях — система MD5. Обратите внимание, что они не совместимы, при обновлении кластера с 13 на 14+ версию нужно это иметь в виду. Не стоит использовать систему PASSWORD — пароль передается в открытом виде.
Алгоритм подключения
Чтобы задать пароль необходимо:
- зайти в консоль
- psql
- установить пароль для текущего пользователя (два варианта):
- команда psql — \password
- SQL команда ALTER USER postgres PASSWORD ‘123’;
Теперь мы можем зайти по сети на localhost (127.0.0.1).
Для этого необходимо выполнить 3 шага:
- выйти из psql — \q
- подключиться указав хост для подключения — psql -h localhost
- посмотреть статус подключения — \conninfo
Видим, что теперь мы вместо Unix Socket подключились по сети с localhost.
Напоминаю, что psql мы запускаем из Linux из-под пользователя postgres. Если закрыли консоль, переключиться на пользователя postgres можно выполнив sudo su postgres.
Подключение к PostgreSQL извне
Для подключения извне ВМ, нам необходимо сделать несколько больше шагов:
- включаем listener в postgresql.conf (обычно 2 сети — внутренняя и внешняя — интернет. Подключение через интернет категорически не рекомендуется).
- Установить IP адреса, на которых принимает подключения PostgreSQL, например localhost, 10.*.*.* (два варианта):
- listen_addresses = ‘*’ # IP адреса, на которых принимает подключения PostgreSQL, например localhost, 10.*.*.*;
- alter system set listen_addresses = ‘*’;
- включаем вход по паролю в pg_hba.conf и меняем маску подсети:
host all all 0.0.0.0/0 scram-sha-256
- Добавляем порт во внешний firewall, используемый у вас в организации
- задаем пароль юзеру postgres — ALTER USER postgres PASSWORD ‘123’;
- Перегружаем сервер — pg_ctlcluster 16 main restart — обратите внимание, что при установке PostgreSQL запущен от имени root и рестарт от пользователя postgres мы сделать не можем (только stop и потом start). Правильно потом переконфигурировать пользователя на postgres при старте ВМ.
- Подключаемся — psql -h 104.197.151.20 -U postgres.. Теперь мы внутри нашего кластера и можем посмотреть параметры подключения выполнив — \conninfo
Подключение из других версий
Так как у PostgreSQL универсальный протокол обмена между кластерами и версиями, то никаких проблем при совместимости, начиная с версии 9.6, не наблюдается. Естественно, если вы используете psql 16 версии и подключаетесь к 10, то функционал будет доступен только 10 версии.
Текущая конфигурация
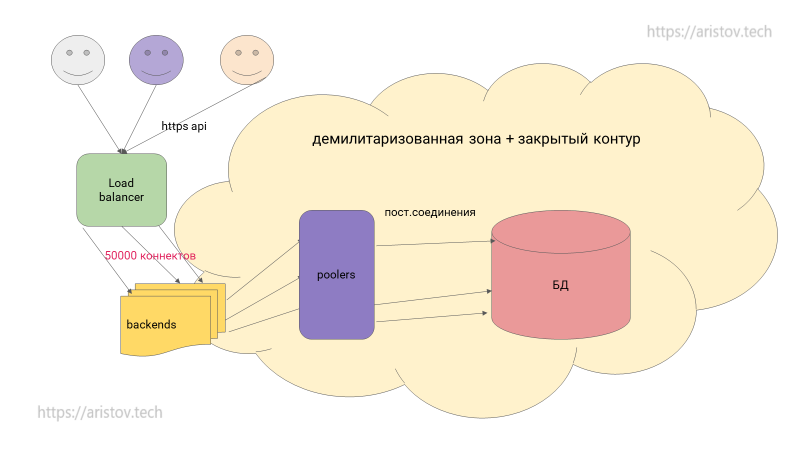
Пользователи подключаются, load balancer отправляет трафик на backend.
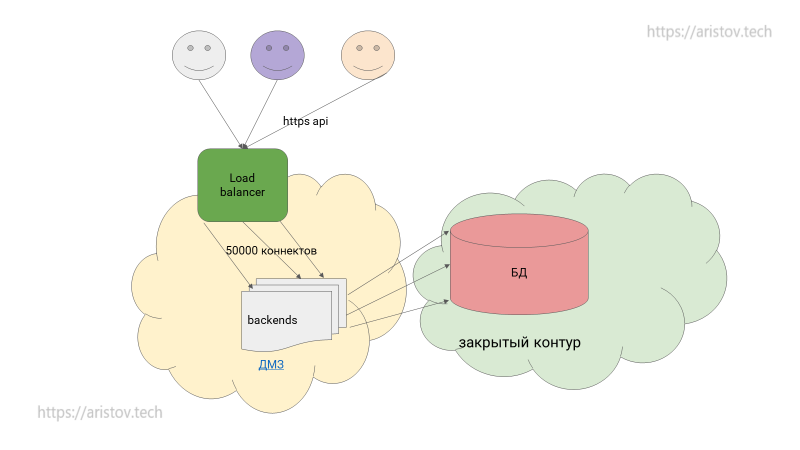
Однако, несмотря на встроенный firewall, PostgreSQL — не средство защиты от DDoS и других атак:
- желательно работать только в доверенной зоне
- менять стандартный порт
- аккуратнее поднимать докер контейнеры с портом наружу -p 5432:5432 — лучше докер сеть и по ней доступ к бэкендам (k8s и port-forward)
- сложные пароли
По умолчанию в допустимое количество соединений в PostgreSQL — 100.
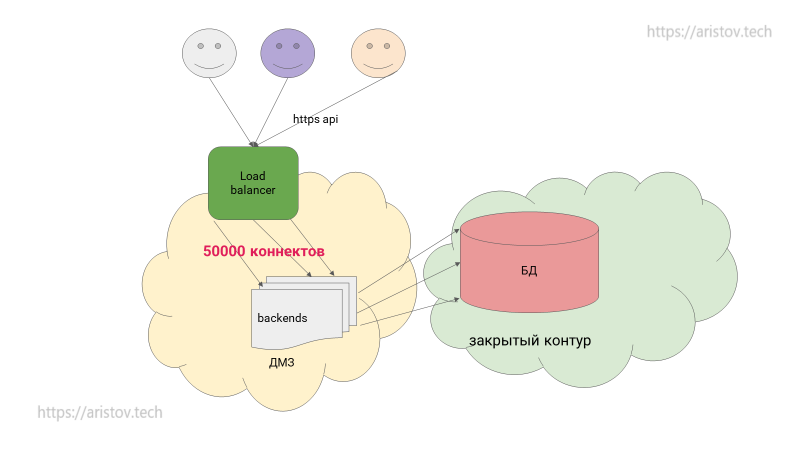
Эксперимент по увеличению количества возможных соединений:
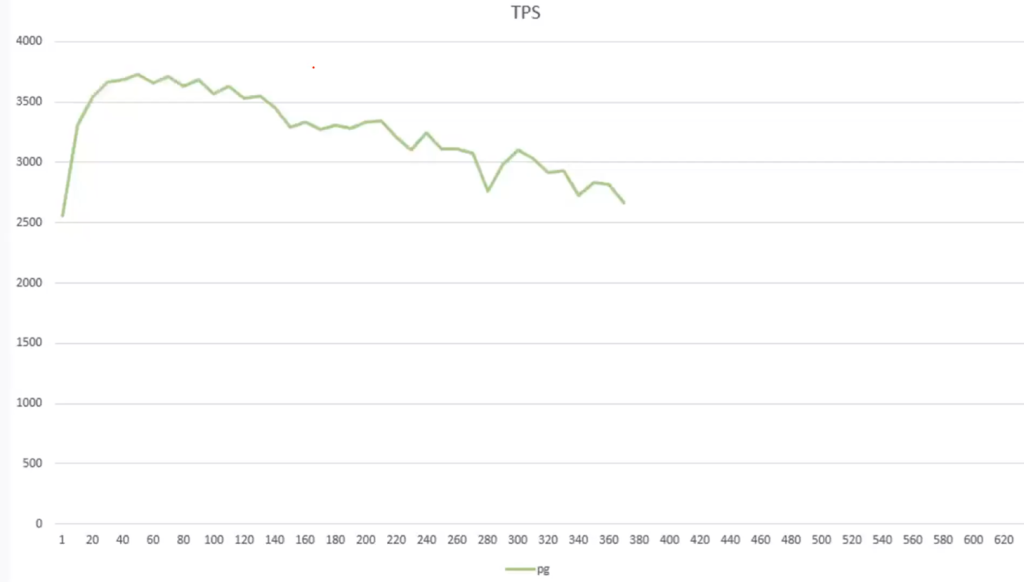
Аналогичный эксперимент при использовании pgbouncer:
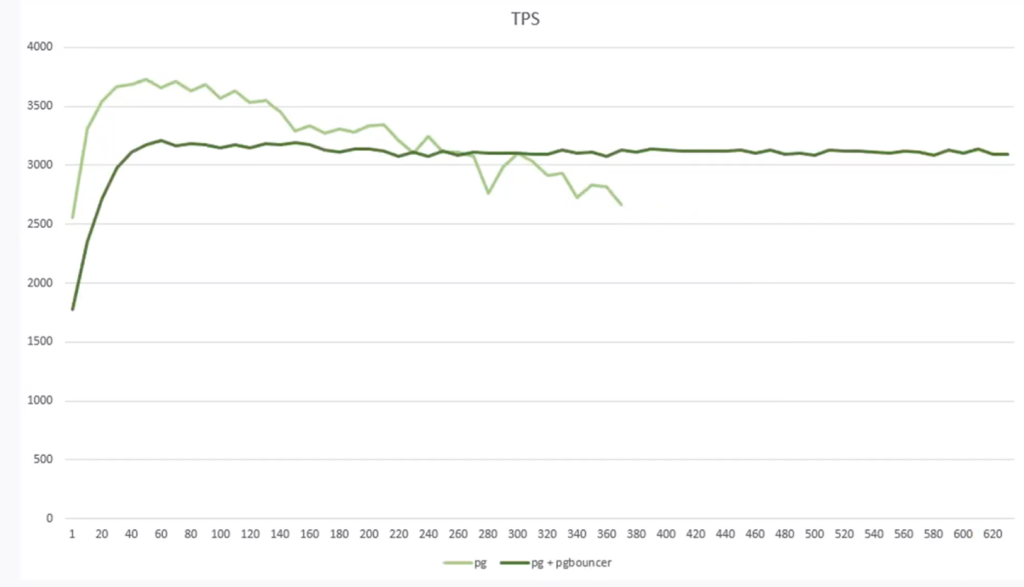
При большом количестве соединений (>300-400) или при деградации производительности имеет смысл использовать pooler.
Pooler — легковесные постоянные коннекты от бэкендов и постоянные соединения в БД.
Классические варианты:
- Pgpool II
- pg_bouncer + haproxy
- Odyssey
Pgpool II
Pgpool II — один из самых популярных инструментов
Используется встроенный механизм репликации, есть пул соединений, есть балансировщик нагрузки, обладает высокой доступностью (наблюдатель с виртуальным IP, автоматическое переключение мастера)
Излишек функционала — основная проблема производительности Pgpool2
PgBouncer
PgBouncer — пул соединений:
- легковесный — 2 Кб на соединение
- можно выбрать тип соединения: на сессию, транзакцию или каждую операцию
- онлайн-реконфигурация без сброса подключений
PgBouncer спроектирован однопоточным. Он сделан максимально простым, поэтому не масштабируем.
Функция reuseport помогает не всегда:
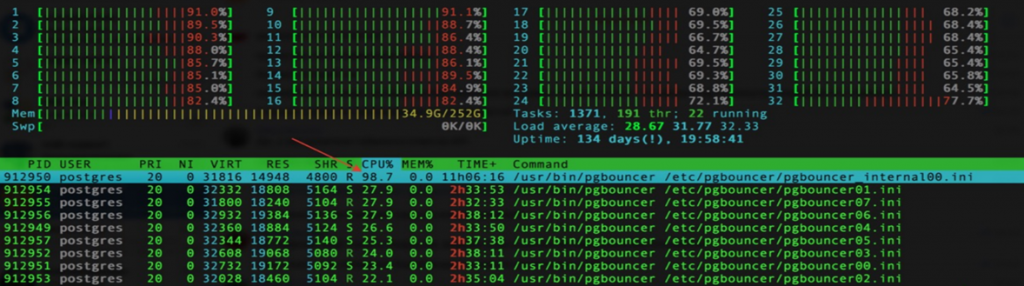
Видим поднятый каскадом PgBouncer, где у нас есть внутренний Bouncer, который по-прежнему уперт в одно ядро. В каскаде можно обойтись без внутреннего PgBouncer, но тогда connection pool будет внутри каждого процесса PgBouncer.
Внешний слой PgBouncer обычно используется для приема волны TLS-соединений. TLS-соединения – это операция, которая требует участие центрального процессора значительно больше, чем типичное перекладывание байтов из сокета в сокет. Т. е. для центрального процессора потоки данных, измеренные в байтах в секунду, не заметны. Но необходимость выполнять криптографию при TLS handshake существенна.
Сравнение PgBouncer и Pgpool II.
Odyssey
Если приложение сбросило подключение к БД, то PgBouncer продолжит выполнять тот запрос, который выполнялся. На эту проблему обращали внимание много раз, в том числе — авторы Odyssey.
Odyssey — бесплатный инструмент от Яндекса.
Другие варианты
pg agroal — высокопроизводительный пул подключений с поддержкой протокола PostgreSQL.
- Проверка подключений
- Высокая производительность
- Пул подключений
- Ограничение подключений для пользователей и баз данных
- Поддержка предварительного заполнения пула
- Удаление неактивных подключений
Не умеет работать с пятизначным номером порта.
Supavisor — репозиторий на GitHub
- Лицензия Apache 2.0
- Высокая доступность
- Буферизация подключений
- Облачная архитектура (Cloud-native)
- Поддержка многопользовательской среды (multi-tenant)
- Масштабируемость
- Балансировка нагрузки
Также в каждый язык встроены свои пулеры. Однако это не универсальный способ и имеет свои подводные камни.
Статистика использования pooler
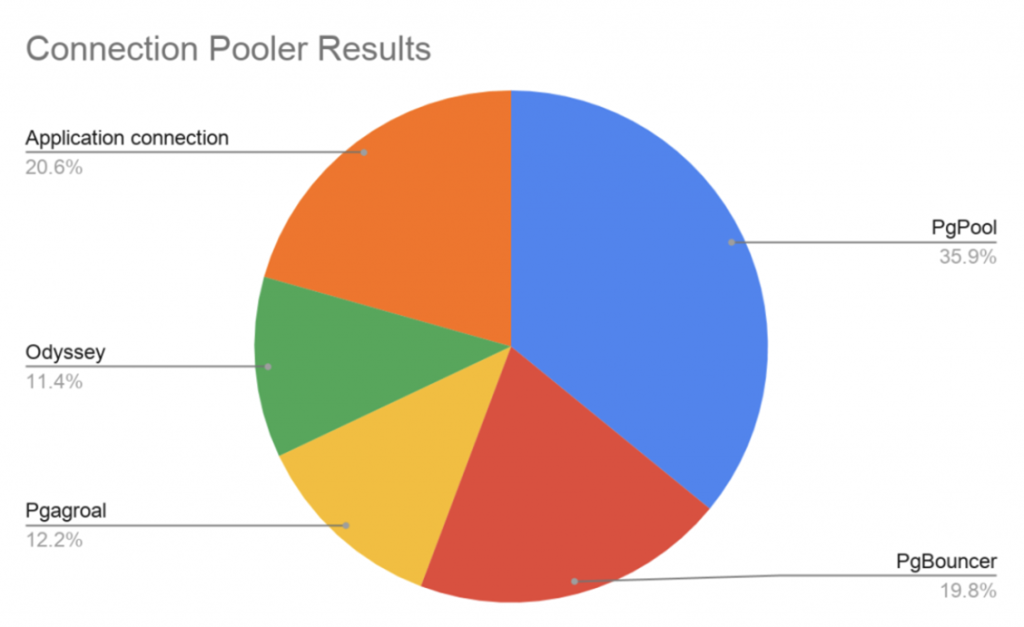
Выбор балансировщика
В зависимости от задачи и профиля нагрузки тестируем на дев стенде, помня об ограничениях, плюсах и минусах.
Обращайте внимание на:
- количество коннектов
- нагрузка на сеть/процессор
- минимизация обмена данными по сети
- уменьшение количества запросов
- чтение меньшего количества данных
- обновлять меньше данных (несколько update insert в одну транзакцию)
- уменьшение обработки на лету — хранимые процедуры
- анализ передачи данных
- сколько данных было просканировано — сколько отослано
- сколько было отослано — сколько использовано приложением
Советы:
- бэкап снимаем с secondary
- используйте каскадную репликацию
- для OLAP делайте специальную реплику, можно подключить clickhouse
- не забывайте про геораспределение нагрузки
- используйте LT-стенды (Стенд для нагрузочного тестирования: от DEV до PROD )
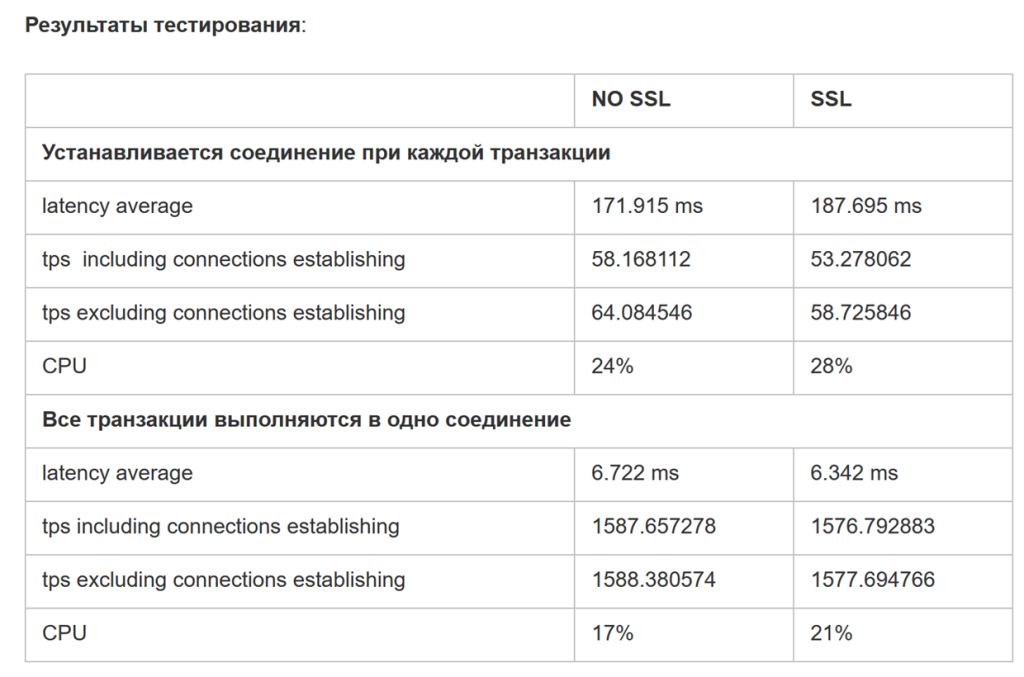
SSL и терминация трафика
Использование TLS/SSL (Secure Socket Layer) для защищенного соединения с PostgreSQL внутри закрытой периметрии (например, внутри безопасной сети или сети виртуальных машин) имеет свои плюсы и минусы.
Плюсы использования SSL:
- Шифрование данных: SSL обеспечивает шифрование данных между клиентом и сервером, что делает перехват и утечку информации более сложными для злоумышленников, даже если они имеют доступ к внутренней сети.
- Доверие и безопасность: Использование SSL помогает подтвердить подлинность сервера перед клиентом и создает доверительный канал для обмена данными. Это защищает от атак «человек посередине» (Man-in-the-Middle) и поддерживает целостность данных.
- Соответствие стандартам и нормам: В зависимости от вашей отрасли и законодательства, вам может потребоваться шифрование данных, даже если они передаются внутри закрытой сети. Использование SSL позволяет соответствовать стандартам безопасности данных.
- Защита от внутренних угроз: Внутренние угрозы, такие как злоумышленники внутри сети, могут попытаться перехватить данные или осуществить атаки на базу данных. SSL помогает уменьшить риски таких атак.
Минусы использования SSL внутри закрытой периметрии:
- Дополнительная нагрузка на производительность: Шифрование и расшифровка данных может вызвать некоторую нагрузку на производительность сервера PostgreSQL. В закрытой сети эта нагрузка может быть излишней.
- Сложность настройки: Настройка SSL требует наличия корректных сертификатов, и это может быть сложно в случае внутренних сетей. Неправильная настройка может привести к проблемам соединения.
- Увеличение сложности обслуживания: Внедрение SSL увеличивает сложность конфигурации и обслуживания базы данных. Это может потребовать дополнительных шагов при развертывании и обновлении.
- Затраты на ресурсы: Создание и управление сертификатами требует времени и ресурсов. Возможно, вам потребуется наличие собственной инфраструктуры управления сертификатами.
В целом, использование SSL внутри закрытой периметрии имеет смысл, если вы стремитесь к обеспечению дополнительного уровня безопасности, защиты данных и соответствия стандартам. Однако следует тщательно взвесить плюсы и минусы в соответствии с требованиями вашей организации и сетевой инфраструктурой.
Безопасность и СУБД: о чём надо помнить, подбирая средства защиты
Обеспечение безопасности базы данных PostgreSQL
- Безопасность на сетевом уровне
- Безопасность на транспортном уровне
- Безопасность на уровне базы данных
Балансируем нагрузку
Стоит добавить HAPROXY для балансинга нагрузки
Еще варианты балансеров:
- используем или встроенный GLB в облако или варианты:
- NGINX
Варианты балансировки
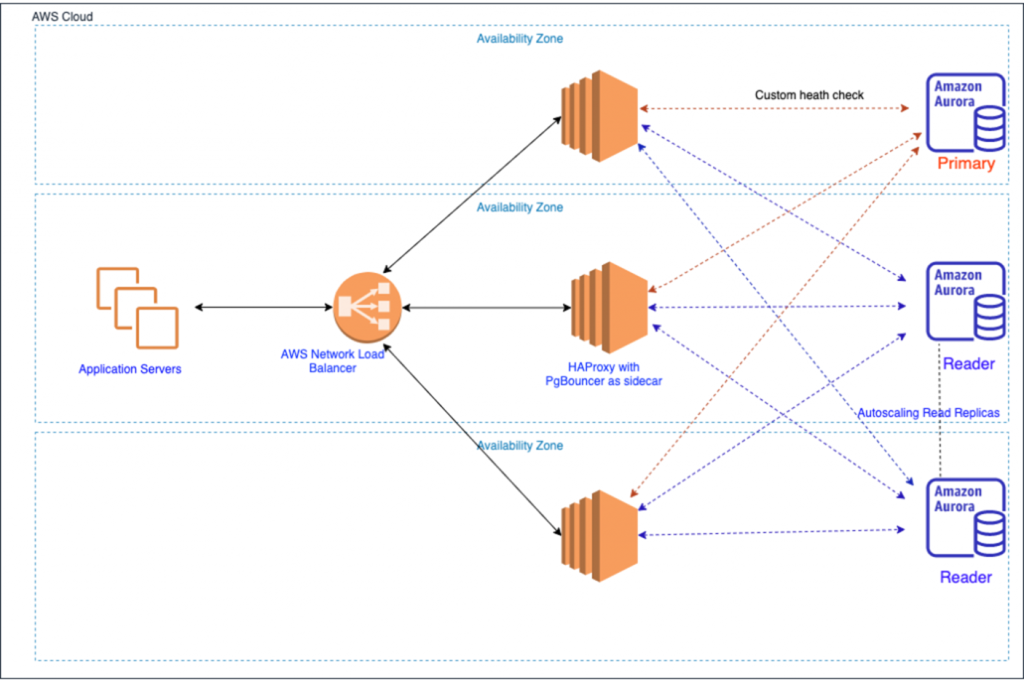
Пользователь ходит на HaProxy, который знает, где master и slave, отправляет трафик на PgBouncer, а тот на PostgreSQL.
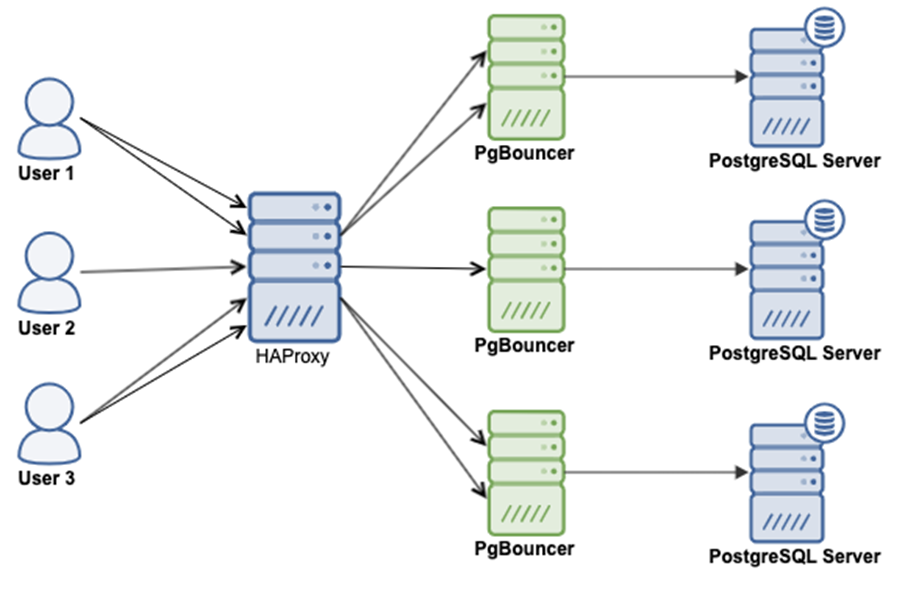
Все ходят на PgBouncer, который отправляет трафик на HaProxy. HaProxy же знает, где master и slave. PgBouncer может стать узким горлышком.
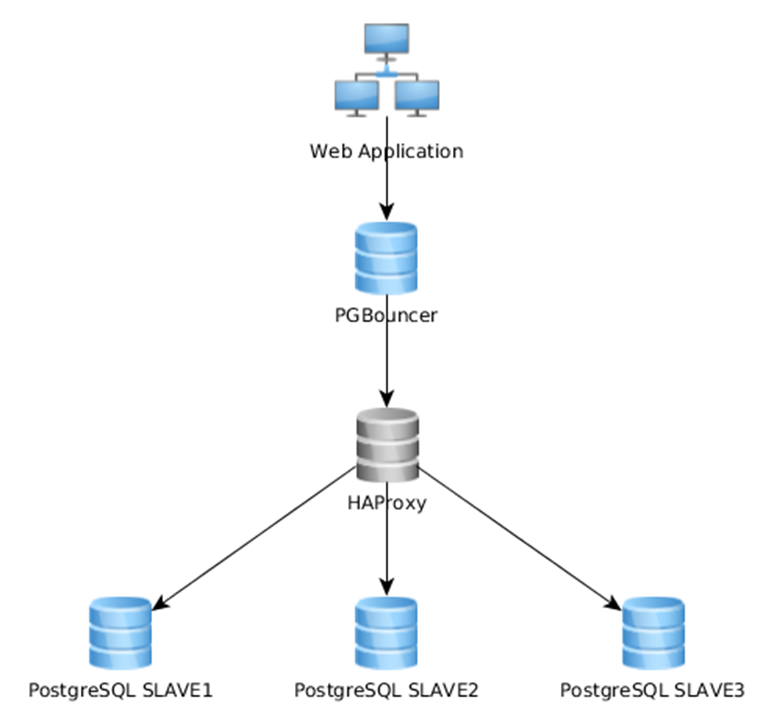
Ещё один вариант — есть глобальный load balancer. PgBouncer и HaProxy — отдельные ноды. HaProxy знает, где master и slave. PgBouncer ходит на нужную ноду. Отказоустойчивый вариант.
Практика
Развернем ВМ на 4 ядра и 16 ГБ памяти и устанавим postgres 16 версии.
Зайдем под пользователем postgres:sudo su postgresТеперь настроим config, рассчитанный в калькуляторе для нашей системы:
cat >> /etc/postgresql/16/main/postgresql.conf << EOL
shared_buffers = '4096 MB'
work_mem = '32 MB'
maintenance_work_mem = '320 MB'
huge_pages = off
effective_cache_size = '11 GB'
effective_io_concurrency = 100 # concurrent IO only really activated if OS supports posix_fadvise function
random_page_cost = 1.1 # speed of random disk access relative to sequential access (1.0)
#Monitoring
shared_preload_libraries = 'pg_stat_statements' # per statement resource usage stats
track_io_timing=on # measure exact block IO times
track_functions=pl # track execution times of pl-language procedures if any
#Replication
wal_level = replica # consider using at least 'replica'
max_wal_senders = 0
synchronous_commit = on
# Checkpointing:
checkpoint_timeout = '15 min'
checkpoint_completion_target = 0.9
max_wal_size = '1024 MB'
min_wal_size = '512 MB'
#WAL writing
wal_compression = on
wal_buffers = -1 # auto-tuned by Postgres till maximum of segment size (16MB by default)
wal_writer_delay = 200ms
wal_writer_flush_after = 1MB
#Background writer
bgwriter_delay = 200ms
bgwriter_lru_maxpages = 100
bgwriter_lru_multiplier = 2.0
bgwriter_flush_after = 0
# Parallel queries:
max_worker_processes = 4
max_parallel_workers_per_gather = 2
max_parallel_maintenance_workers = 2
max_parallel_workers = 4
parallel_leader_participation = on
#Advanced features
enable_partitionwise_join = on
enable_partitionwise_aggregate = on
jit = on
max_slot_wal_keep_size = '1000 MB'
track_wal_io_timing = on
maintenance_io_concurrency = 100
EOLПерезапуск кластера:
pg_ctlcluster 16 main stop && pg_ctlcluster 16 main startУстановим мини версию моей базы данных с тайскими перевозками:
cd ~ && wget https://storage.googleapis.com/thaibus/thai_small.tar.gz && tar -xf thai_small.tar.gz && psql < thai.sqlПодготовим нагрузочный скрипт (в установленной базе выбираем любую поездку):
cat > ~/workload.sql << EOL
\set r random(1, 5000000)
SELECT id, fkRide, fio, contact, fkSeat FROM book.tickets WHERE id = :r;
EOLТестируем:
/usr/lib/postgresql/16/bin/pgbench -c 8 -j 4 -T 10 -f ~/workload.sql -n -U postgres thai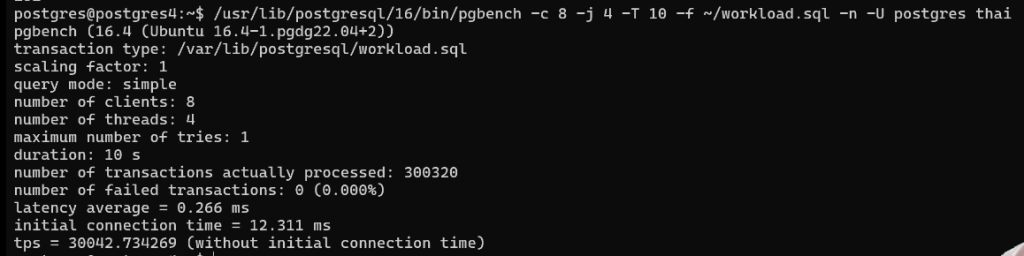
Теперь развернем pg_bouncer:
sudo DEBIAN_FRONTEND=noninteractive apt install -y pgbouncerСмотрим статус:
sudo systemctl status pgbouncer
Теперь останавливаем:
sudo systemctl stop pgbouncer Пропишем config файл (подключаться будем только к БД thai, logfile, pidfile, listen_port, admin_users):
cat > temp.cfg << EOF
[databases]
thai = host=127.0.0.1 port=5432 dbname=thai
[pgbouncer]
logfile = /var/log/postgresql/pgbouncer.log
pidfile = /var/run/postgresql/pgbouncer.pid
listen_addr = *
listen_port = 6432
#auth_type = md5
auth_type = scram-sha-256
auth_file = /etc/pgbouncer/userlist.txt
admin_users = admindb
EOF
cat temp.cfg | sudo tee -a /etc/pgbouncer/pgbouncer.iniНастраиваем пароли:
cat > temp2.cfg << EOF
"admindb" "admin123#"
"admindb2" "md5a1edc6f635a68ce9926870fe752e8f2b"
"postgres" "admin123#"
"postgres2" "SCRAM-SHA-256$4096:eM1ToRH8QOewbDddWnxzBQ==$ktPLPRkEPtMr1epwtJv1HxVHAxjsM+KEbLaW7loiBQs=:UMtetDFOi30NB56aX4JBT3lXudOClkANX02Xxhjjg1U="
EOF
cat temp2.cfg | sudo tee -a /etc/pgbouncer/userlist.txtСоздадим трех пользователей, а ещё одному сменим пароль:
sudo -u postgres psql -c "ALTER USER postgres WITH PASSWORD 'admin123#';";
sudo -u postgres psql -c "create user postgres2 with password 'admin123#';";
sudo -u postgres psql -c "create user admindb with password 'admin123#';";
sudo -u postgres psql -c "create user admindb2 with password 'md5a1edc6f635a68ce9926870fe752e8f2b';";Просмотрим pg_shadow:
sudo -u postgres psql -c "select usename,passwd from pg_shadow;"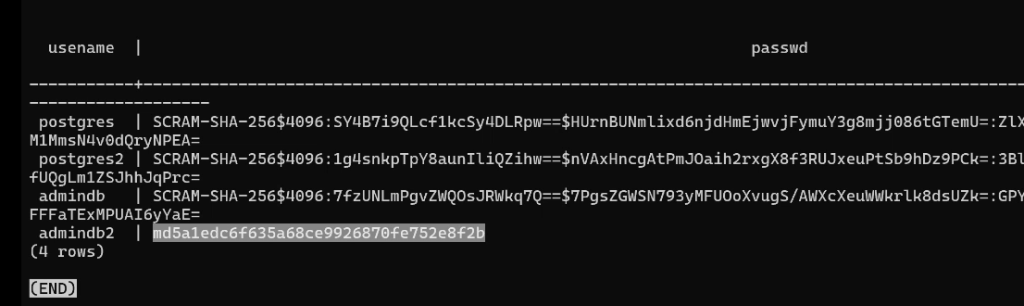
Можно отдельно просмотреть хэши по шифрованию:
sudo -u postgres psql -c "select sha256('pass');"
sudo -u postgres psql -c "select md5 ('pass');"
Записываем в .pgpass, чтобы не вводить пароль для доступа к БД:
echo "localhost:5432:thai:postgres:admin123#" | sudo tee -a /var/lib/postgresql/.pgpass && sudo chmod 600 /var/lib/postgresql/.pgpasssudo chown postgres:postgres /var/lib/postgresql/.pgpass
Сменим права на пользователя postgres:
sudo su postgresЗаходим в базу postgres:
psql -h localhost -U postgres
Требуется пароль
Теперь заходим в базу thai:
psql -h localhost -U postgres -d thai
Пароль не нужен, так как в .pgpass файле указано имя пользователя, база и пароль, с которым этот пользователь заходит в эту базу. Проблема заключается в том, что пароль в .pgpass не шифруется.
Настраиваем включение pg_bouncer после перезапуска сервера:
sudo systemctl enable pgbouncer
Теперь запускаем:
sudo systemctl start pgbouncerСмотрим статус:
sudo systemctl status pgbouncer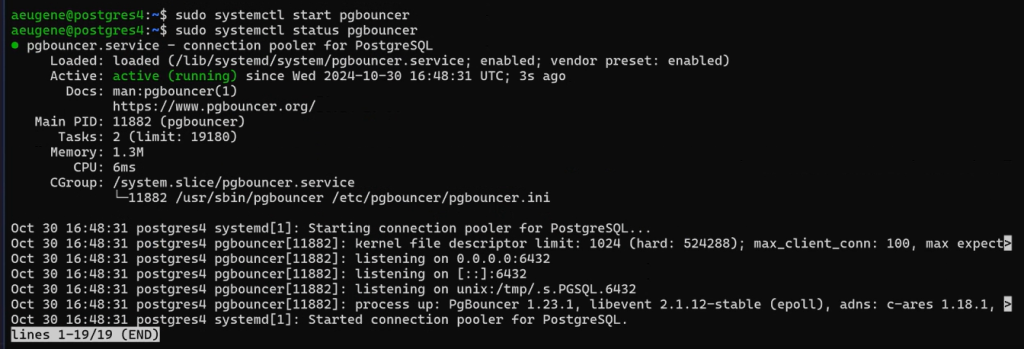
При запуске с ключом -d запускается в качестве демона, а не сервиса.
Подключаемся:
sudo -u postgres psql -p 6432 -h 127.0.0.1 -d thai -U postgres
Требуется пароль, так как подключаемся к pg_bouncer.
Теперь мы находимся в pg_bouncer, который подключен к БД thai.
Обратите внимание, что если в файле pg_hba.conf указать пересекающиеся диапазоны для разных методов шифрования, то приоритет будет иметь scram-sha-256. Просмотр файла:
! nano /etc/postgresql/16/main/pg_hba.conf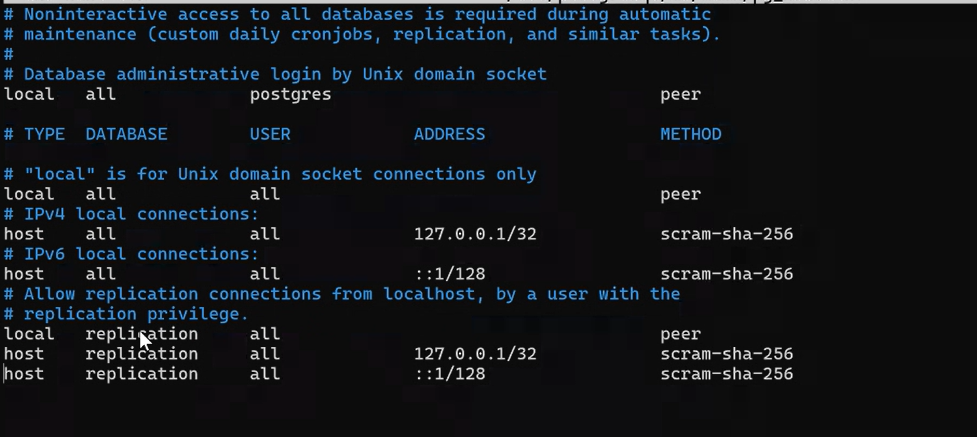
Проверим файл pgbouncer.ini:
! nano /etc/pgbouncer/pgbouncer.ini

Pg_bouncer умеет работать в трех режимах — транзакция, сессия, statement. При простейшем трафике (клиент подключился, отправил запрос, отключился) разницы нет. Она начинает проявляться на долгих транзакциях и запросах.

Зайти в администрирование pg_bouncer (пользователь должен быть указан в user_list и списке админов):
psql -p 6432 -h 127.0.0.1 -d pgbouncer -U admindb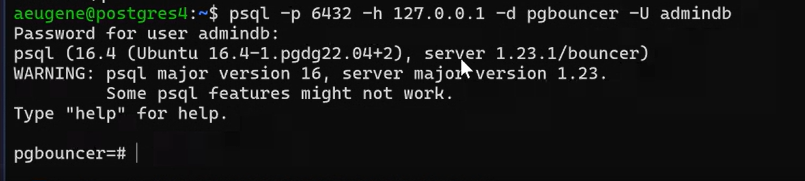
Просмотр текущим клиентов:
show clients;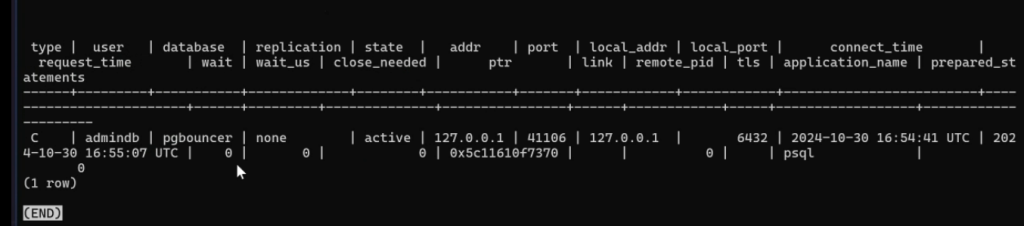
Протестируем режим паузы:
pause thai;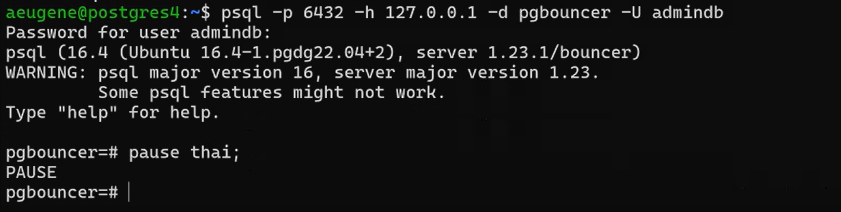
Заходим в новом терминале:
/usr/lib/postgresql/16/bin/pgbench -c 8 -j 4 -T 10 -f ~/workload.sql -n -U postgres -p 6432 -h localhost thai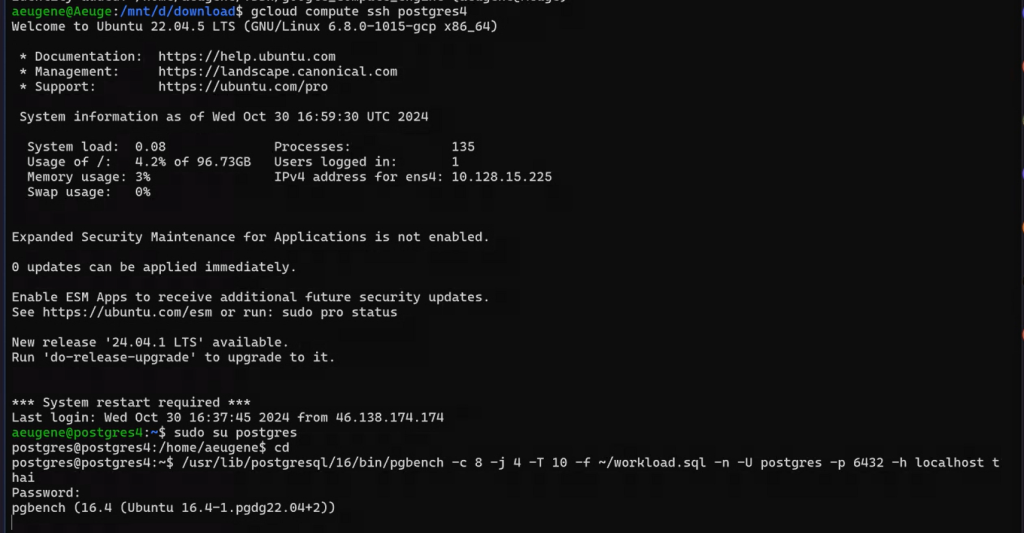
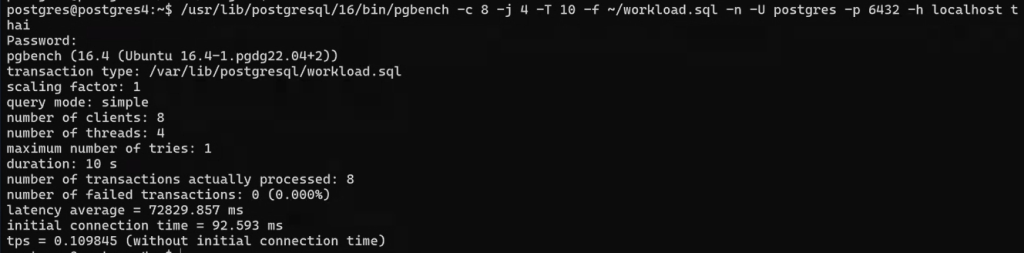
Посмотрим подключения:
show clients;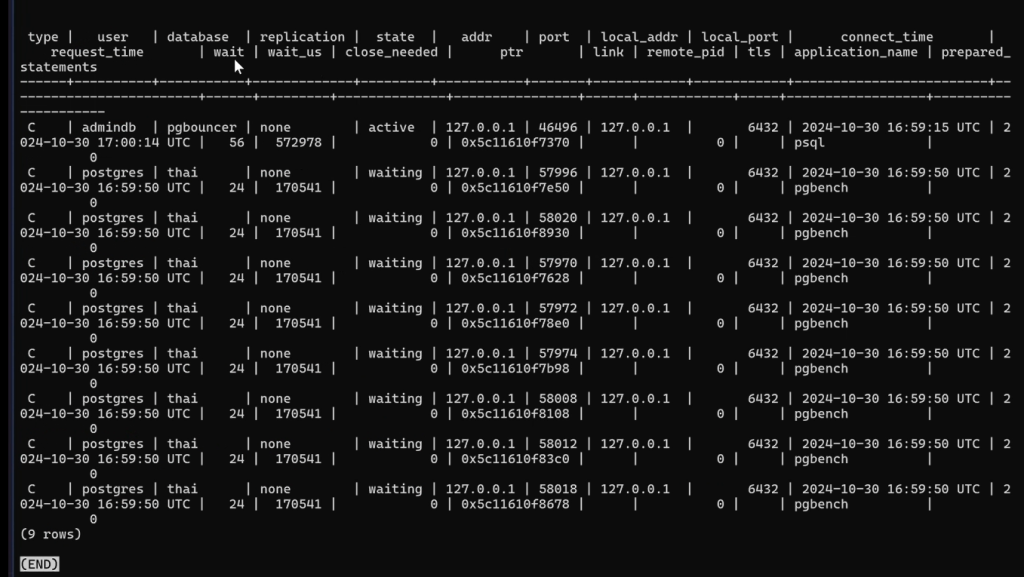
Обратим внимание, что производительность падает почти в два раза при использовании pg_bouncer.
Запустим соединение:
resume thai;Подключимся во втором терминале:

Просмотрим htop:

Pg_bouncer забирает целое ядро и снижает производительность.
Также есть разница при подключении через unix socket и localhost — unix socket быстрее.
idle VS idle in transaction
Во избежание проблем с открытием соединений, существует практика долгого поддержания открытой транзакции.
Открытый урок на эту тему:
Скрипты на Питоне выложены на гитхаб
Checklist
Учитываем количество коннектов
Если больше 500 соединений — выбираем пулер
Обязательно тестирование на вашем железе, объеме и профиле нагрузки
Учитываем рекомендации по сетевому обмену
Совместно с СБ выбираем модель SSL и терминации трафика
Выбираем модель балансинга в соответствии с вашим железом и бизнес задачами
Помним о проблемах долгих соединений
Информацию о следующих открытых уроках можно получить на сайте проекта или можно подписаться на новостной канал в TG.
Добавить комментарий